tl;dr
Zasadniczo nie dlatego, że dosłownie mieszasz dwie warstwy i łączysz je ze sobą. Muszę przyznać, że widzę, jak często się to zdarza i zależy to trochę od poziomu szybkiej wygranej Twojego projektu, ale możemy stwierdzić, że nie jest on zgodny z Zasadą pojedynczej odpowiedzialności SOLID.
Zabawna część:nie ogranicza się to do przeglądania modeli w MVC, w rzeczywistości jest to kwestia oddzielenia starych dobrych warstw danych, biznesu i interfejsu użytkownika . Zilustruję to później, ale na razie; pamiętaj, że dotyczy to MVC, ale ma również zastosowanie do wielu innych wzorców projektowych.
Zacznę od wskazania kilku ogólnych pojęć, które można zastosować, a później przybliżę niektóre rzeczywiste scenariusze i przykłady.
Zastanówmy się nad kilkoma zaletami i wadami niemieszania warstw.
Ile to będzie Cię kosztować
Zawsze jest jakiś haczyk, podsumuję je, wyjaśnię później i pokażę, dlaczego zwykle nie mają zastosowania
- zduplikowany kod
- dodaje dodatkową złożoność
- dodatkowy hit wydajności
Co zyskasz
Zawsze jest wygrana, podsumuję, wyjaśnię później i pokażę, dlaczego to ma sens
- niezależna kontrola warstw
Koszty
zduplikowany kod
Będziesz potrzebować dodatkowej klasy, która prawdopodobnie jest dokładnie taka sama jak druga.
To jest nieprawidłowy argument. Różne warstwy mają dobrze zdefiniowany inny cel. W związku z tym nieruchomości, które znajdują się w jednej warstwie, mają inny cel niż nieruchomość w drugiej - nawet jeśli mają taką samą nazwę!
Na przykład:
To się nie powtarza:
public class FooViewModel
{
public string Name {get;set;}
}
public class DomainModel
{
public string Name {get;set;}
}
Z drugiej strony, dwukrotne zdefiniowanie mapowania jest powtarzanie się:
public void Method1(FooViewModel input)
{
//duplicate code: same mapping twice, see Method2
var domainModel = new DomainModel { Name = input.Name };
//logic
}
public void Method2(FooViewModel input)
{
//duplicate code: same mapping twice, see Method1
var domainModel = new DomainModel { Name = input.Name };
//logic
}
Naprawdę, prawda? Jeśli zaczniesz kodować, ponad 99% modeli będzie się nakładać. Napicie się kawy zajmie więcej czasu;-)
Tak, dlatego musisz przeprowadzić test jednostkowy swojego mapowania (i pamiętaj, nie powtarzaj mapowania).
dodaje dodatkową złożoność
Nie. Dodaje dodatkową warstwę, co komplikuje sprawę. Nie dodaje złożoności.
Mój mądry przyjaciel powiedział kiedyś tak:
Nie tylko on posługuje się taką definicją, różnica polega na przewidywalności, która ma rzeczywisty związek z entropią , miara chaosu.
Ogólnie:wzory nie dodają złożoności. Istnieją, aby pomóc Ci zmniejszyć złożoność . Są rozwiązaniami dobrze znanych problemów. Oczywiście źle zaimplementowany wzorzec nie pomaga, dlatego przed zastosowaniem wzorca należy zrozumieć problem. Ignorowanie problemu też nie pomaga; dodaje tylko dług techniczny, który trzeba kiedyś spłacić.
Dodanie warstwy daje dobrze zdefiniowane zachowanie, które ze względu na oczywiste dodatkowe mapowanie będzie (nieco) bardziej skomplikowane. Mieszanie warstw do różnych celów prowadzi do nieprzewidywalnych skutków ubocznych po wprowadzeniu zmiany. Zmiana nazwy kolumny bazy danych spowoduje niezgodność w wyszukiwaniu klucza/wartości w interfejsie użytkownika, co spowoduje wykonanie nieistniejącego wywołania interfejsu API. Teraz pomyśl o tym i o tym, jak to się odniesie do twoich wysiłków związanych z debugowaniem i kosztami konserwacji.
dodatkowy hit wydajności
Tak, dodatkowe mapowanie spowoduje zużycie dodatkowej mocy procesora. To jednak (chyba że masz Raspberry Pi podłączone do zdalnej bazy danych) jest znikome w porównaniu do pobierania danych z bazy danych. Konkluzja:jeśli to jest problem:użyj buforowania.
Zwycięstwo
niezależna kontrola warstw
Co to oznacza?
Dowolna kombinacja tego (i nie tylko):
- tworzenie przewidywalnego systemu
- zmiana logiki biznesowej bez wpływu na interfejs użytkownika
- zmiana bazy danych bez wpływu na logikę biznesową
- zmiana interfejsu użytkownika bez wpływu na bazę danych
- możliwość zmiany rzeczywistego magazynu danych
- całkowita niezależna funkcjonalność, izolowane, dobrze testowalne zachowanie i łatwe w utrzymaniu
- radzić sobie ze zmianami i wzmacniać biznes
W skrócie:jesteś w stanie dokonać zmiany, modyfikując dobrze zdefiniowany fragment kodu, nie martwiąc się o nieprzyjemne skutki uboczne.
uwaga:biznesowe środki zaradcze!
Nadejdzie zmiana:wydawanie bilionów dolarów rocznie nie może tak po prostu przejść.
Cóż, to miłe. Ale spójrz na to, jako programista; dzień, w którym nie popełniasz błędów, to dzień, w którym przestajesz pracować. To samo dotyczy wymagań biznesowych.
śmieszny fakt; entropia oprogramowania
To może być najtrudniejsze, ponieważ jest tutaj dobry punkt. Jeśli tworzysz coś do jednorazowego użytku, prawdopodobnie w ogóle nie jest w stanie poradzić sobie ze zmianą i i tak musisz to przebudować, pod warunkiem faktycznie zamierzasz go ponownie wykorzystać. Niemniej jednak we wszystkich innych sprawach:„zmiana nadejdzie” , więc po co komplikować zmianę? I pamiętaj, że prawdopodobnie pominięcie warstw w minimalistycznym narzędziu lub usłudze zwykle umieszcza warstwę danych bliżej interfejsu (użytkownika). Jeśli masz do czynienia z API, Twoja implementacja będzie wymagała aktualizacji wersji, która musi zostać rozpowszechniona wśród wszystkich Twoich klientów. Czy możesz to zrobić podczas jednej przerwy na kawę?
Czy Twoja praca „na razie” ? Żartuję;-) ale; kiedy zamierzasz to naprawić? Prawdopodobnie wtedy, gdy zmusza Cię do tego dług techniczny. W tamtym czasie kosztowało Cię to więcej niż ta krótka przerwa na kawę.
Tak to jest! Ale to nie znaczy, że nie powinieneś naprawiać literówek. Lub że każda zastosowana reguła biznesowa może być wyrażona jako suma rozszerzeń lub że nie możesz naprawiać uszkodzonych rzeczy. Lub jak podaje Wikipedia:
co faktycznie sprzyja separacji warstw.
A teraz kilka typowych scenariuszy:
ASP.NET MVC
Ponieważ tego właśnie używasz w swoim prawdziwym pytaniu:
Podam przykład. Wyobraź sobie następujący model widoku i model domeny:
notatka :dotyczy to również innych typów warstw, aby wymienić tylko kilka:DTO, DAO, Entity, ViewModel, Domain, itp.
public class FooViewModel
{
public string Name {get; set;}
//hey, a domain model class!
public DomainClass Genre {get;set;}
}
public class DomainClass
{
public int Id {get; set;}
public string Name {get;set;}
}
Tak więc gdzieś w kontrolerze wypełniasz FooViewModel i przekaż go do swojego widoku.
Rozważ teraz następujące scenariusze:
1) Zmienia się model domeny.
W takim przypadku prawdopodobnie będziesz musiał również dostosować widok, jest to zła praktyka w kontekście oddzielenia obaw.
Jeśli oddzieliłeś ViewModel od DomainModel, wystarczy niewielka zmiana w mapowaniach (ViewModel => DomainModel (i z powrotem)).
2) DomainClass ma zagnieżdżone właściwości, a Twój widok wyświetla tylko „GenreName”
Widziałem, jak to się nie udaje w prawdziwych scenariuszach na żywo.
W tym przypadku częstym problemem jest to, że użycie @Html.EditorFor doprowadzi do danych wejściowych dla zagnieżdżonego obiektu. Może to obejmować Id i inne wrażliwe informacje. Oznacza to wyciek szczegółów implementacji! Twoja rzeczywista strona jest powiązana z Twoim modelem domeny (który prawdopodobnie jest gdzieś powiązany z Twoją bazą danych). Po tym kursie będziesz tworzyć hidden wejścia. Jeśli połączysz to z powiązaniem modelu po stronie serwera lub automapperem, coraz trudniej będzie zablokować manipulację ukrytym Id za pomocą narzędzi takich jak firebug lub zapomnienie o ustawieniu atrybutu w Twojej usłudze, udostępni go w Twoim widoku.
Chociaż jest możliwe, a może nawet łatwe, zablokowanie niektórych z tych pól, ale im więcej masz zagnieżdżonych obiektów Domain/Data, tym trudniejsze będzie prawidłowe wykonanie tej części. I; co jeśli „używasz” tego modelu domeny w wielu widokach? Czy będą się zachowywać tak samo? Pamiętaj też, że możesz chcieć zmienić swój model domeny z powodu, który niekoniecznie dotyczy widoku. Dlatego przy każdej zmianie w DomainModel należy mieć świadomość, że może wpływają na widok(i) i aspekty bezpieczeństwa kontrolera.
3) W ASP.NET MVC często używa się atrybutów walidacji.
Czy naprawdę chcesz, aby Twoja domena zawierała metadane dotyczące Twoich wyświetleń? Lub zastosować logikę widoku do warstwy danych? Czy weryfikacja wyświetleń jest zawsze taka sama jak weryfikacja domeny? Czy zawiera te same pola (a może niektóre z nich są konkatenacją)? Czy ma tę samą logikę walidacji? Czy używasz aplikacji między modelami domen? itp.
Myślę, że to jasne, że to nie jest droga do obrania.
4) Więcej
Mogę podać więcej scenariuszy, ale to tylko kwestia gustu, co jest bardziej atrakcyjne. Mam tylko nadzieję, że w tym momencie zrozumiesz, o co chodzi :) Mimo to obiecałem ilustrację:
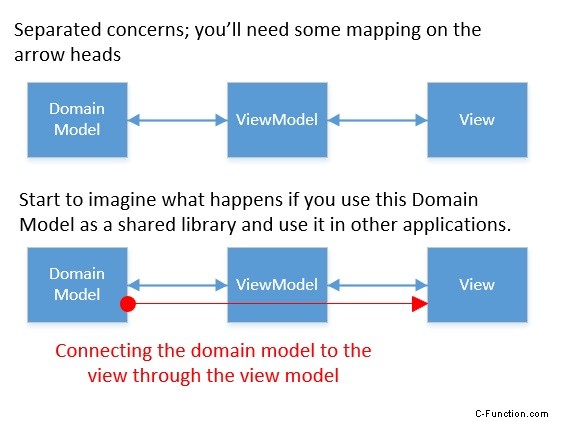
Teraz, dla naprawdę brudnych i szybkich wygranych będzie działać, ale nie sądzę, że powinieneś tego chcieć.
Zbudowanie modelu widoku, który zwykle jest w ponad 80% podobny do modelu domeny, wymaga nieco więcej wysiłku. To może wydawać się niepotrzebnym mapowaniem, ale kiedy pojawi się pierwsza różnica pojęciowa, przekonasz się, że było to warte wysiłku :)
Jako alternatywę proponuję następującą konfigurację dla ogólnego przypadku:
- utwórz model widoku
- utwórz model domeny
- utwórz model danych
- użyj biblioteki takiej jak
automapperaby utworzyć mapowanie z jednego na drugie (pomoże to zmapowaćFoo.FooPropdoOtherFoo.FooProp)
Korzyści to m.in. jeśli utworzysz dodatkowe pole w jednej z tabel bazy danych, nie wpłynie to na Twój widok. Może uderzyć w warstwę biznesową lub mapowania, ale na tym się zatrzyma. Oczywiście w większości przypadków chcesz również zmienić widok, ale w tym przypadku nie potrzebujesz do. Dzięki temu problem jest izolowany w jednej części kodu.
Web API / warstwa danych / DTO
Najpierw uwaga:oto fajny artykuł o tym, jak DTO (który nie jest modelem widoku) można pominąć w niektórych scenariuszach - z czym moja pragmatyczna strona w pełni się zgadza;-)
Kolejny konkretny przykład tego, jak to zadziała w scenariuszu Web-API / ORM (EF):
Tutaj jest to bardziej intuicyjne, zwłaszcza gdy klient jest stroną trzecią, jest mało prawdopodobne, że Twój model domeny pasuje do implementacji Twojego konsumenta, dlatego model widoku jest bardziej prawdopodobne, że będzie w pełni samowystarczalny.
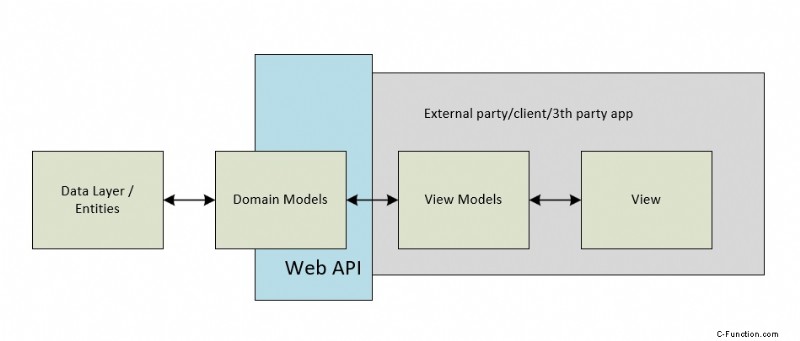
notatka :Nazwa „model domeny” jest czasami mieszana z DTO lub „Model”
Należy pamiętać, że w Web (lub HTTP lub REST) API; komunikacja jest często realizowana przez obiekt transferu danych (DTO), który jest rzeczywistą "rzeczą", która jest ujawniana w punktach końcowych HTTP.
Więc gdzie powinniśmy umieścić te DTO, możesz zapytać. Czy są między modelem domeny a modelami widoku? No tak; widzieliśmy już, że traktowanie ich jako viewmodel byłoby to trudne, ponieważ konsument prawdopodobnie zaimplementuje spersonalizowany widok.
Czy DTO będzie w stanie zastąpić domainmodels? czy mają powód, by istnieć samodzielnie? Ogólnie koncepcja separacji miałaby zastosowanie do DTO's i domainmodels również. Ale z drugiej strony:możesz zadać sobie pytanie (i tutaj jestem trochę pragmatyczny;); czy w domenie jest wystarczająco dużo logiki, aby jawnie zdefiniować domainlayer? ? Myślę, że zauważysz, że jeśli Twoja usługa będzie coraz mniejsza, rzeczywista logic , który jest częścią domainmodels , również maleje i może zostać pominięty razem, a otrzymasz:
EF/(ORM) Entities DTO/DomainModel ↔ Consumers
zastrzeżenie / uwaga
Jak stwierdził @mrjoltcola:należy również pamiętać o przeprojektowaniu komponentów. Jeśli żadne z powyższych nie ma zastosowania, a użytkownikom/programistom można ufać, dobrze jest iść. Należy jednak pamiętać, że łatwość konserwacji i możliwość ponownego wykorzystania zmniejszą się z powodu mieszania DomainModel/ViewModel.
Opinie są różne, od najlepszych praktyk technicznych po osobiste preferencje.
Nie ma nic złego z wykorzystaniem obiektów domeny w modelach widoku, a nawet przy użyciu obiektów domeny jako modelu, a wiele osób to robi. Niektórzy mocno myślą o tworzeniu modeli widoków dla każdego widoku, ale osobiście uważam, że wiele aplikacji jest nadmiernie zaprojektowanych przez programistów, którzy uczą się i powtarzają jedno podejście, z którym czują się komfortowo. Prawda jest taka, że istnieje kilka sposobów na osiągnięcie celu przy użyciu nowszych wersji ASP.NET MVC.
Największym ryzykiem, gdy używasz wspólnej klasy domeny dla modelu widoku oraz warstwy biznesowej i trwałości, jest wstrzyknięcie modelu. Dodanie nowych właściwości do klasy modelu może ujawnić te właściwości poza granicami serwera. Atakujący może potencjalnie zobaczyć właściwości, których nie powinien widzieć (serializacja) i zmienić wartości, których nie powinien zmieniać (modele wiążące).
Aby zabezpieczyć się przed wstrzyknięciem, stosuj bezpieczne praktyki, które są istotne dla Twojego ogólnego podejścia. Jeśli planujesz używać obiektów domeny, upewnij się, że korzystasz z białych lub czarnych list (włączenia/wykluczenia) w kontrolerze lub za pośrednictwem adnotacji modelu binder. Czarne listy są wygodniejsze, ale leniwi programiści piszący przyszłe poprawki mogą o nich zapomnieć lub nie być ich świadomym. Białe listy ([Bind(Include=...)] są obowiązkowe, wymagają uwagi przy dodawaniu nowych pól, więc działają jak wbudowany model widoku.
Przykład:
[Bind(Exclude="CompanyId,TenantId")]
public class CustomerModel
{
public int Id { get; set; }
public int CompanyId { get; set; } // user cannot inject
public int TenantId { get; set; } // ..
public string Name { get; set; }
public string Phone { get; set; }
// ...
}
lub
public ActionResult Edit([Bind(Include = "Id,Name,Phone")] CustomerModel customer)
{
// ...
}
Pierwszy przykład to dobry sposób na wymuszenie bezpieczeństwa wielodostępnego w całej aplikacji. Drugi przykład pozwala dostosować każdą akcję.
Bądź konsekwentny w swoim podejściu i jasno udokumentuj podejście zastosowane w twoim projekcie dla innych programistów.
Zalecam, aby zawsze używać modeli widoku do funkcji związanych z logowaniem/profilem, aby zmusić się do „zorganizowania” pól między kontrolerem sieci a warstwą dostępu do danych w ramach ćwiczenia bezpieczeństwa.