Tot nu toe heb ik twee strategieën gebruikt voor de sommatie van een std::vector. Eerst deed ik de hele wiskunde in één thread (Single Threaded:Sommatie van een vector); ten tweede deelden meerdere threads dezelfde variabele voor het resultaat (Multithreaded:Sommatie van een vector). Vooral de tweede strategie was uiterst naïef. In dit bericht zal ik mijn kennis van beide berichten toepassen. Mijn doel is dat de thread hun sommatie zo onafhankelijk mogelijk van elkaar zal uitvoeren en daarom de synchronisatie-overhead zal verminderen.
Om de threads onafhankelijk te laten werken en dus de synchronisatie te minimaliseren, heb ik een paar ideeën in mijn hoofd. Lokale variabelen, thread-local data maar ook taken zouden moeten werken. Nu ben ik benieuwd.
Mijn strategie
Mijn strategie blijft hetzelfde. Net als in mijn laatste bericht gebruik ik mijn desktop-pc met vier kernen en GCC en mijn laptop met twee kernen en cl.exe. Ik lever de resultaten zonder en met maximale optimalisatie. Voor de details, kijk hier:Thread-safe initialisatie van een singleton.
Lokale variabelen
Omdat elke thread een lokale sommatievariabele heeft, kan deze zijn werk doen zonder synchronisatie. Het is alleen nodig om de lokale sommatievariabelen op te sommen. De toevoeging van de lokale resultaten is een kritische sectie die moet worden beschermd. Dit kan op verschillende manieren. Een korte opmerking vooraf. Aangezien er slechts vier toevoegingen plaatsvinden, maakt het vanuit prestatieperspectief niet zoveel uit welke synchronisatie ik zal gebruiken. Maar in plaats van mijn opmerking, zal ik een std::lock_guard en een atoom gebruiken met sequentiële consistentie en ontspannen semantiek.
std::lock_guard
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | // localVariable.cpp
#include <mutex>
#include <chrono>
#include <iostream>
#include <random>
#include <thread>
#include <utility>
#include <vector>
constexpr long long size= 100000000;
constexpr long long firBound= 25000000;
constexpr long long secBound= 50000000;
constexpr long long thiBound= 75000000;
constexpr long long fouBound= 100000000;
std::mutex myMutex;
void sumUp(unsigned long long& sum, const std::vector<int>& val, unsigned long long beg, unsigned long long end){
unsigned long long tmpSum{};
for (auto i= beg; i < end; ++i){
tmpSum += val[i];
}
std::lock_guard<std::mutex> lockGuard(myMutex);
sum+= tmpSum;
}
int main(){
std::cout << std::endl;
std::vector<int> randValues;
randValues.reserve(size);
std::mt19937 engine;
std::uniform_int_distribution<> uniformDist(1,10);
for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine));
unsigned long long sum{};
auto start = std::chrono::system_clock::now();
std::thread t1(sumUp,std::ref(sum),std::ref(randValues),0,firBound);
std::thread t2(sumUp,std::ref(sum),std::ref(randValues),firBound,secBound);
std::thread t3(sumUp,std::ref(sum),std::ref(randValues),secBound,thiBound);
std::thread t4(sumUp,std::ref(sum),std::ref(randValues),thiBound,fouBound);
t1.join();
t2.join();
t3.join();
t4.join();
std::chrono::duration<double> dur= std::chrono::system_clock::now() - start;
std::cout << "Time for addition " << dur.count() << " seconds" << std::endl;
std::cout << "Result: " << sum << std::endl;
std::cout << std::endl;
}
|
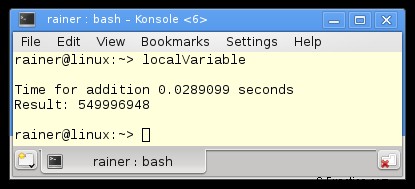
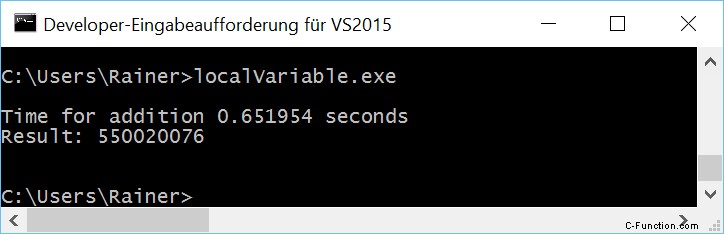
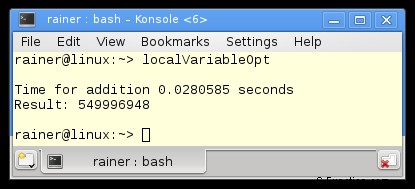
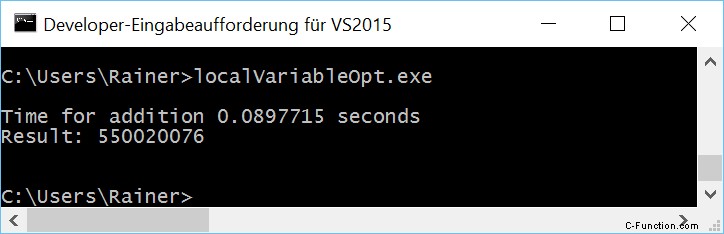
Lijn 25 en 26 zijn de belangrijke lijnen. Hier worden de lokale sommatieresultaten tmpSum toegevoegd aan de globale som. Wat is precies de plek waar de voorbeelden met de lokale variabelen zullen variëren?
Zonder optimalisatie
Maximale optimalisatie
Atoomoperaties met sequentiële consistentie
Mijn eerste optimalisatie is om de door een std::lock_guard beschermde globale sommatiesomvariabele te vervangen door een atomaire.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | // localVariableAtomic.cpp
#include <atomic>
#include <chrono>
#include <iostream>
#include <random>
#include <thread>
#include <utility>
#include <vector>
constexpr long long size= 100000000;
constexpr long long firBound= 25000000;
constexpr long long secBound= 50000000;
constexpr long long thiBound= 75000000;
constexpr long long fouBound= 100000000;
void sumUp(std::atomic<unsigned long long>& sum, const std::vector<int>& val, unsigned long long beg, unsigned long long end){
unsigned int long long tmpSum{};
for (auto i= beg; i < end; ++i){
tmpSum += val[i];
}
sum+= tmpSum;
}
int main(){
std::cout << std::endl;
std::vector<int> randValues;
randValues.reserve(size);
std::mt19937 engine;
std::uniform_int_distribution<> uniformDist(1,10);
for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine));
std::atomic<unsigned long long> sum{};
auto start = std::chrono::system_clock::now();
std::thread t1(sumUp,std::ref(sum),std::ref(randValues),0,firBound);
std::thread t2(sumUp,std::ref(sum),std::ref(randValues),firBound,secBound);
std::thread t3(sumUp,std::ref(sum),std::ref(randValues),secBound,thiBound);
std::thread t4(sumUp,std::ref(sum),std::ref(randValues),thiBound,fouBound);
t1.join();
t2.join();
t3.join();
t4.join();
std::chrono::duration<double> dur= std::chrono::system_clock::now() - start;
std::cout << "Time for addition " << dur.count() << " seconds" << std::endl;
std::cout << "Result: " << sum << std::endl;
std::cout << std::endl;
}
|
Zonder optimalisatie
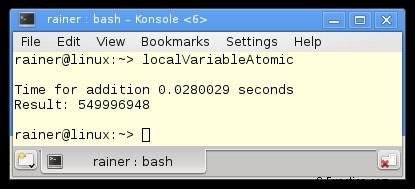
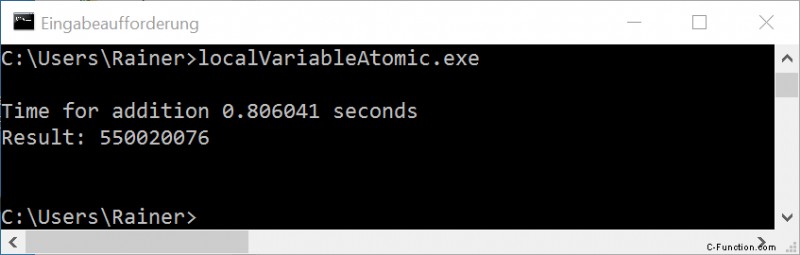
Maximale optimalisatie
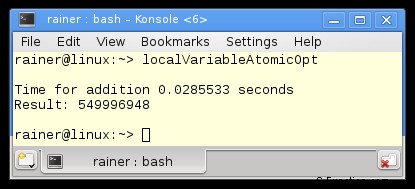
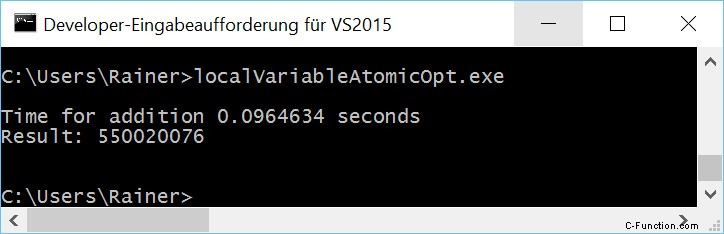
Atomaire operaties met ontspannen semantiek
Wij kunnen het beter. In plaats van het standaard geheugenmodel van sequentiële consistentie, gebruik ik ontspannen semantiek. Dat is goed gedefinieerd omdat het niet uitmaakt in welke volgorde de toevoegingen in regel 23 plaatsvinden.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | // localVariableAtomicRelaxed.cpp
#include <atomic>
#include <chrono>
#include <iostream>
#include <random>
#include <thread>
#include <utility>
#include <vector>
constexpr long long size= 100000000;
constexpr long long firBound= 25000000;
constexpr long long secBound= 50000000;
constexpr long long thiBound= 75000000;
constexpr long long fouBound= 100000000;
void sumUp(std::atomic<unsigned long long>& sum, const std::vector<int>& val, unsigned long long beg, unsigned long long end){
unsigned int long long tmpSum{};
for (auto i= beg; i < end; ++i){
tmpSum += val[i];
}
sum.fetch_add(tmpSum,std::memory_order_relaxed);
}
int main(){
std::cout << std::endl;
std::vector<int> randValues;
randValues.reserve(size);
std::mt19937 engine;
std::uniform_int_distribution<> uniformDist(1,10);
for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine));
std::atomic<unsigned long long> sum{};
auto start = std::chrono::system_clock::now();
std::thread t1(sumUp,std::ref(sum),std::ref(randValues),0,firBound);
std::thread t2(sumUp,std::ref(sum),std::ref(randValues),firBound,secBound);
std::thread t3(sumUp,std::ref(sum),std::ref(randValues),secBound,thiBound);
std::thread t4(sumUp,std::ref(sum),std::ref(randValues),thiBound,fouBound);
t1.join();
t2.join();
t3.join();
t4.join();
std::chrono::duration<double> dur= std::chrono::system_clock::now() - start;
std::cout << "Time for addition " << dur.count() << " seconds" << std::endl;
std::cout << "Result: " << sum << std::endl;
std::cout << std::endl;
}
|
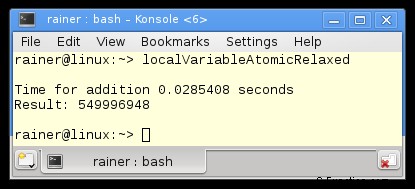
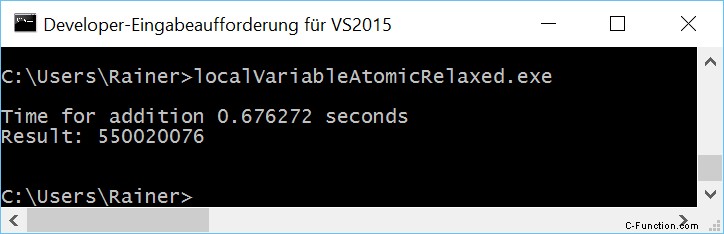
Zonder optimalisatie
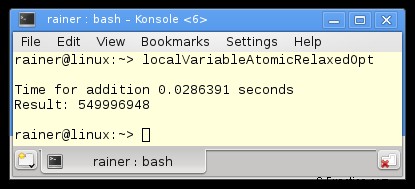
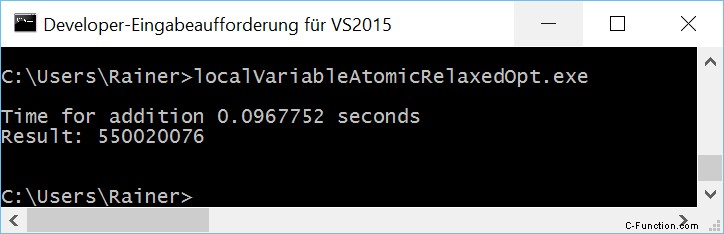
Maximale optimalisatie
De volgende strategie is vergelijkbaar. Maar nu gebruik ik lokale threadgegevens.
Lokale gegevens invoegen
Lokale threadgegevens zijn gegevens waarvan elke thread exclusief eigenaar is. Ze worden aangemaakt wanneer dat nodig is. Daarom passen lokale threadgegevens perfect bij de lokale sommatievariabele tmpSum.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | // threadLocal.cpp
#include <atomic>
#include <chrono>
#include <iostream>
#include <random>
#include <thread>
#include <utility>
#include <vector>
constexpr long long size= 100000000;
constexpr long long firBound= 25000000;
constexpr long long secBound= 50000000;
constexpr long long thiBound= 75000000;
constexpr long long fouBound= 100000000;
thread_local unsigned long long tmpSum= 0;
void sumUp(std::atomic<unsigned long long>& sum, const std::vector<int>& val, unsigned long long beg, unsigned long long end){
for (auto i= beg; i < end; ++i){
tmpSum += val[i];
}
sum.fetch_add(tmpSum,std::memory_order_relaxed);
}
int main(){
std::cout << std::endl;
std::vector<int> randValues;
randValues.reserve(size);
std::mt19937 engine;
std::uniform_int_distribution<> uniformDist(1,10);
for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine));
std::atomic<unsigned long long> sum{};
auto start = std::chrono::system_clock::now();
std::thread t1(sumUp,std::ref(sum),std::ref(randValues),0,firBound);
std::thread t2(sumUp,std::ref(sum),std::ref(randValues),firBound,secBound);
std::thread t3(sumUp,std::ref(sum),std::ref(randValues),secBound,thiBound);
std::thread t4(sumUp,std::ref(sum),std::ref(randValues),thiBound,fouBound);
t1.join();
t2.join();
t3.join();
t4.join();
std::chrono::duration<double> dur= std::chrono::system_clock::now() - start;
std::cout << "Time for addition " << dur.count() << " seconds" << std::endl;
std::cout << "Result: " << sum << std::endl;
std::cout << std::endl;
}
|
Ik declareer in regel 18 de thread-local variabele tmpSum en gebruik deze voor de toevoeging in regel 22 en 24. Het kleine verschil tussen de thread-local variabele en de lokale variabele in de vorige programma's is dat de levensduur van de thread-local variabele is gebonden aan de levensduur van zijn draad. De levensduur van de lokale variabele hangt af van het bereik.
Zonder optimalisatie
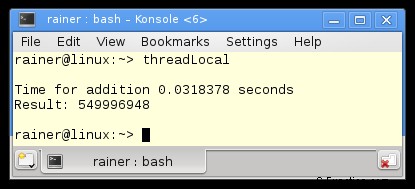

Maximale optimalisatie
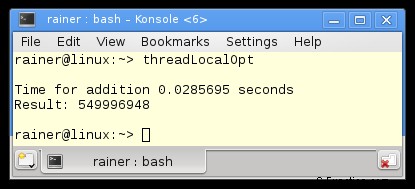
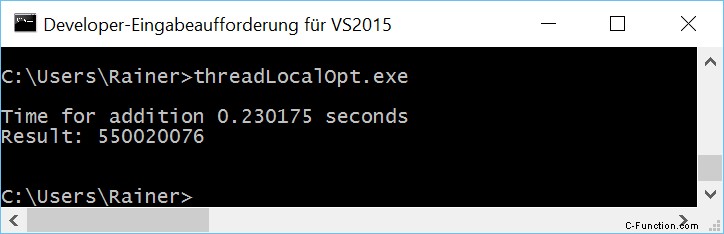
De vraag is. Is het mogelijk om de som op een snelle manier te berekenen zonder synchronisatie? Ja.
Taken
Met taak kunnen we het hele werk doen zonder synchronisatie. Elke sommatie wordt uitgevoerd in een aparte thread en de uiteindelijke sommatie in een enkele thread. Hier zijn de details van de taken. Ik zal belofte en toekomst gebruiken in het volgende programma.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 | // tasks.cpp
#include <chrono>
#include <future>
#include <iostream>
#include <random>
#include <thread>
#include <utility>
#include <vector>
constexpr long long size= 100000000;
constexpr long long firBound= 25000000;
constexpr long long secBound= 50000000;
constexpr long long thiBound= 75000000;
constexpr long long fouBound= 100000000;
void sumUp(std::promise<unsigned long long>&& prom, const std::vector<int>& val, unsigned long long beg, unsigned long long end){
unsigned long long sum={};
for (auto i= beg; i < end; ++i){
sum += val[i];
}
prom.set_value(sum);
}
int main(){
std::cout << std::endl;
std::vector<int> randValues;
randValues.reserve(size);
std::mt19937 engine;
std::uniform_int_distribution<> uniformDist(1,10);
for ( long long i=0 ; i< size ; ++i) randValues.push_back(uniformDist(engine));
std::promise<unsigned long long> prom1;
std::promise<unsigned long long> prom2;
std::promise<unsigned long long> prom3;
std::promise<unsigned long long> prom4;
auto fut1= prom1.get_future();
auto fut2= prom2.get_future();
auto fut3= prom3.get_future();
auto fut4= prom4.get_future();
auto start = std::chrono::system_clock::now();
std::thread t1(sumUp,std::move(prom1),std::ref(randValues),0,firBound);
std::thread t2(sumUp,std::move(prom2),std::ref(randValues),firBound,secBound);
std::thread t3(sumUp,std::move(prom3),std::ref(randValues),secBound,thiBound);
std::thread t4(sumUp,std::move(prom4),std::ref(randValues),thiBound,fouBound);
auto sum= fut1.get() + fut2.get() + fut3.get() + fut4.get();
std::chrono::duration<double> dur= std::chrono::system_clock::now() - start;
std::cout << "Time for addition " << dur.count() << " seconds" << std::endl;
std::cout << "Result: " << sum << std::endl;
t1.join();
t2.join();
t3.join();
t4.join();
std::cout << std::endl;
}
|
Ik definieer in regel 37 - 45 de vier beloften en creëer daaruit de bijbehorende toekomsten. Elke belofte wordt verplaatst in regels 50 - 52 in een aparte thread. Een belofte kan alleen worden verplaatst; daarom gebruik ik std::move. Het werkpakket van de thread is de functie sumUp (regels 18 - 24). sumUp neemt als eerste argument een belofte door rvalue referentie. De futures vragen in regel 55 om de resultaten. De get-oproep blokkeert.
Zonder optimalisatie
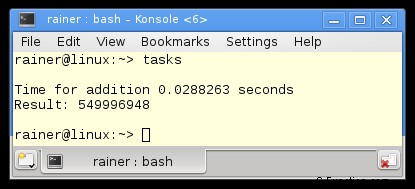
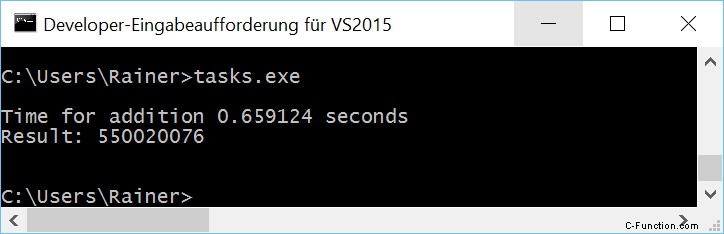
Maximale optimalisatie
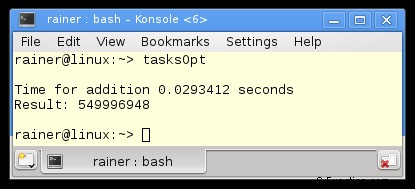
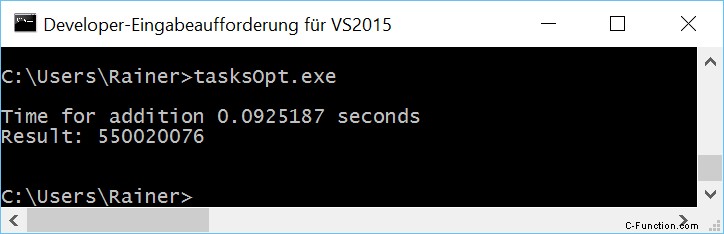
Alle nummers in het overzicht
Het overzicht
Zoals eerder vermeld, zijn de cijfers vrij gelijkaardig voor Linux. Dat is geen verrassing, want ik gebruik altijd dezelfde strategie:bereken de deelsom lokaal zonder synchronisatie en tel de lokale sommen op. De optelling van de deelsommen moet worden gesynchroniseerd. Wat me verbaasde was dat de maximale optimalisatie geen groot verschil maakt.
Op Windows is het verhaal totaal anders. Ten eerste maakt het een groot verschil of ik het programma met maximale of zonder optimalisatie compileer; tweede Windows is veel langzamer dan Linux. Ik weet niet zeker of dat komt doordat Windows maar 2 cores heeft, maar Linux 4.
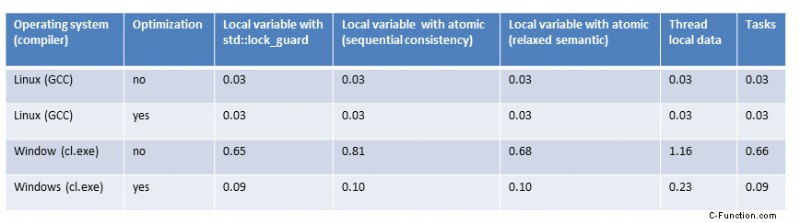
Wat nu?
Ik zal in de volgende post redeneren over de getallen voor het optellen van een vector en de resultaten die daaruit kunnen worden afgeleid.