In de kersttijd had ik een paar leuke discussies metAndre Adrian . Hij loste het probleem van de klassieke eetfilosoof op verschillende manieren op met behulp van moderne C++. Ik heb hem overtuigd om een artikel te schrijven over dit klassieke synchronisatieprobleem, en ik ben blij om het in drie opeenvolgende berichten te publiceren.

Door Benjamin D. Esham / Wikimedia Commons, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=56559
Diningfilosofen in C++ door Andre Adrian
Het probleem van de eetfilosofen is beschreven door Edsger W. Dijkstra. "Vijf filosofen, genummerd van 0 tot en met 4 wonen in een huis waar de tafel voor hen gedekt is, elke filosoof heeft zijn eigen plaats aan tafel:hun enige probleem - naast dat van de filosofie - is dat het gerecht dat geserveerd wordt een zeer moeilijk soort is spaghetti, die met twee vorken moet worden gegeten. Er zijn twee vorken naast elk bord, dus dat is geen probleem:als gevolg daarvan mogen er geen twee buren tegelijk eten." [ref 1971; Dijkstra; EWD310 Hiërarchische volgorde van opeenvolgende processen; https://www.cs.utexas.edu/users/EWD/transcriptions/EWD03xx/EWD310.html]
We gebruiken de volgende probleembeschrijving:4 filosofen leven een eenvoudig leven. Elke filosoof voert dezelfde routine uit:hij denkt een willekeurige tijdsduur, krijgt zijn eerste vork, krijgt zijn tweede vork, eet een willekeurige tijdsduur, legt de vorken neer en begint opnieuw te denken. Om het probleem interessant te maken hebben de 4 filosofen maar 4 vorken. Filosoof nummer 1 moet vorken nummer 1 en 2 nemen om te eten. Filosoof 2 heeft vorken 2 en 3 nodig, en zo verder tot filosoof 4 die vorken 4 en 1 nodig heeft om te eten. Na het eten legt de filosoof de vorken weer op tafel.
Meerdere bronnen gebruiken
Terwijl we van probleembeschrijving naar programmeren gaan, vertalen we filosofen naar threads en forks naar resources. In ons eerste programma - dp_1.cpp - we creëren 4 "filosoof" threads en 4 "fork" resource integers.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | // dp_1.cpp
#include <iostream>
#include <thread>
#include <chrono>
int myrand(int min, int max) {
return rand()%(max-min)+min;
}
void lock(int& m) {
m=1;
}
void unlock(int& m) {
m=0;
}
void phil(int ph, int& ma, int& mb) {
while(true) {
int duration=myrand(1000, 2000);
std::cout<<ph<<" thinks "<<duration<<"ms\n";
std::this_thread::sleep_for(std::chrono::milliseconds(duration));
lock(ma);
std::cout<<"\t\t"<<ph<<" got ma\n";
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
lock(mb);
std::cout<<"\t\t"<<ph<<" got mb\n";
duration=myrand(1000, 2000);
std::cout<<"\t\t\t\t"<<ph<<" eats "<<duration<<"ms\n";
std::this_thread::sleep_for(std::chrono::milliseconds(duration));
unlock(mb);
unlock(ma);
}
}
int main() {
std::cout<<"dp_1\n";
srand(time(nullptr));
int m1{0}, m2{0}, m3{0}, m4{0};
std::thread t1([&] {phil(1, m1, m2);});
std::thread t2([&] {phil(2, m2, m3);});
std::thread t3([&] {phil(3, m3, m4);});
std::thread t4([&] {phil(4, m4, m1);});
t1.join();
t2.join();
t3.join();
t4.join();
}
|
De main() function stelt willekeurige getallen vast in regel 42. We stellen de startwaarde van de generator voor willekeurige getallen in op het aantal seconden sinds 1 januari 1970. We definiëren onze vorkbronnen in regel 44. Vervolgens starten we vier threads die beginnen in regel 46. Om voortijdige beëindiging van de thread te voorkomen, voeg de threads samen die beginnen in regel 51. De threadfunctie phil() heeft een eeuwigdurende lus. De while(true) statement is altijd true , daarom zal de thread nooit eindigen. De probleembeschrijving zegt "hij denkt voor een willekeurige duur". Eerst berekenen we een willekeurige duur met de functie myrand( ), zie regel 20 en regel 6. De functie myrand() produceert een pseudo-willekeurige retourwaarde in het bereik van [min, max). Voor het traceren van het programma loggen we het nummer van de filosoof, zijn huidige staat van "hij denkt" en de duur in de console. De sleep_for() -statement laat de planner de thread voor de duur in de wachtstand zetten. In een "echt" programma verbruikt de broncode van de applicatie tijd in plaats van sleep_for() .Nadat de denktijd van de filosoof voorbij is, krijgt hij "zijn eerste vork". Zie regel 24. We gebruiken een functie lock() om het "gets fork"-ding uit te voeren. Op dit moment is de functie lock() is heel eenvoudig omdat we niet beter weten. We hebben zojuist de fork-resource ingesteld op de waarde 1. Zie regel 10. Nadat de filosofenthread zijn eerste fork heeft verkregen, kondigt hij trots de nieuwe staat aan met een "got ma " console output. Nu krijgt de thread "zijn tweede fork". Zie regel 28. De corresponderende console output is "got mb ". De volgende status is "he eats ". Opnieuw bepalen we de duur, produceren een console-uitvoer en bezetten de thread met een sleep_for() . Zie regel 31. Na de status "he eats " de filosoof legt zijn vork neer. Zie regels 35 en 14. De unlock() functie is weer heel eenvoudig en zet de resource terug naar 0.
Compileer het programma zonder compileroptimalisatie. De reden zullen we later zien. De console-output van ons programma ziet er veelbelovend uit:
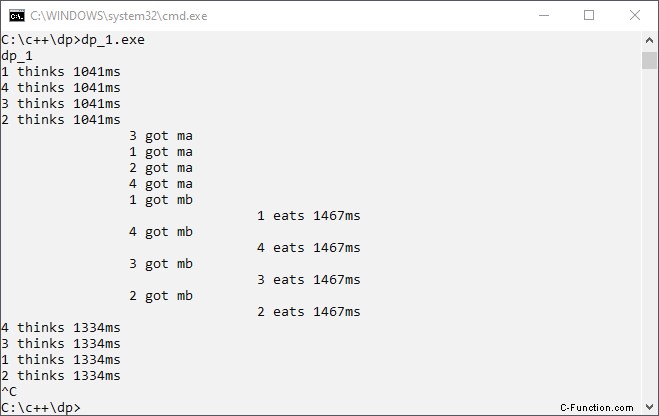
Hebben we het probleem van de eetfilosofen al opgelost? Welnu, de uitvoer van het programma is niet gedetailleerd genoeg om deze vraag te beantwoorden.
Meerdere bronnen gebruiken met logging
We zouden wat meer logging moeten toevoegen. Op dit moment is de functie lock() controleert niet of de fork beschikbaar is voordat de resource wordt gebruikt. De verbeterde versie van lock() in programma dp_2.cpp is:
void lock(int& m) {
if (m) {
std::cout<<"\t\t\t\t\t\tERROR lock\n";
}
m=1;
}
Programmaversie 2 produceert de volgende uitvoer:
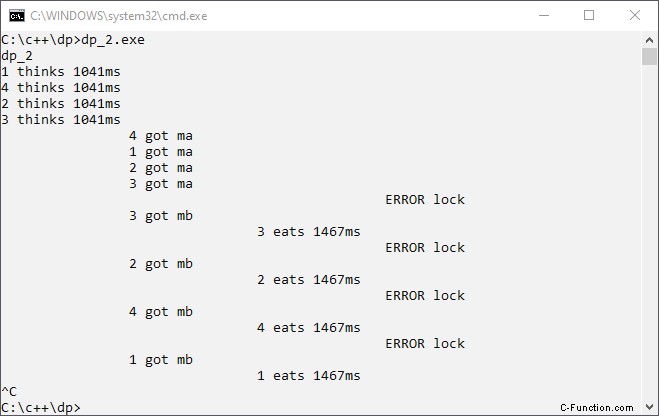
We zien "ERROR lock " console-uitvoer. Deze uitvoer vertelt ons dat twee filosofen tegelijkertijd dezelfde bron gebruiken. Wat kunnen we doen?
Fout bezig met wachten zonder resourcehiërarchie
We kunnen het if-statement wijzigen in lock() in een while-statement. Dit while-statement levert een spinlock op. Een spinlock is een mooi woord voor druk wachten. Terwijl de fork-resource in gebruik is, is de thread bezig met wachten op een wijziging van de staat die in gebruik is naar de beschikbare staat. Op dit moment hebben we de fork-resource opnieuw ingesteld op de status in gebruik. In programma dp_3.cpp we hebben:
void lock(int& m) {
while (m)
; // busy waiting
m=1;
}
Geloof alsjeblieft dat deze kleine verandering nog steeds geen JUISTE oplossing is voor het probleem van de eetfilosofen. We hebben niet langer het verkeerde gebruik van hulpbronnen. Maar we hebben een ander probleem. Zie programmaversie 3 uitvoer:

Elke filosoofdraad neemt zijn eerste vorkbron en kan dan de tweede vork niet nemen. Wat kunnen we doen? Andrew S. Tanenbaum schreef:"Een andere manier om het circulaire wachten te vermijden, is door een globale nummering van alle bronnen te geven. De regel is nu:processen kunnen bronnen aanvragen wanneer ze maar willen, maar alle verzoeken moeten in numerieke volgorde worden gedaan." [ref 2006; Tanenbaum; Besturingssystemen. Ontwerp en implementatie, 3e editie; hoofdstuk 3.3.5]
Fout bezig met wachten met resourcehiërarchie
Deze oplossing staat bekend als resourcehiërarchie of gedeeltelijke volgorde. Voor het probleem van de eetfilosofen is gedeeltelijk bestellen eenvoudig. De eerste vork die wordt genomen, moet de vork met het laagste nummer zijn. Voor filosofen 1 t/m 3 worden de bronnen in de juiste volgorde genomen. Alleen filosoofdraad 4 heeft een verandering nodig voor een juiste deelordening. Haal eerst fork resource 1, dan fork resource 4. Zie het hoofdprogramma in file dp_4.cpp :
int main() {
std::cout<<"dp_4\n";
srand(time(nullptr));
int m1{0}, m2{0}, m3{0}, m4{0};
std::thread t1([&] {phil(1, m1, m2);});
std::thread t2([&] {phil(2, m2, m3);});
std::thread t3([&] {phil(3, m3, m4);});
std::thread t4([&] {phil(4, m1, m4);});
t1.join();
t2.join();
t3.join();
t4.join();
}
De uitvoer van programmaversie 4 ziet er goed uit:
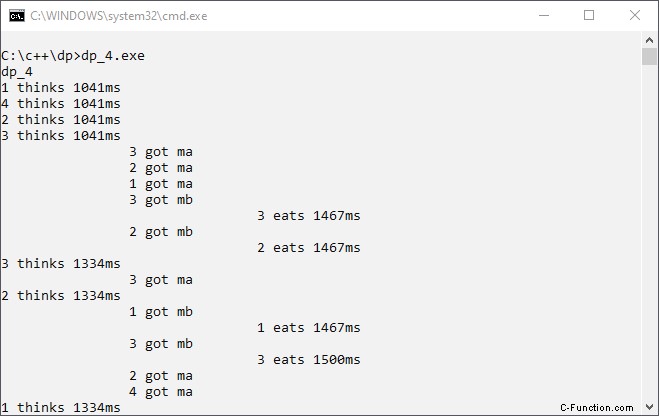
Nu is er niet langer een verkeerd gebruik van hulpbronnen, noch hebben we een impasse. We worden dapper en gebruiken compiler-optimalisatie. We willen een goed programma dat snel wordt uitgevoerd! Dit is de uitvoer van programmaversie 4 met compileroptimalisatie:
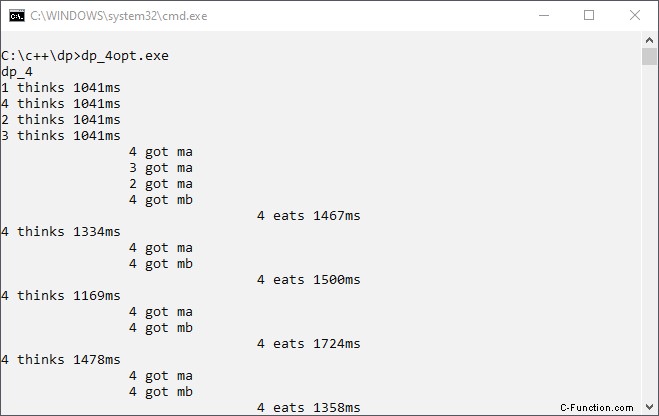
Het is altijd dezelfde filosofische draad die eet. Is het mogelijk dat de instelling van compileroptimalisatie het gedrag van een programma kan veranderen? Ja, het is mogelijk. De filosofische threads lezen uit het geheugen de waarde van fork resource. De optimalisatie van de compiler optimaliseert een deel van deze geheugenuitlezingen. Alles heeft een prijs!
Nog steeds foutief bezig met wachten met resourcehiërarchie
De programmeertaal C++ heeft de atomaire sjabloon om een atomair type te definiëren. Als een thread naar een atomair object schrijft terwijl een andere thread ervan leest, is het gedrag goed gedefinieerd. In bestand dp_5.cpp we gebruiken atomic<int> voor de vorkbronnen. Zie regels 11, 17, 21 en 47. We bevatten <atomic> in regel 5:
// dp_5.cpp
#include <iostream>
#include <thread>
#include <chrono>
#include <atomic>
int myrand(int min, int max) {
return rand()%(max-min)+min;
}
void lock(std::atomic<int>& m) {
while (m)
; // busy waiting
m=1;
}
void unlock(std::atomic<int>& m) {
m=0;
}
void phil(int ph, std::atomic<int>& ma, std::atomic<int>& mb) {
while(true) {
int duration=myrand(1000, 2000);
std::cout<<ph<<" thinks "<<duration<<"ms\n";
std::this_thread::sleep_for(std::chrono::milliseconds(duration));
lock(ma);
std::cout<<"\t\t"<<ph<<" got ma\n";
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
lock(mb);
std::cout<<"\t\t"<<ph<<" got mb\n";
duration=myrand(1000, 2000);
std::cout<<"\t\t\t\t"<<ph<<" eats "<<duration<<"ms\n";
std::this_thread::sleep_for(std::chrono::milliseconds(duration));
unlock(mb);
unlock(ma);
}
}
int main() {
std::cout<<"dp_5\n";
srand(time(nullptr));
std::atomic<int> m1{0}, m2{0}, m3{0}, m4{0};
std::thread t1([&] {phil(1, m1, m2);});
std::thread t2([&] {phil(2, m2, m3);});
std::thread t3([&] {phil(3, m3, m4);});
std::thread t4([&] {phil(4, m1, m4);});
t1.join();
t2.join();
t3.join();
t4.join();
}
De uitvoer van programmaversie 5 is:
Wat nu?
De volgende aflevering van dit probleem van de eetfilosoof lost de kleine kans op wangedrag op . Tot nu toe was geen van de programma's correct.