Il modo più semplice per rimuovere i caratteri non alfanumerici da una stringa consiste nell'usare regex:
if (string.IsNullOrEmpty(s))
return s;
return Regex.Replace(s, "[^a-zA-Z0-9]", "");
Code language: C# (cs)Nota:non inserire un valore nullo, altrimenti otterrai un'eccezione.
Regex è l'approccio più semplice per risolvere questo problema, ma è anche il più lento. Se sei preoccupato per le prestazioni, dai un'occhiata alla sezione delle prestazioni di seguito.
Questo esempio mantiene solo i caratteri alfanumerici ASCII. Se stai lavorando con altri alfabeti, consulta la sezione seguente su come specificare caratteri non ASCII.
Per prestazioni migliori, usa un loop
Scorrere la stringa e prendere i caratteri desiderati è 7,5 volte più veloce dell'espressione regolare (e 3 volte più veloce dell'utilizzo di Linq).
if (string.IsNullOrEmpty(s))
return s;
StringBuilder sb = new StringBuilder();
foreach(var c in s)
{
if ((c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') || (c >= '0' && c <= '9'))
sb.Append(c);
}
return sb.ToString();
Code language: C# (cs)Non preoccuparti di usare l'espressione regolare compilata
L'uso di espressioni regolari compilate non aiuta molto con le prestazioni in questo scenario. Nel migliore dei casi, è leggermente più veloce. Nel peggiore dei casi, è come non usare l'espressione regolare compilata. È più semplice utilizzare i metodi statici regex (come Regex.Replace()), invece di cercare di assicurarsi che l'oggetto regex compilato sia disponibile ovunque. In altre parole, usa semplicemente i metodi regex statici invece dell'espressione regolare compilata.
Ecco un esempio di utilizzo di espressioni regolari compilate:
private static readonly Regex regex = new Regex("[^a-zA-Z0-9]", RegexOptions.Compiled);
public static string RemoveNonAlphanumericChars(string s)
{
if (string.IsNullOrEmpty(s))
return s;
return regex.Replace(s, "");
}
Code language: C# (cs)Usa char.IsLetterOrDigit() se vuoi tutti i caratteri alfanumerici Unicode
Tieni presente che char.IsLetterOrDigit() restituisce true per tutti i caratteri alfanumerici Unicode. Di solito quando stai eliminando i personaggi, è perché sai esattamente quali personaggi vuoi prendere. L'utilizzo di char.IsLetterOrDigit() dovrebbe essere utilizzato solo se si desidera accettare TUTTI i caratteri alfanumerici Unicode e rimuovere tutto il resto. Dovrebbe essere raro.
È meglio specificare esattamente quali caratteri vuoi mantenere (e quindi se stai usando regex, applica l'operatore ^ per rimuovere tutto tranne quei caratteri).
Risultati del benchmark
Ho confrontato quattro approcci per la rimozione di caratteri non alfanumerici da una stringa. Ho passato a ogni metodo una stringa con 100 caratteri. Il grafico seguente mostra i risultati:
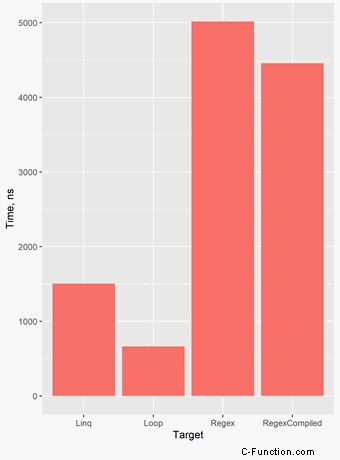
Ecco tutte le statistiche del benchmark:
| Method | Mean | StdDev | Min | Max |
|-------------- |-----------:|----------:|-----------:|-----------:|
| Regex | 5,016.4 ns | 139.89 ns | 4,749.4 ns | 5,325.5 ns |
| RegexCompiled | 4,457.9 ns | 301.40 ns | 3,930.5 ns | 5,360.4 ns |
| Linq | 1,506.9 ns | 76.75 ns | 1,393.0 ns | 1,722.3 ns |
| Loop | 663.7 ns | 31.15 ns | 599.6 ns | 742.3 ns |Code language: plaintext (plaintext)Specifica di caratteri non ASCII in regex
Che ne dici se devi gestire caratteri alfanumerici non ASCII, come i seguenti caratteri greci:
ΕλληνικάCode language: plaintext (plaintext)Se hai a che fare con un alfabeto non ASCII, come il greco, puoi cercare l'intervallo Unicode e utilizzare i punti di codice o i caratteri.
Nota:ricorda che si tratta di rimuovere i caratteri. Quindi, con regex, specifichi quali caratteri desideri, quindi usi l'operatore ^ per abbinare tutto tranne quei caratteri.
Utilizza punti di codice Unicode
Ecco un esempio di specifica dell'intervallo di punti di codice Unicode greco:
Regex.Replace(s, "[^\u0370-\u03FF]", "");
Code language: C# (cs)Usa blocco denominato Unicode
Per una migliore leggibilità, puoi utilizzare un blocco denominato Unicode, come "IsGreek". Per specificare che vuoi usare un blocco con nome, usa \p{} in questo modo:
Regex.Replace(s, @"[^\p{IsGreek}]", "");
Code language: C# (cs)Specifica esattamente quali caratteri Unicode desideri
Puoi specificare esattamente quali caratteri Unicode desideri (incluso un intervallo di essi):
Regex.Replace(s, "[^α-ωάΕ]", "");
Code language: C# (cs)È più facile da leggere rispetto all'utilizzo dei punti di codice.