Credo che il motivo sia l'implementazione di SequenceReader.TryReadTo . Ecco il codice sorgente di questo metodo. Utilizza un algoritmo piuttosto semplice (leggi la corrispondenza del primo byte, quindi controlla se tutti i byte successivi dopo quella corrispondenza, in caso contrario, avanza di 1 byte in avanti e ripeti) e nota come ci sono alcuni metodi in questa implementazione chiamati "lento" (IsNextSlow , TryReadToSlow e così via), quindi almeno in determinate circostanze e in certi casi si ripiega su un percorso lento. Ha anche a che fare con la sequenza dei fatti che potrebbe contenere più segmenti e con il mantenimento della posizione.
Nel tuo caso puoi evitare di usare SequenceReader specificamente per cercare la corrispondenza (ma lasciarlo per leggere effettivamente le righe), ad esempio con queste modifiche minori (questo sovraccarico di TryReadTo è anche più efficiente in questo caso):
private static bool TryReadLine(ref SequenceReader<byte> bufferReader, out ReadOnlySpan<byte> line) {
// note that both `match` and `line` are now `ReadOnlySpan` and not `ReadOnlySequence`
var foundNewLine = bufferReader.TryReadTo(out ReadOnlySpan<byte> match, (byte) '\n', advancePastDelimiter: true);
if (!foundNewLine) {
line = default;
return false;
}
line = match;
return true;
}
Quindi:
private static bool ContainsBytes(ref ReadOnlySpan<byte> line, in ReadOnlySpan<byte> searchBytes) {
// line is now `ReadOnlySpan` so we can use efficient `IndexOf` method
return line.IndexOf(searchBytes) >= 0;
}
In questo modo il codice delle pipe verrà eseguito più velocemente di quello degli stream.
Questa forse non è esattamente la spiegazione che cerchi, ma spero che dia qualche spunto:
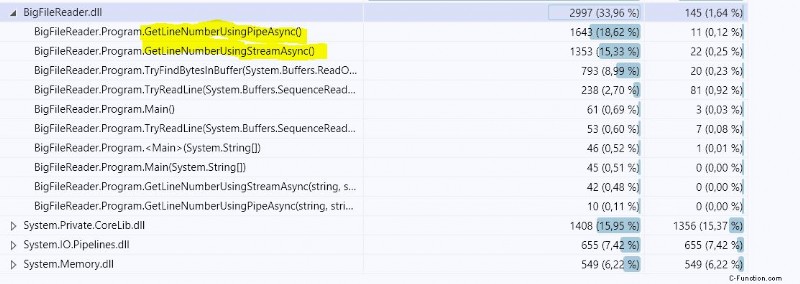
Dando un'occhiata ai due approcci che hai lì, mostra che nella seconda soluzione è computazionalmente più complesso dell'altro, avendo due cicli nidificati.
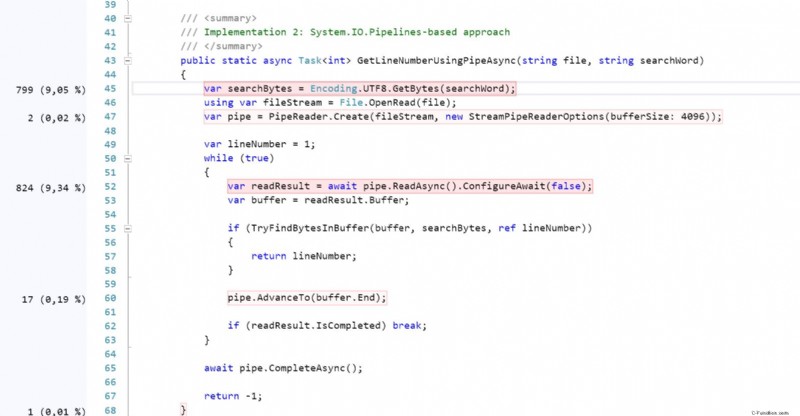
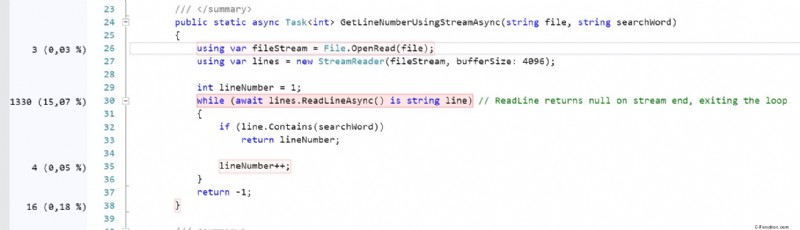
Scavando più a fondo utilizzando la profilazione del codice si evince che il secondo (GetLineNumberUsingPipeAsync) richiede quasi il 21,5% in più di CPU rispetto a quello che utilizza Stream (controlla gli screenshot, ) Ed è abbastanza vicino al risultato del benchmark che ho ottenuto:
-
Soluzione n. 1:683,7 ms, 365,84 MB
-
Soluzione n. 2:777,5 ms, 9,08 MB