L'articolo confronta un analizzatore statico specializzato Viva64 con analizzatori statici universali Parasoft C++Test e Gimpel Software PC-Lint. Il confronto viene effettuato nell'ambito dell'attività di porting di codice C/C++ a 32 bit su sistemi a 64 bit o di sviluppo di nuovo codice tenendo conto delle peculiarità dell'architettura a 64 bit.
Introduzione
Lo scopo di questo articolo è mostrare i vantaggi dell'analizzatore Viva64 rispetto ad altri prodotti con capacità funzionali simili. Viva64 è un analizzatore statico specializzato per la verifica del codice C/C++ a 64 bit [1]. Il suo ambito di utilizzo è lo sviluppo di nuovo codice a 64 bit o il porting del vecchio codice su sistemi a 64 bit. Ormai l'analizzatore è implementato per il sistema operativo Windows essendo un modulo collegabile nell'ambiente di sviluppo Visual'Studio 2005/2008.
Questo articolo è di attualità perché non ci sono informazioni sistematizzate sulle capacità dei moderni analizzatori statici che sono annunciati come strumenti per la diagnosi di errori a 64 bit. Nell'ambito di questo articolo confronteremo tre analizzatori più popolari che implementano il controllo del codice a 64 bit:Viva64, Parasoft C++Test, Gimpel Software PC-Lint.
Il confronto effettuato verrà presentato nella tabella e quindi toccheremo brevemente ciascuno dei criteri di valutazione. Ma prima spieghiamo alcune nozioni che verranno utilizzate in questo articolo.
1. Termini e definizioni
1.1. Modello di dati
In un modello di dati si comprendono le correlazioni delle dimensioni dei tipi accettate nell'ambito dell'ambiente di sviluppo. Possono esserci diversi ambienti di sviluppo che contengono modelli di dati diversi per un sistema operativo, ma di solito esiste un solo modello che corrisponde all'ambiente hardware e software. Un esempio è un sistema operativo Windows a 64 bit per il quale il modello di dati LLP64 è nativo. Ma ai fini della compatibilità, un Windows a 64 bit supporta programmi a 32 bit che funzionano nel modello di dati ILP32LL.
La tabella 1 mostra i modelli di dati più diffusi. Siamo interessati prima di tutto ai modelli di dati LP64 e LLP64.
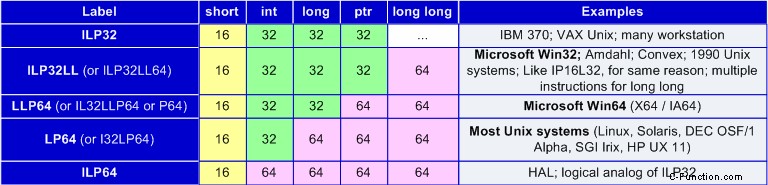
Tabella 1. Modelli di dati più diffusi.
I modelli di dati LP64 e LLP64 differiscono solo per le dimensioni del tipo "lungo". Ma questa piccola differenza contiene una grande differenza nelle metodologie consigliate per lo sviluppo di programmi per i sistemi operativi a 64 bit delle famiglie Unix e Windows. Ad esempio, nei programmi Unix si consiglia di utilizzare il tipo lungo o il tipo lungo senza segno per memorizzare i puntatori e creare cicli per elaborare un numero elevato di elementi. Ma questi tipi non sono adatti per i programmi Windows e dovresti usare ptrdiff_t e size_t invece di loro. Per saperne di più sulle peculiarità dell'utilizzo di diversi modelli di dati si può leggere l'articolo "Problemi dimenticati nello sviluppo di programmi a 64 bit" [2].
In questo articolo parliamo di modelli di dati perché diversi analizzatori statici non sono sempre adatti al modello di dati LP64 e anche a LLP64. Guardando al futuro, possiamo dire che gli analizzatori Parasoft C++Test e Gimpel Software PC-Lint sono più adatti ai sistemi Unix che a quelli Windows.
1.2. Memsize-tipi
Per rendere più facile la comprensione dell'argomento dell'articolo useremo il termine "memsize-type". Questo termine è apparso come un tentativo di nominare brevemente tutti i tipi in grado di memorizzare le dimensioni dei puntatori e degli indici degli array più grandi. Il tipo Memsize può memorizzare la dimensione massima dell'array che può essere teoricamente allocata nell'ambito dell'architettura data.
In memsize-types comprendiamo tutti i tipi di dati semplici del linguaggio C/C++ che hanno una dimensione di 32 bit sull'architettura a 32 bit e una dimensione di 64 bit su quella a 64 bit. Tieni presente che il tipo lungo non è un tipo memsize in Windows mentre in Unix lo è. Per chiarire i principali tipi di memsize sono mostrati nella tabella 2.
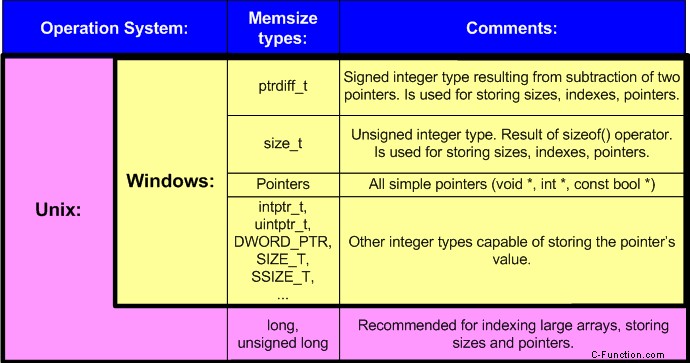
Tabella 2. Esempi di tipi memsize.
2. Tabella di confronto
Passiamo al confronto degli analizzatori statici stesso. Le informazioni comparative sono fornite nella tabella 3. L'elenco dei criteri di valutazione è stato composto sulla base della documentazione degli analizzatori statici, degli articoli e di altre fonti aggiuntive. Puoi conoscere le fonti originali tramite i seguenti link:
- Articolo:Andrey Karpov, Evgeniy Ryzhkov. 20 problemi di porting del codice C++ sulla piattaforma a 64 bit
- Parasoft C++Test:Guida per l'utente di C++Test (elementi utente:3264bit_xxxxxxx.rule)
- Gimpel Software PC-Lint:test a 64 bit (C) Verifica dei programmi rispetto al modello LP64
- Sistemi di verifica del programma Viva64:Guida in linea
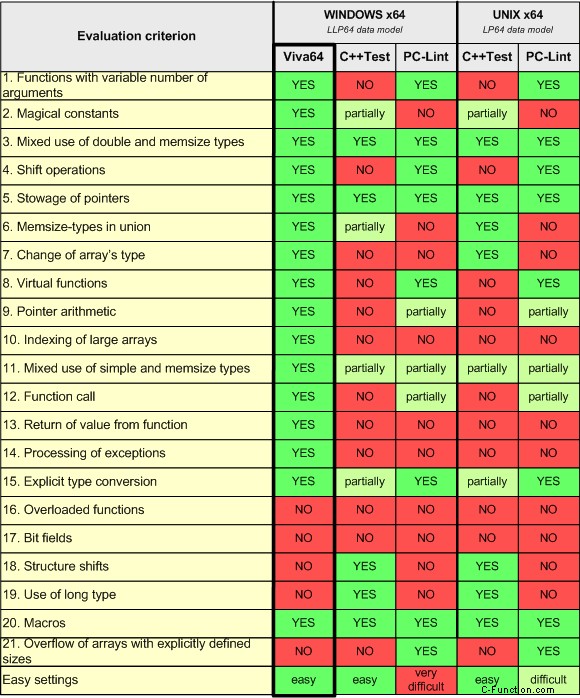
Tabella 3. Confronto di analizzatori statici dal punto di vista della ricerca di errori specifici del codice a 64 bit.
3. Criteri di valutazione
I nomi dei criteri di valutazione elencati nella tabella non rivelano molte informazioni di per sé. Ecco perché parliamo brevemente di ciascuno di essi. Paragrafo 3.1. corrisponde al primo criterio, paragrafo 3.2. al secondo ecc.
Per ulteriori informazioni sugli errori tipici che si verificano durante il porting di applicazioni su sistemi a 64 bit, vedere i seguenti articoli:20 problemi relativi al porting di codice C++ sulla piattaforma a 64 bit [3], Problemi di test di applicazioni a 64 bit [4], Sviluppo di risorse -applicazioni intensive in ambiente Visual C++ [5].
3.1. Uso dei tipi memsize come argomenti fattuali in funzioni con numero variabile di argomenti
Un tipico esempio è l'uso scorretto delle funzioni printf, scanf e delle loro varietà:
1) const char *invalidFormat = "%u";
size_t value = SIZE_MAX;
printf(invalidFormat, value);
2) char buf[9];
sprintf(buf, "%p", pointer);Nel primo caso non si tiene conto che il tipo size_t non è equivalente al tipo unsigned su una piattaforma a 64 bit. Ciò causerà la stampa di un risultato errato se valore> UINT_MAX.
Nel secondo caso non si tiene conto del fatto che la dimensione del puntatore potrà essere in futuro superiore a 32 bit. Di conseguenza, questo codice causerà un overflow su un'architettura a 64 bit.
3.2. Uso di costanti magiche
In un codice di bassa qualità potresti spesso vedere costanti magiche che sono pericolose di per sé. Durante la migrazione del codice sulla piattaforma a 64 bit queste costanti possono renderlo non valido se partecipano ad operazioni di calcolo di indirizzi, dimensioni di oggetti o operazioni di bit. Le principali costanti magiche sono:4, 32, 0x7fffffff, 0x80000000, 0xffffffff. Ad esempio:
size_t ArraySize = N * 4;
intptr_t *Array = (intptr_t *)malloc(ArraySize);3.3. Memorizzazione di valori interi rappresentati da un tipo memsize in double
Il tipo doppio di norma ha una dimensione di 64 bit ed è compatibile con lo standard IEEE-754 su sistemi a 32 e 64 bit. A volte il tipo double viene utilizzato nel codice per archiviare e lavorare con i tipi interi:
size_t a = size_t(-1);
double b = a;
--a;
--b;
size_t c = b; // x86: a == c
// x64: a != cTale codice può essere giustificato su un sistema a 32 bit in cui il tipo double può memorizzare un valore intero a 32 bit senza perdite poiché ha 52 bit significativi. Ma quando si tenta di salvare un numero intero a 64 bit nel doppio, il valore esatto può andare perso.
3.4. Lavoro scorretto con operazioni a turni
Le operazioni di spostamento possono causare molti problemi se utilizzate con disattenzione durante il porting del codice da un sistema a 32 bit a un sistema a 64 bit. Consideriamo la funzione che definisce il valore del bit specificato come "1" in una variabile di tipo memsize:
ptrdiff_t SetBitN(ptrdiff_t value, unsigned bitNum) {
ptrdiff_t mask = 1 << bitNum;
return value | mask;
}Questo codice è valido su un'architettura a 32 bit e consente di definire bit con numeri da 0 a 31. Dopo aver portato il programma su una piattaforma a 64 bit è necessario definire bit da 0 a 63. Ma la chiamata di SetBitN(0, 32) la funzione restituirà 0. Tieni presente che "1" ha il tipo int e si verificherà un overflow allo spostamento di 32 posizioni e il risultato sarà errato.
3.5. Stoccaggio di puntatori in tipi non memsize
Molti errori relativi alla migrazione su sistemi a 64 bit sono legati alla modifica della dimensione di un puntatore rispetto alla dimensione di interi semplici. Molti programmatori hanno memorizzato i puntatori in tipi come int e unsigned nei loro programmi a 32 bit. Questo ovviamente non è corretto dal punto di vista dei modelli di dati a 64 bit. Ad esempio:
char *p;
p = (char *) ((unsigned int)p & PAGEOFFSET);Dovresti tenere a mente che si dovrebbero usare solo i tipi memsize per memorizzare i puntatori in forma intera. Fortunatamente, tali errori vengono rilevati facilmente non solo dagli analizzatori statici ma anche dai compilatori quando si attivano le opzioni corrispondenti.
3.6. Uso dei tipi memsize nei sindacati
Una particolarità dell'unione in C/C++ è che la stessa area di memoria è allocata per memorizzare tutti gli elementi - membri di un'unione. Sebbene l'accesso a questa area di memoria sia possibile utilizzando uno qualsiasi degli elementi, è comunque necessario selezionare l'elemento per l'accesso in modo che il risultato sia ragionevole.
Dovresti prestare attenzione ai sindacati che contengono puntatori e altri membri di tipo memsize. Gli sviluppatori spesso pensano erroneamente che la dimensione del tipo memsize sarà sempre uguale al gruppo di altri oggetti su tutte le architetture. Ecco un esempio di una funzione errata che implementa un algoritmo di tabella per il calcolo del numero di bit zero nella variabile "value":
union SizetToBytesUnion {
size_t value;
struct {
unsigned char b0, b1, b2, b3;
} bytes;
} u;
SizetToBytesUnion u;
u.value = value;
size_t zeroBitsN = TranslateTable[u.bytes.b0] +
TranslateTable[u.bytes.b1] +
TranslateTable[u.bytes.b2] +
TranslateTable[u.bytes.b3];3.7. Modifica del tipo di un array
A volte è necessario (o semplicemente conveniente) convertire gli elementi di un array in elementi di tipo diverso. La conversione di tipo non sicura e sicura è mostrata nel codice seguente:
int array[4] = { 1, 2, 3, 4 };
enum ENumbers { ZERO, ONE, TWO, THREE, FOUR };
//safe cast (for MSVC2005/2008)
ENumbers *enumPtr = (ENumbers *)(array);
cout << enumPtr[1] << " ";
//unsafe cast
size_t *sizetPtr = (size_t *)(array);
cout << sizetPtr[1] << endl;
//Output on 32-bit system: 2 2
//Output on 64 bit system: 2 171798691873.8. Errori che si verificano quando si utilizzano funzioni virtuali con argomenti di tipo memsize
Se il tuo programma ha grandi gerarchie di ereditarietà di classi con funzioni virtuali, potresti usare distrattamente argomenti di tipo diverso che quasi coincidono su un sistema a 32 bit. Ad esempio, usi il tipo size_t come argomento di una funzione virtuale in una classe base mentre nel discendente è un tipo senza segno. Di conseguenza, questo codice non sarà corretto su un sistema a 64 bit.
Tali errori non si riferiscono sempre a gerarchie di eredità complesse, ad esempio:
class CWinApp {
...
virtual void WinHelp(DWORD_PTR dwData, UINT nCmd);
};
class CSampleApp : public CWinApp {
...
virtual void WinHelp(DWORD dwData, UINT nCmd);
};Tali errori possono verificarsi non solo a causa della disattenzione del programmatore. L'errore mostrato nell'esempio si verifica se il codice è stato sviluppato per versioni precedenti della libreria MFC in cui il prototipo della funzione WinHelp nella classe CWinApp era simile a questo:
virtual void WinHelp(DWORD dwData, UINT nCmd = HELP_CONTEXT);Sicuramente hai usato il tipo DWORD nel tuo codice. In Microsoft Visual C++ 2005/2008 il prototipo della funzione è stato modificato. Su un sistema a 32 bit il programma continuerà a funzionare correttamente poiché i tipi DWORD e DWORD_PTR coincidono qui. Ma ci saranno problemi nel programma a 64 bit. Avrai due funzioni con gli stessi nomi ma parametri diversi e di conseguenza il tuo codice non verrà eseguito.
3.9. Aritmetica del puntatore errata
Consideriamo il seguente esempio:
unsigned short a16, b16, c16;
char *pointer;
...
pointer += a16 * b16 * c16;Questo codice funziona correttamente con i puntatori se il valore dell'espressione "a16 * b16 * c16" non supera UINT_MAX (4 Gb). Tale codice potrebbe sempre funzionare correttamente su una piattaforma a 32 bit poiché un programma non potrebbe mai allocare un array di dimensioni maggiori. Su un'architettura a 64 bit la dimensione dell'array supererà UINT_MAX di elementi. Supponiamo di voler spostare il valore del puntatore in 6.000.000.000 di byte ed è per questo che le variabili a16, b16 e c16 hanno i valori 3000, 2000 e 1000 corrispondentemente. Durante il calcolo dell'espressione "a16 * b16 * c16" tutte le variabili verranno convertite in tipo int secondo le regole del linguaggio C++ e solo allora verranno moltiplicate. Durante la moltiplicazione si verificherà un overflow. Il risultato errato dell'espressione verrà esteso al tipo ptrdiff_t e il puntatore verrà calcolato in modo errato.
Ecco un altro esempio di codice valido in una versione a 32 bit e non valido in una a 64 bit:
int A = -2;
unsigned B = 1;
int array[5] = { 1, 2, 3, 4, 5 };
int *ptr = array + 3;
ptr = ptr + (A + B); //Invalid pointer value on 64-bit platform
printf("%i\n", *ptr); //Access violation on 64-bit platformTracciamo il modo di calcolare l'espressione "ptr + (A + B)":
- Secondo le regole del linguaggio C++, la variabile A di tipo int viene convertita in un tipo senza segno.
- A e B sono riassunti. Di conseguenza otteniamo il valore 0xFFFFFFFF di tipo non firmato.
Quindi viene calcolata l'espressione "ptr + 0xFFFFFFFFu" ma il risultato di ciò dipende dalla dimensione del puntatore sull'architettura data. Se l'addizione verrà eseguita in un programma a 32 bit, l'espressione data sarà equivalente a "ptr - 1" e avremo stampato il numero 3.
In un programma a 64 bit il valore 0xFFFFFFFFu verrà aggiunto al puntatore e di conseguenza il puntatore sarà ben oltre i limiti dell'array.
3.10. Indicizzazione errata di array di grandi dimensioni
Nella programmazione C e successiva C++ è stata sviluppata la pratica di utilizzare variabili di tipo int e unsigned come indici per lavorare con gli array. Ma il tempo passa e tutto cambia. E ora è giunto il momento di dire:"Smettila di farlo! Usa solo tipi memsize per indicizzare array di grandi dimensioni". Un esempio di codice errato che utilizza il tipo non firmato:
unsigned Index = 0;
while (MyBigNumberField[Index] != id)
Index++;Questo codice non può elaborare una matrice contenente più di elementi UINT_MAX in un programma a 64 bit. Dopo l'accesso all'elemento con indice UINT_MAX si verificherà un overflow della variabile Index e otterremo un ciclo eterno.
Vorremmo che gli sviluppatori Windows prestassero ancora una volta l'attenzione sul fatto che il tipo lungo rimane a 32 bit in un Windows a 64 bit. Ecco perché il consiglio degli sviluppatori Unix di utilizzare il tipo lungo per i cicli lunghi è irrilevante.
3.11. Uso misto di tipi interi semplici e tipi memsize
L'uso misto di tipi memsize e tipi non memsize nelle espressioni può causare risultati errati su sistemi a 64 bit e riguardare la modifica dell'intervallo di valori di input. Consideriamo alcuni esempi:
size_t Count = BigValue;
for (unsigned Index = 0; Index != Count; ++Index)
{ ... }Questo è un esempio di ciclo eterno se Conteggio> UINT_MAX. Si supponga che su sistemi a 32 bit questo codice abbia funzionato in un intervallo di iterazioni inferiori a UINT_MAX. Ma una versione a 64 bit del programma può elaborare più dati e potrebbe richiedere più iterazioni. Poiché i valori della variabile indice si trovano nell'intervallo [0..UINT_MAX], la condizione "Indice !=Conteggio" non sarà mai soddisfatta e causerà un ciclo eterno.
Ecco un piccolo codice che mostra che espressioni imprecise con tipi misti possono essere pericolose (i risultati vengono ricevuti utilizzando Microsoft Visual C++ 2005 in modalità di compilazione a 64 bit):
int x = 100000;
int y = 100000;
int z = 100000;
intptr_t size = 1; // Result:
intptr_t v1 = x * y * z; // -1530494976
intptr_t v2 = intptr_t(x) * y * z; // 1000000000000000
intptr_t v3 = x * y * intptr_t(z); // 141006540800000
intptr_t v4 = size * x * y * z; // 1000000000000000
intptr_t v5 = x * y * z * size; // -1530494976
intptr_t v6 = size * (x * y * z); // -1530494976
intptr_t v7 = size * (x * y) * z; // 141006540800000
intptr_t v8 = ((size * x) * y) * z; // 1000000000000000
intptr_t v9 = size * (x * (y * z)); // -1530494976È necessario che tutti gli operandi in tali espressioni siano preventivamente convertiti in un tipo di dimensione maggiore. Ricorda che un'espressione come
intptr_t v2 = intptr_t(x) * y * z;non garantisce affatto un risultato corretto. Garantisce solo che l'espressione "intptr_t(x) * y * z" avrà il tipo intptr_t. Il risultato corretto mostrato da questa espressione nell'esempio non è altro che una buona fortuna.
3.12. Conversioni di tipi impliciti non sicure alle chiamate di funzione
Il pericolo di un uso misto di tipi memsize e non memsize può riguardare non solo le espressioni. Un esempio:
void foo(ptrdiff_t delta);
int i = -2;
unsigned k = 1;
foo(i + k);Sopra (vedi Aritmetica del puntatore errato) abbiamo discusso una situazione del genere. In questo caso si verifica un risultato errato a causa dell'estensione implicita di un argomento effettivo a 32 bit a 64 bit nel momento della chiamata della funzione.
3.13. Pericolose conversioni di tipo implicito alla restituzione del valore dalla funzione
La conversione di tipo implicito non sicura può verificarsi anche quando si utilizza l'operazione di ritorno. Un esempio:
extern int Width, Height, Depth;
size_t GetIndex(int x, int y, int z) {
return x + y * Width + z * Width * Height;
}
...
MyArray[GetIndex(x, y, z)] = 0.0f;Sebbene restituiamo il valore del tipo size_t, l'espressione "x + y * Width + z * Width * Height" viene calcolata con l'uso del tipo int. Quando si lavora con array di grandi dimensioni (più di elementi INT_MAX), questo codice si comporterà in modo errato e indirizzeremo altri elementi dell'array MyArray di quanto desiderassimo.
3.14. Eccezioni
La generazione e l'elaborazione di eccezioni con l'uso di tipi interi non è una buona pratica di programmazione nel linguaggio C++. Dovresti usare tipi più informativi per tali scopi, ad esempio classi derivate da std::exception classes. Ma a volte devi lavorare con un codice di qualità inferiore come nell'esempio:
char *ptr1;
char *ptr2;
try {
try {
throw ptr2 - ptr1;
}
catch (int) {
std::cout << "catch 1: on x86" << std::endl;
}
}
catch (ptrdiff_t) {
std::cout << "catch 2: on x64" << std::endl;
}Dovresti stare molto attento ed evitare la generazione e l'elaborazione di eccezioni con l'uso di tipi memsize in quanto può cambiare la logica di lavoro del programma.
3.15. Conversioni di tipo esplicito
Fai attenzione alle conversioni di tipo esplicito. Possono modificare la logica di esecuzione del programma quando le dimensioni dei tipi vengono modificate o causare la perdita di bit significativi. È difficile mostrare gli errori di tipo relativi alla conversione esplicita del tipo tramite esempi poiché variano molto e sono specifici per programmi diversi. Hai conosciuto alcuni di questi errori in precedenza. Ma nel complesso è utile esaminare tutte le conversioni di tipo esplicito in cui vengono utilizzati i tipi memsize.
3.16. Funzioni sovraccaricate
Durante il porting di programmi a 32 bit su una piattaforma a 64 bit è possibile che la logica di lavoro venga modificata e ciò è correlato all'utilizzo di funzioni sovraccaricate. Se una funzione è sovrapposta per valori a 32 e 64 bit, l'accesso ad essa con l'uso di un argomento di tipo memsize verrà tradotto in chiamate diverse su sistemi diversi.
Un tale cambiamento nella logica di lavoro può essere pericoloso. Un esempio è il salvataggio e la lettura del file di dati tramite un insieme di funzioni come:
class CMyFile {
...
void Write(__int32 &value);
void Write(__int64 &value);
};
CMyFile object;
SSIZE_T value;
object.Write(value);A seconda della modalità di compilazione (32 o 64 bit) questo codice scriverà nel file un numero diverso di byte che potrebbe causare la mancata compatibilità dei formati dei file.
3.17. Campi di bit
Se utilizzi campi di bit, dovresti tenere in considerazione che l'uso di tipi memsize causerà il cambiamento delle dimensioni delle strutture e dell'allineamento. Ma non è tutto. Consideriamo un esempio peculiare:
struct BitFieldStruct {
unsigned short a:15;
unsigned short b:13;
};
BitFieldStruct obj;
obj.a = 0x4000;
size_t addr = obj.a << 17; //Sign Extension
printf("addr 0x%Ix\n", addr);
//Output on 32-bit system: 0x80000000
//Output on 64-bit system: 0xffffffff80000000Fai attenzione che se compili questo codice per un sistema a 64 bit avrai l'estensione firmata in "addr =obj.a <<17;" espressione nonostante entrambe le variabili addr e obj.a non siano contrassegnate. Questa estensione firmata è determinata da regole di conversione del tipo che funzionano nel modo seguente:
1) obj.a membro della struttura viene convertito dal campo bit di tipo corto senza segno in tipo int. Otteniamo int type ma non unsigned int perché il campo a 15 bit viene inserito in un intero con segno a 32 bit.
2) L'espressione "obj.a <<17" ha un tipo int ma viene convertita in ptrdiff_t e quindi in size_t prima di essere assegnata alla variabile addr. L'estensione firmata si verifica nel momento della conversione da int a ptrdiff_t.
3.18. Utilizzo di valori rigorosamente definiti nel calcolo dei turni all'interno delle strutture
Può essere molto pericoloso quando si tenta di calcolare manualmente gli indirizzi dei campi all'interno delle strutture.
Tali azioni spesso causano la generazione di codice errato. La diagnosi di questo tipo di errori viene presentata nell'analizzatore di test C++ ma sfortunatamente è descritta male.
3.19. Uso di tipo lungo
L'uso di tipi lunghi nel codice multipiattaforma è teoricamente sempre pericoloso quando si trasferisce il codice da un sistema a 32 bit a uno a 64 bit. Questo perché il tipo lungo ha dimensioni diverse nei due modelli di dati più diffusi:LP64 e LLP64. Questo tipo di controllo implementa la ricerca di tutti i long nel codice delle applicazioni.
3.20. Uso di macro che impediscono al compilatore di controllare i tipi
Questo controllo è implementato in C++ Test a differenza di Viva64 e PC-Lint, ma tutte le macro si aprono e il controllo completo viene comunque eseguito. Ecco perché consideriamo che questo tipo di controllo è implementato anche in Viva64 e PC-Lint.
3.21. Overflow di array con dimensioni esplicitamente definite
A volte potresti trovare un overflow di un array che si verificherà durante il porting su un'architettura a 64 bit. Ad esempio:
struct A { long n, m; };
void foo(const struct A *p) {
static char buf[ 8 ]; // should have used sizeof
memcpy(buf, p, sizeof( struct A )); //Owerflow
...4. Efficienza degli analizzatori statici
È difficile parlare di efficienza di analizzatori statici. Di sicuro, la metodologia di analisi statica è molto utile e consente di rilevare più errori già in fase di scrittura del codice, il che riduce notevolmente il periodo di debug e test.
Ma dovresti ricordare che l'analisi statica del codice non ti aiuterà mai a rilevare tutti gli errori anche nella sfera concreta dell'analisi del codice a 64 bit. Elenchiamo i motivi principali:
1. Alcuni elementi del linguaggio C++ sono difficili da analizzare. Prima di tutto questo si riferisce al codice di classi generiche poiché lavorano con tipi di dati diversi usando le stesse costruzioni.
2. Gli errori che si verificano durante il porting di un programma a 32 bit su un sistema a 64 bit possono essere non solo nel codice stesso ma anche apparire indirettamente. Un buon esempio è la dimensione di uno stack che per impostazione predefinita non cambia ed è uguale a 1 MB in Visual Studio 2005/2008 durante la creazione di una versione a 64 bit di un progetto. Durante il funzionamento, il codice a 64 bit può riempire lo stack molto più del codice a 32 bit. Ciò è correlato alla crescita delle dimensioni dei puntatori e di altri oggetti, a un diverso allineamento. Di conseguenza, la versione di un programma a 64 bit potrebbe improvvisamente mancare dello stack durante il funzionamento.
3. Esistono errori algoritmici causati da alcune supposizioni relative alle dimensioni dei tipi che cambiano in un sistema a 64 bit.
4. Anche le biblioteche esterne possono contenere errori.
Questo elenco non è completo ma ci consente di affermare che alcuni errori possono essere rilevati solo all'avvio di un programma. In altre parole abbiamo bisogno di test di carico di applicazioni, sistemi di analisi dinamica (ad esempio, Compuware BoundsChecker), unit test, test manuali ecc.
Pertanto, solo un approccio complesso che utilizza strategie e strumenti diversi può garantire una buona qualità di un programma a 64 bit.
Dovresti anche capire che le critiche a cui abbiamo fatto riferimento sopra non riducono in alcun modo l'efficienza dell'analisi statica. L'analisi statica è il metodo più efficiente per rilevare gli errori durante il porting di codice a 32 bit su sistemi a 64 bit. Ti consente di rilevare la maggior parte degli errori in un tempo piuttosto breve. I vantaggi dell'analisi statica sono i seguenti:
1. Possibilità di controllare tutti i rami del codice indipendentemente dalla frequenza della loro esecuzione in condizioni reali.
2. Possibilità di effettuare il controllo già in fase di migrazione o sviluppo del codice. Ti consente di correggere molti errori prima del test e del debug. Risparmia un sacco di risorse e tempo. È risaputo che prima viene rilevato un errore, più economico è correggerlo.
3. Un analizzatore statico può rilevare costruzioni non sicure che un programmatore considera corrette nella misura in cui sono valide su sistemi a 32 bit.
4. L'analisi statica consente di valutare la qualità del codice dal punto di vista della sua correttezza per i sistemi a 64 bit e quindi fare il miglior piano di lavoro.
5. Un analizzatore specializzato Viva64 è leader nell'ambito della diagnosi del codice a 64 bit per OS Windows. Innanzitutto per il suo orientamento sul modello di dati LLP64 e anche perché in esso vengono implementate nuove regole diagnostiche specifiche [1].
Nell'ambito della diagnosi del codice a 64 bit per il sistema operativo della famiglia Unix dovrebbe essere data preferenza ad un analizzatore universale PC-Lint. Non puoi giudicare la sua leadership dalla tabella 3, ma implementa regole più importanti rispetto al test C++.
Riferimenti
- Evgeniy Ryzhkov. Viva64:elaborazione di applicazioni a 64 bit. http://www.viva64.comhttps://pvs-studio.com/en/blog/posts/cpp/a0002/
- Andrey Karpov. Problemi dimenticati nello sviluppo di programmi a 64 bit. http://www.viva64.comhttps://pvs-studio.com/en/blog/posts/cpp/a0010/
- Andrey Karpov, Evgeniy Ryzhkov. 20 problemi di porting del codice C++ sulla piattaforma a 64 bit. http://www.viva64.comhttps://pvs-studio.com/en/blog/posts/cpp/a0004/
- Andrey Karpov. Problemi di test di applicazioni a 64 bit. http://www.viva64.comhttps://pvs-studio.com/en/blog/posts/cpp/a0006/
- Andrey Karpov, Evgeniy Ryzhkov. Sviluppo di applicazioni ad alta intensità di risorse in ambiente Visual C++. http://www.viva64.comhttps://pvs-studio.com/en/blog/posts/a0018/