No, fintanto che ogni possibile osservatore nel sistema vede l'operazione come atomica, l'operazione può coinvolgere solo la cache.
Soddisfare questo requisito è molto più difficile per le operazioni atomiche di lettura-modifica-scrittura (come lock add [mem], eax , in particolare con un indirizzo non allineato), ovvero quando una CPU potrebbe asserire il segnale LOCK#. Ancora non vedresti altro nell'asm:l'hardware implementa la semantica richiesta da ISA per lock ed istruzioni.
Anche se dubito che ci sia un pin LOCK# esterno fisico sulle moderne CPU in cui il controller di memoria è integrato nella CPU, invece che in un chip Northbridge separato.
I compilatori non MFENCE per i carichi seq_cst.
Penso di aver letto che il vecchio MSVC a un certo punto ha emesso MFENCE per questo (forse per impedire il riordino con negozi NT non recintati? O invece che nei negozi?). Ma non è più così:ho testato MSVC 19.00.23026.0. Cerca foo e bar nell'output di asm di questo programma che esegue il dump del proprio asm in un sito di compilazione ed esecuzione online.
Il motivo per cui non abbiamo bisogno di un recinto qui è che il modello di memoria x86 non consente il riordino di LoadStore e LoadLoad. I negozi precedenti (non seq_cst) possono comunque essere ritardati fino a dopo un caricamento seq_cst, quindi è diverso dall'utilizzo di un std::atomic_thread_fence(mo_seq_cst); autonomo prima di un X.load(mo_acquire);
È coerente con la tua idea che il caricamento richiedeva mfence; l'uno o l'altro dei carichi o dei negozi seq_cst necessita di una barriera completa per impedire il riordino di StoreLoad che potrebbe altrimenti avvenire.
In pratica gli sviluppatori del compilatore hanno scelto carichi economici (mov) / negozi costosi (mov+mfence) perché i carichi sono più comuni. Mapping C++11 ai processori .
(Il modello x86 di ordinamento della memoria è l'ordine del programma più un buffer del negozio con inoltro del negozio (vedi anche). Questo rende mo_acquire e mo_release gratuito in asm, serve solo a bloccare il riordino in fase di compilazione e ci permette di scegliere se mettere la barriera completa MFENCE sui carichi o sui negozi.)
Quindi i negozi seq_cst sono mov +mfence o xchg . Perché un negozio std::atomic con consistenza sequenziale utilizza XCHG? discute i vantaggi in termini di prestazioni di xchg su alcune CPU. Su AMD, MFENCE è (IIRC) documentato per avere una semantica extra serialize-the-pipeline (per l'esecuzione delle istruzioni, non solo per l'ordinamento della memoria) che blocca l'exec fuori ordine, e in pratica su alcune CPU Intel (Skylake) è anche il caso.
L'asm di MSVC per i negozi è lo stesso di Clang, usando xchg per fare il negozio + barriera di memoria con la stessa istruzione.
Il rilascio atomico o i negozi rilassati possono essere solo mov , con la differenza tra loro che è solo la quantità di riordino in fase di compilazione consentita.
Questa domanda assomiglia alla parte 2 del tuo precedente modello di memoria in C++:consistenza sequenziale e atomicità, in cui hai chiesto:
Come hai sottolineato nella domanda, l'atomicità non è correlata all'ordinamento rispetto a qualsiasi altra operazione. (cioè memory_order_relaxed ). Significa solo che l'operazione avviene come una singola operazione indivisibile, da cui il nome, non come più parti che possono avvenire in parte prima e in parte dopo qualcos'altro.
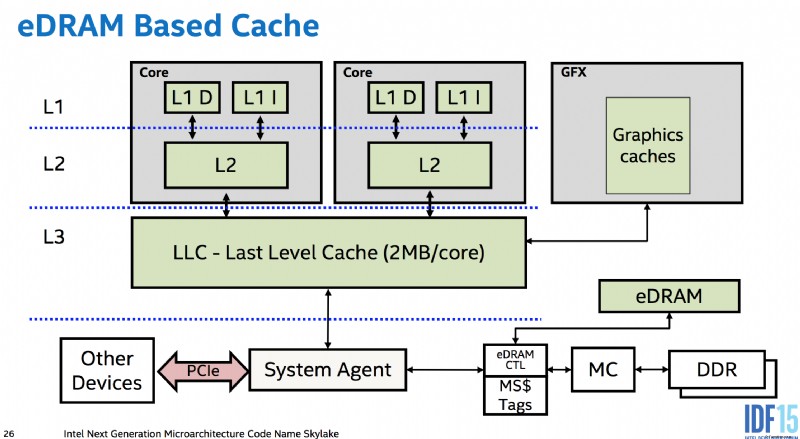
Ottieni l'atomicità "gratuitamente" senza hardware aggiuntivo per carichi allineati o archivi fino alla dimensione dei percorsi dati tra core, memoria e bus I/O come PCIe. cioè tra i vari livelli di cache e tra le cache di core separati. I controller di memoria fanno parte della CPU nei design moderni, quindi anche un dispositivo PCIe che accede alla memoria deve passare attraverso l'agente di sistema della CPU. (Ciò consente anche all'eDRAM L4 di Skylake (non disponibile in nessuna CPU desktop :()) di funzionare come cache lato memoria (a differenza di Broadwell, che la utilizzava come cache vittima per L3 IIRC), posizionandosi tra la memoria e tutto il resto nel sistema, quindi può persino memorizzare nella cache DMA).
Ciò significa che l'hardware della CPU può fare tutto il necessario per assicurarsi che un archivio o un caricamento sia atomico rispetto a qualsiasi cosa altro nel sistema che può osservarlo. Questo probabilmente non è molto, se non altro. La memoria DDR utilizza un bus dati sufficientemente ampio da consentire a un archivio allineato a 64 bit di passare elettricamente attraverso il bus di memoria alla DRAM, tutto nello stesso ciclo. (Fatto divertente, ma non importante. Un protocollo bus seriale come PCIe non impedirebbe che sia atomico, purché un singolo messaggio sia abbastanza grande. E poiché il controller di memoria è l'unica cosa che può parlare direttamente con la DRAM, non importa cosa fa internamente, solo la dimensione dei trasferimenti tra esso e il resto della CPU). Ma comunque, questa è la parte "gratuita":non è necessario alcun blocco temporaneo di altre richieste per mantenere atomico un trasferimento atomico.
x86 garantisce che i carichi allineati e gli archivi fino a 64 bit siano atomici, ma non accessi più ampi. Le implementazioni a basso consumo sono libere di suddividere i carichi/archivi vettoriali in blocchi a 64 bit come ha fatto P6 da PIII fino al Pentium M.
Le operazioni atomiche avvengono nella cache
Ricorda che atomico significa semplicemente che tutti gli osservatori lo vedono come accaduto o non accaduto, mai parzialmente accaduto. Non è necessario che raggiunga effettivamente la memoria principale immediatamente (o del tutto, se sovrascritta a breve). La modifica o la lettura atomica della cache L1 è sufficiente per garantire che qualsiasi altro accesso core o DMA vedrà un archivio o un caricamento allineato come una singola operazione atomica. Va bene se questa modifica avviene molto tempo dopo l'esecuzione del negozio (ad es. ritardata dall'esecuzione fuori ordine fino al ritiro del negozio).
Le moderne CPU come Core2 con percorsi a 128 bit ovunque in genere hanno carichi/archivi atomici SSE 128b, andando oltre ciò che garantisce l'ISA x86. Ma nota l'interessante eccezione su un Opteron multi-presa probabilmente dovuta all'ipertrasporto. Questa è la prova che la modifica atomica della cache L1 non è sufficiente per fornire l'atomicità per gli archivi più ampi del percorso dati più stretto (che in questo caso non è il percorso tra la cache L1 e le unità di esecuzione).
L'allineamento è importante :Un caricamento o un archivio che attraversa un limite della linea della cache deve essere eseguito in due accessi separati. Questo lo rende non atomico.
x86 garantisce che gli accessi memorizzati nella cache fino a 8 byte siano atomici purché non superino un limite di 8B su AMD/Intel. (O per Intel solo su P6 e versioni successive, non oltrepassare il limite della linea di cache). Ciò implica che intere linee di cache (64B sulle moderne CPU) vengono trasferite atomicamente su Intel, anche se è più ampio dei percorsi dati (32B tra L2 e L3 su Haswell/Skylake). Questa atomicità non è totalmente "gratuita" nell'hardware e forse richiede una logica aggiuntiva per impedire a un carico di leggere una riga della cache che è stata trasferita solo parzialmente. Sebbene i trasferimenti della riga della cache avvengano solo dopo che la vecchia versione è stata invalidata, quindi un core non dovrebbe leggere dalla vecchia copia mentre è in corso un trasferimento. AMD può in pratica strappare limiti più piccoli, forse a causa dell'utilizzo di un'estensione diversa da MESI in grado di trasferire dati sporchi tra le cache.
Per operandi più ampi, come la scrittura atomica di nuovi dati in più voci di uno struct, è necessario proteggerlo con un blocco rispettato da tutti gli accessi. (Potresti essere in grado di utilizzare x86 lock cmpxchg16b con un ciclo di tentativi per eseguire un negozio atomico 16b. Nota che non c'è modo di emularlo senza un mutex.)
Lettura-modifica-scrittura atomica è dove diventa più difficile
correlato:la mia risposta su Può num++ essere atomico per 'int num'? entra più in dettaglio su questo.
Ogni core ha una cache L1 privata che è coerente con tutti gli altri core (usando il protocollo MOESI). Le linee di cache vengono trasferite tra i livelli di cache e memoria principale in blocchi di dimensioni comprese tra 64 bit e 256 bit. (questi trasferimenti potrebbero effettivamente essere atomici su una granularità dell'intera linea di cache?)
Per eseguire un RMW atomico, un core può mantenere una riga della cache L1 nello stato modificato senza accettare modifiche esterne alla riga della cache interessata tra il carico e l'archivio, il resto del sistema vedrà l'operazione come atomica. (E così è atomico, perché le normali regole di esecuzione fuori ordine richiedono che il thread locale veda il proprio codice come eseguito nell'ordine del programma.)
Può farlo non elaborando alcun messaggio di coerenza della cache mentre l'RMW atomico è in volo (o una versione più complicata di questo che consente un maggiore parallelismo per altre operazioni).
lock non allineato ed ops sono un problema:abbiamo bisogno di altri core per vedere che le modifiche a due linee di cache avvengano come una singola operazione atomica. Questo potrebbe richiedere effettivamente l'archiviazione su DRAM e il blocco del bus. (Il manuale di ottimizzazione di AMD dice che questo è ciò che accade sulle loro CPU quando un blocco della cache non è sufficiente.)