Questo e i prossimi post riguarderanno probabilmente la preoccupazione più importante nella programmazione:la gestione delle risorse. Le linee guida di base del C++ contengono regole per la gestione delle risorse in generale, ma anche regole per l'allocazione e la deallocazione e i puntatori intelligenti in particolare. Oggi inizierò con le regole generali di gestione delle risorse.

All'inizio. Che cos'è una risorsa? Una risorsa è qualcosa che devi gestire. Ciò significa che devi acquisirlo e rilasciarlo perché le risorse sono limitate o devi proteggerle. Puoi avere solo una quantità limitata di memoria, socket, processi o thread; solo un processo può scrivere un file condiviso o un thread può scrivere una variabile condivisa in un determinato momento. Se non segui il protocollo, sono possibili molti problemi.
Il tuo sistema potrebbe
- perdi memoria perché perdi memoria.
- fai una corsa ai dati perché dimentichi di acquisire un blocco prima di utilizzare la variabile condivisa.
- hai un deadlock perché stai acquisendo e rilasciando alcune variabili condivise in una sequenza diversa.
I problemi con la corsa ai dati e i blocchi dei dati non sono univoci per le variabili condivise. Ad esempio, puoi avere gli stessi problemi con i file.
Se pensi alla gestione delle risorse, tutto si riduce a un punto chiave:la proprietà. Quindi lascia che ti dia prima il quadro generale prima di scrivere sulle regole.
Quello che mi piace in particolare del moderno C++, è che possiamo esprimere direttamente la nostra intenzione sulla proprietà nel codice.
- Oggetti locali . Il runtime C++ come proprietario gestisce automaticamente la durata di queste risorse. Lo stesso vale per oggetti globali o membri di una classe. Le linee guida li chiamano oggetti con ambito.
- Riferimenti :Non sono il proprietario. Ho preso in prestito solo la risorsa che non può essere vuota.
- Puntatori grezzi :Non sono il proprietario. Ho preso in prestito solo la risorsa che può essere vuota. Non devo eliminare la risorsa.
- std::unique_ptr :Sono il proprietario esclusivo della risorsa. Posso rilasciare esplicitamente la risorsa.
- std::ptr_condiviso :Condivido la risorsa con altri ptr condivisi. Posso rilasciare esplicitamente la mia proprietà condivisa.
- std::weak_ptr :Non sono il proprietario della risorsa ma posso diventare temporaneamente il proprietario condiviso della risorsa utilizzando il metodo std::weak_ptr::lock.
Confronta questa semantica di proprietà a grana fine con un semplice puntatore grezzo. Ora sai cosa mi piace del moderno C++.
Ecco il riepilogo delle regole per la gestione delle risorse.
- R.1:Gestisci le risorse automaticamente utilizzando gli handle delle risorse e RAII (Resource Acquisition Is Initialization)
- R.2:Nelle interfacce, usa i puntatori grezzi per denotare singoli oggetti (solo)
- R.3:Un puntatore grezzo (un
T*) non è proprietario - R.4:Un riferimento grezzo (un
T&) non è proprietario - R.5:Preferisci gli oggetti con ambito, non allocare l'heap inutilmente
- R.6:Evita il non
constvariabili globali
Diamo un'occhiata a ciascuno di essi in dettaglio.
R.1:Gestisci automaticamente le risorse utilizzando gli handle di risorsa e RAII (L'acquisizione delle risorse è l'inizializzazione)
L'idea è abbastanza semplice. Crei una specie di oggetto proxy per la tua risorsa. Il costruttore del proxy acquisirà la risorsa e il distruttore rilascerà la risorsa. L'idea chiave di RAII è che il runtime C++ è il proprietario dell'oggetto locale e quindi della risorsa.
Due esempi tipici di RAII nel moderno C++ sono i puntatori intelligenti e i blocchi. Il puntatore intelligente si prende cura della loro memoria e i lucchetti si prendono cura dei loro mutex.
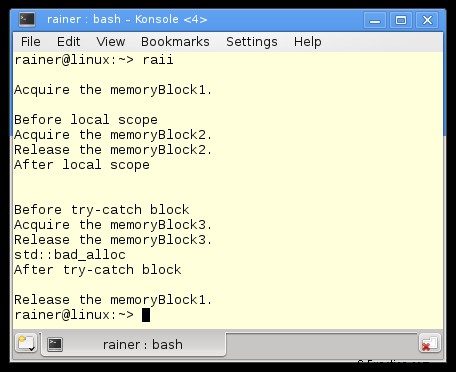
La seguente classe ResourceGuard modella RAII.
// raii.cpp
#include <iostream>
#include <new>
#include <string>
class ResourceGuard{
private:
const std::string resource;
public:
ResourceGuard(const std::string& res):resource(res){
std::cout << "Acquire the " << resource << "." << std::endl;
}
~ResourceGuard(){
std::cout << "Release the "<< resource << "." << std::endl;
}
};
int main(){
std::cout << std::endl;
ResourceGuard resGuard1{"memoryBlock1"}; // (1)
std::cout << "\nBefore local scope" << std::endl;
{
ResourceGuard resGuard2{"memoryBlock2"}; // (2)
}
std::cout << "After local scope" << std::endl;
std::cout << std::endl;
std::cout << "\nBefore try-catch block" << std::endl;
try{
ResourceGuard resGuard3{"memoryBlock3"}; // (3)
throw std::bad_alloc();
}
catch (std::bad_alloc& e){
std::cout << e.what();
}
std::cout << "\nAfter try-catch block" << std::endl;
std::cout << std::endl;
}
Non fa differenza se la durata delle istanze di ResourceGuard termina regolarmente (1) e (2) o irregolarmente (3). Il distruttore di ResourceGuard verrà sempre chiamato. Ciò significa che la risorsa verrà rilasciata.
Se vuoi conoscere maggiori dettagli sull'esempio e su RAII, leggi il mio post:Garbage Collection - No grazie. Anche Bjarne Stroustrup ha fatto un commento.
R.2:Nelle interfacce, usa i puntatori non elaborati per denotare singoli oggetti (solo )
I puntatori grezzi non dovrebbero denotare array perché questo è molto soggetto a errori. Questo diventa, in particolare, vero se la tua funzione accetta un puntatore come argomento.
void f(int* p, int n) // n is the number of elements in p[]
{
// ...
p[2] = 7; // bad: subscript raw pointer
// ...
}
È abbastanza facile passare il lato sbagliato dell'array come argomento.
Per gli array, abbiamo contenitori come std::vector. Un contenitore della Standard Template Library è un proprietario esclusivo. Acquisisce e rilascia automaticamente la sua memoria.
R.3:Un puntatore grezzo (a T* ) non è proprietario
La questione della proprietà diventa particolarmente interessante se si dispone di una fabbrica. Una factory è una funzione speciale che restituisce un nuovo oggetto. Ora la domanda è. Dovresti restituire un puntatore non elaborato, un oggetto, uno std::unique_ptr o uno std::shared_ptr?
Ecco le quattro varianti:
Widget* makeWidget(int n){ // (1)
auto p = new Widget{n};
// ...
return p;
}
Widget makeWidget(int n){ // (2)
Widget g{n};
// ...
return g;
}
std::unique_ptr<Widget> makeWidget(int n){ // (3)
auto u = std::make_unique<Widget>(n);
// ...
return u;
}
std::shared_ptr<Widget> makeWidget(int n){ // (4)
auto s = std::make_shared<Widget>(n);
// ...
return s;
}
...
auto widget = makeWidget(10);
Chi dovrebbe essere il proprietario del widget? Il chiamante o il chiamato? Presumo che tu non possa rispondere alla domanda per il puntatore nell'esempio. Anche io. Ciò significa che non abbiamo idea di chi dovrebbe chiamare delete. Al contrario, i casi da (2) a (4) sono abbastanza ovvi. Nel caso dell'oggetto o dello std::unique_ptr, il chiamante è il proprietario. Nel caso di std::shared_ptr, il chiamante e il chiamato condividono la proprietà.
Rimane una domanda. Dovresti andare con un oggetto o un puntatore intelligente. Ecco i miei pensieri.
- Se la tua fabbrica deve essere polimorfa come un costruttore virtuale, devi usare un puntatore intelligente. Ho già scritto di questo caso d'uso speciale. Leggi i dettagli nel post:C++ Core Guidelines:Constructors (C.50).
- Se l'oggetto è poco costoso da copiare e il chiamante dovrebbe essere il proprietario del widget, usa un oggetto. Se non è economico da copiare, usa uno std::unique_ptr.
- Se il chiamato vuole gestire la durata del widget, usa un std::shared_ptr
R.4:Un riferimento grezzo (a T& ) non è proprietario
Non c'è niente da aggiungere. Un riferimento grezzo non è proprietario e non può essere vuoto.
R.5:Preferisci gli oggetti con ambito, non allocare l'heap inutilmente
Un oggetto con ambito è un oggetto con il suo ambito. Può essere un oggetto locale, un oggetto globale o un membro. Il runtime C++ si occupa dell'oggetto. Non ci sono allocazioni e deallocazioni di memoria coinvolte e non possiamo ottenere un'eccezione std::bad_alloc. Per semplificare:se possibile, usa un oggetto con ambito.
R.6:Evita non-const variabili globali
Sento spesso dire:le variabili globali sono cattive. Non è del tutto vero. Le variabili globali non cost sono negative. Ci sono molte ragioni per evitare variabili globali non cost. Ecco alcuni motivi. Presumo per ragioni di semplicità che le funzioni o gli oggetti utilizzino variabili globali non const.
- Incapsulamento :le funzioni o gli oggetti potrebbero essere modificati al di fuori del loro ambito. Ciò significa che è abbastanza difficile pensare al tuo codice.
- Testabilità: Non puoi testare la tua funzione in isolamento. L'effetto della tua funzione dipende dallo stato del tuo programma.
- Refactoring: È abbastanza difficile refactoring del codice se non riesci a pensare alla tua funzione in isolamento.
- Ottimizzazione: Non è possibile riorganizzare facilmente le chiamate di funzione o eseguire le chiamate di funzione su thread diversi perché potrebbero esserci dipendenze nascoste.
- Concorrenza: La condizione necessaria per avere una corsa ai dati è uno stato condiviso e mutevole. Le variabili globali non cost sono stati mutevoli condivisi.
Cosa c'è dopo?
Nel prossimo post scriverò di una risorsa molto importante:la memoria.