Soluzione per AVX2 qual è il modo più efficiente per fare le valigie in base a una maschera?
è riportato di seguito:
Se hai un array di input e un array di output, ma vuoi solo scrivere quegli elementi che soddisfano una certa condizione, quale sarebbe il modo più efficiente per farlo in AVX2?
Ho visto in SSE dove è stato fatto in questo modo:
(Da:https://deplinenoise.files.wordpress.com/2015/03/gdc2015_afredriksson_simd.pdf)
__m128i LeftPack_SSSE3(__m128 mask, __m128 val)
{
// Move 4 sign bits of mask to 4-bit integer value.
int mask = _mm_movemask_ps(mask);
// Select shuffle control data
__m128i shuf_ctrl = _mm_load_si128(&shufmasks[mask]);
// Permute to move valid values to front of SIMD register
__m128i packed = _mm_shuffle_epi8(_mm_castps_si128(val), shuf_ctrl);
return packed;
}
Questo sembra andare bene per SSE che è largo 4, e quindi necessita solo di una LUT a 16 voci, ma per AVX che è largo 8, la LUT diventa piuttosto grande (256 voci, ciascuna 32 byte o 8k).
Sono sorpreso che AVX non sembri avere un'istruzione per semplificare questo processo, come un negozio mascherato con imballaggio.
Penso che con un po' di rimescolamento per contare il numero di bit di segno impostato a sinistra potresti generare la tabella di permutazione necessaria e quindi chiamare _mm256_permutevar8x32_ps. Ma credo che anche queste siano alcune istruzioni..
Qualcuno sa di qualche trucco per farlo con AVX2? O qual è il metodo più efficiente?
Ecco un'illustrazione del problema dell'imballaggio sinistro dal documento sopra:
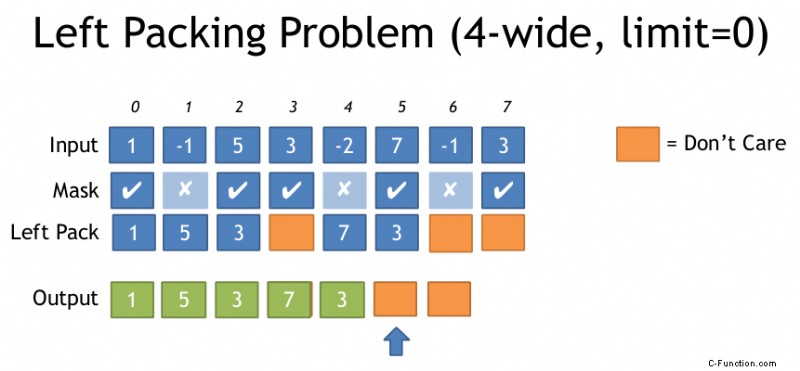
Grazie
AVX2 + BMI2. Vedi la mia altra risposta per AVX512. (Aggiornamento:salvato un pdep nelle build a 64 bit.)
Possiamo usare AVX2 vpermps (_mm256_permutevar8x32_ps ) (o l'equivalente intero, vpermd ) per eseguire un cambio di corsia variabile.
Possiamo generare maschere al volo , dal BMI2 pext (Estratto di bit paralleli) ci fornisce una versione bit per bit dell'operazione di cui abbiamo bisogno.
Attenzione a quel pdep /pext sono molto lento sulle CPU AMD prima di Zen 3, come 6 uops / 18 cicli di latenza e throughput su Ryzen Zen 1 e Zen 2 . Questa implementazione funzionerà in modo orribile su quelle CPU AMD. Per AMD, potresti essere il migliore con vettori a 128 bit usando un pshufb o vpermilps LUT, o alcuni dei suggerimenti di spostamento variabile AVX2 discussi nei commenti. Soprattutto se l'input della maschera è una maschera vettoriale (non una maschera di bit già compressa dalla memoria).
AMD prima di Zen2 ha comunque solo unità di esecuzione vettoriale a 128 bit e gli shuffle di attraversamento di corsia a 256 bit sono lenti. Quindi i vettori a 128 bit sono molto interessanti per questo su Zen 1. Ma Zen 2 ha unità di caricamento/store ed esecuzione a 256 bit. (E ancora pext/pdep microcodificato lento.)
Per vettori interi con elementi a 32 bit o più grandi :O 1) _mm256_movemask_ps(_mm256_castsi256_ps(compare_mask)) .
Oppure 2) usa _mm256_movemask_epi8 e quindi modificare la prima costante PDEP da 0x0101010101010101 a 0x0F0F0F0F0F0F0F0F per scatter blocchi di 4 bit contigui. Modifica la moltiplicazione per 0xFFU in expanded_mask |= expanded_mask<<4; o expanded_mask *= 0x11; (Non testato). In ogni caso, usa la maschera shuffle con VPERMD invece di VPERMPS.
Per numero intero a 64 bit o double elementi, tutto funziona ancora e basta; La maschera di confronto ha sempre coppie di elementi a 32 bit che sono gli stessi, quindi lo shuffle risultante mette entrambe le metà di ciascun elemento a 64 bit nel posto giusto. (Quindi usi ancora VPERMPS o VPERMD, perché VPERMPD e VPERMQ sono disponibili solo con operandi di controllo immediati.)
Per elementi a 16 bit, potresti essere in grado di adattarlo con vettori a 128 bit.
Per gli elementi a 8 bit, vedi Generazione efficiente di maschere di mescolamento sse per elementi di byte compressi a sinistra per un trucco diverso, memorizzando il risultato in più blocchi possibilmente sovrapposti.
L'algoritmo:
Inizia con una costante di indici a 3 bit compressi, con ogni posizione con il proprio indice. cioè [ 7 6 5 4 3 2 1 0 ] dove ogni elemento è largo 3 bit. 0b111'110'101'...'010'001'000 .
Usa pext per estrarre gli indici che vogliamo in una sequenza contigua in fondo a un registro intero. per esempio. se vogliamo gli indici 0 e 2, la nostra maschera di controllo per pext dovrebbe essere 0b000'...'111'000'111 . pext prenderà il 010 e 000 gruppi di indici che si allineano con i bit 1 nel selettore. I gruppi selezionati vengono compressi nei bit bassi dell'output, quindi l'output sarà 0b000'...'010'000 . (cioè [ ... 2 0 ] )
Vedi il codice commentato per come generare il 0b111000111 inserisci pext dalla maschera del vettore di input.
Ora siamo nella stessa barca della LUT compressa:spacchetta fino a 8 indici compressi.
Quando metti insieme tutti i pezzi, ci sono tre pext in totale /pdep S. Ho lavorato a ritroso rispetto a quello che volevo, quindi probabilmente è più facile capirlo anche in quella direzione. (vale a dire iniziare con la linea casuale e tornare indietro da lì.)
Possiamo semplificare la decompressione se lavoriamo con indici uno per byte invece che in gruppi compressi a 3 bit . Poiché abbiamo 8 indici, questo è possibile solo con codice a 64 bit.
Guarda questa e una versione solo a 32 bit su Godbolt Compiler Explorer. Ho usato #ifdef s quindi compila in modo ottimale con -m64 o -m32 . gcc spreca alcune istruzioni, ma clang crea un codice davvero carino.
#include <stdint.h>
#include <immintrin.h>
// Uses 64bit pdep / pext to save a step in unpacking.
__m256 compress256(__m256 src, unsigned int mask /* from movmskps */)
{
uint64_t expanded_mask = _pdep_u64(mask, 0x0101010101010101); // unpack each bit to a byte
expanded_mask *= 0xFF; // mask |= mask<<1 | mask<<2 | ... | mask<<7;
// ABC... -> AAAAAAAABBBBBBBBCCCCCCCC...: replicate each bit to fill its byte
const uint64_t identity_indices = 0x0706050403020100; // the identity shuffle for vpermps, packed to one index per byte
uint64_t wanted_indices = _pext_u64(identity_indices, expanded_mask);
__m128i bytevec = _mm_cvtsi64_si128(wanted_indices);
__m256i shufmask = _mm256_cvtepu8_epi32(bytevec);
return _mm256_permutevar8x32_ps(src, shufmask);
}
Questo viene compilato in codice senza carichi dalla memoria, solo costanti immediate. (Vedi il link Godbolt per questa e la versione a 32 bit).
# clang 3.7.1 -std=gnu++14 -O3 -march=haswell
mov eax, edi # just to zero extend: goes away when inlining
movabs rcx, 72340172838076673 # The constants are hoisted after inlining into a loop
pdep rax, rax, rcx # ABC -> 0000000A0000000B....
imul rax, rax, 255 # 0000000A0000000B.. -> AAAAAAAABBBBBBBB..
movabs rcx, 506097522914230528
pext rax, rcx, rax
vmovq xmm1, rax
vpmovzxbd ymm1, xmm1 # 3c latency since this is lane-crossing
vpermps ymm0, ymm1, ymm0
ret
(Il clang successivo viene compilato come GCC, con mov/shl/sub invece di imul, vedi sotto.)
Quindi, secondo i numeri di Agner Fog e https://uops.info/, questo è 6 uops (senza contare le costanti, o il movimento con estensione zero che scompare quando è inline). Su Intel Haswell, è 16c di latenza (1 per vmovq, 3 per ogni pdep/imul/pext / vpmovzx / vpermps). Non c'è parallelismo a livello di istruzione. In un ciclo in cui questo non fa parte di una dipendenza trasportata dal ciclo, tuttavia, (come quella che ho incluso nel collegamento Godbolt), si spera che il collo di bottiglia sia solo il throughput, mantenendo più iterazioni in volo contemporaneamente.
Questo può forse gestire un throughput di uno ogni 4 cicli, con colli di bottiglia sulla porta1 per pdep/pext/imul più popcnt nel ciclo. Naturalmente, con carichi/negozi e altri carichi di lavoro (inclusi confronto e movmsk), anche il throughput totale di uop può essere facilmente un problema.
per esempio. il loop del filtro nel mio link godbolt è 14 uops con clang, con -fno-unroll-loops per facilitarne la lettura. Potrebbe sostenere un'iterazione per 4c, tenendo il passo con il front-end, se siamo fortunati.
clang 6 e precedenti hanno creato una dipendenza di loop con popcnt è una falsa dipendenza dal suo output, quindi creerà un collo di bottiglia su 3/5 della latenza del compress256 funzione. clang 7.0 e versioni successive usano xor-zeroing per interrompere la falsa dipendenza (invece di usare solo popcnt edx,edx o qualcosa come fa GCC :/).
gcc (e successivamente clang) moltiplica per 0xFF con più istruzioni, usando uno spostamento a sinistra per 8 e un sub , invece di imul di 255. Ciò richiede 3 uop totali contro 1 per il front-end, ma la latenza è di soli 2 cicli, rispetto a 3. (Haswell gestisce mov in fase di ridenominazione del registro con latenza zero.) Soprattutto per questo, imul può funzionare solo sulla porta 1, in competizione con pdep/pext/popcnt, quindi è probabilmente bene evitare quel collo di bottiglia.
Poiché tutto l'hardware che supporta AVX2 supporta anche BMI2, probabilmente non ha senso fornire una versione per AVX2 senza BMI2.
Se è necessario eseguire questa operazione in un ciclo molto lungo, la LUT probabilmente ne vale la pena se i mancati errori di cache iniziali vengono ammortizzati su un numero sufficiente di iterazioni con il sovraccarico inferiore dovuto alla semplice decompressione della voce LUT. Devi ancora movmskps , quindi puoi aprire la maschera e usarla come indice LUT, ma salvi un pdep/imul/pexp.
Puoi decomprimere le voci LUT con la stessa sequenza intera che ho usato, ma set1() di @Froglegs / vpsrlvd / vpand è probabilmente migliore quando la voce LUT inizia in memoria e non ha bisogno di entrare nei registri di interi in primo luogo. (Un carico di trasmissione a 32 bit non ha bisogno di un ALU uop su CPU Intel). Tuttavia, uno spostamento variabile è di 3 uops su Haswell (ma solo 1 su Skylake).
Vedi la mia altra risposta per AVX2+BMI2 senza LUT.
Dato che hai menzionato una preoccupazione sulla scalabilità di AVX512:non preoccuparti, c'è un'istruzione AVX512F esattamente per questo :
VCOMPRESSPS — Archivia valori a virgola mobile a precisione singola compressi in una memoria densa. (Ci sono anche versioni per elementi double e interi a 32 o 64 bit (vpcompressq ), ma non byte o parola (16 bit)). È come BMI2 pdep / pext , ma per elementi vettoriali invece di bit in un intero reg.
La destinazione può essere un registro vettoriale o un operando di memoria, mentre la sorgente è un registro vettoriale e una maschera. Con un registro dest, può unire o azzerare i bit superiori. Con una destinazione di memoria, "Solo il vettore contiguo viene scritto nella posizione di memoria di destinazione".
Per capire fino a che punto far avanzare il tuo puntatore per il prossimo vettore, apri la maschera.
Diciamo che vuoi filtrare tutto tranne i valori>=0 da un array:
#include <stdint.h>
#include <immintrin.h>
size_t filter_non_negative(float *__restrict__ dst, const float *__restrict__ src, size_t len) {
const float *endp = src+len;
float *dst_start = dst;
do {
__m512 sv = _mm512_loadu_ps(src);
__mmask16 keep = _mm512_cmp_ps_mask(sv, _mm512_setzero_ps(), _CMP_GE_OQ); // true for src >= 0.0, false for unordered and src < 0.0
_mm512_mask_compressstoreu_ps(dst, keep, sv); // clang is missing this intrinsic, which can't be emulated with a separate store
src += 16;
dst += _mm_popcnt_u64(keep); // popcnt_u64 instead of u32 helps gcc avoid a wasted movsx, but is potentially slower on some CPUs
} while (src < endp);
return dst - dst_start;
}
Questo compila (con gcc4.9 o successivo) in (Godbolt Compiler Explorer):
# Output from gcc6.1, with -O3 -march=haswell -mavx512f. Same with other gcc versions
lea rcx, [rsi+rdx*4] # endp
mov rax, rdi
vpxord zmm1, zmm1, zmm1 # vpxor xmm1, xmm1,xmm1 would save a byte, using VEX instead of EVEX
.L2:
vmovups zmm0, ZMMWORD PTR [rsi]
add rsi, 64
vcmpps k1, zmm0, zmm1, 29 # AVX512 compares have mask regs as a destination
kmovw edx, k1 # There are some insns to add/or/and mask regs, but not popcnt
movzx edx, dx # gcc is dumb and doesn't know that kmovw already zero-extends to fill the destination.
vcompressps ZMMWORD PTR [rax]{k1}, zmm0
popcnt rdx, rdx
## movsx rdx, edx # with _popcnt_u32, gcc is dumb. No casting can get gcc to do anything but sign-extend. You'd expect (unsigned) would mov to zero-extend, but no.
lea rax, [rax+rdx*4] # dst += ...
cmp rcx, rsi
ja .L2
sub rax, rdi
sar rax, 2 # address math -> element count
ret
Prestazioni:i vettori a 256 bit potrebbero essere più veloci su Skylake-X / Cascade Lake
In teoria, un loop che carica una bitmap e filtra un array in un altro dovrebbe funzionare a 1 vettore ogni 3 clock su SKX / CSLX, indipendentemente dalla larghezza del vettore, con un collo di bottiglia sulla porta 5. (kmovb/w/d/q k1, eax gira su p5 e vcompressps in memoria è 2p5 + un negozio, secondo IACA e testato da http://uops.info/).
@ZachB segnala nei commenti che, in pratica, è un ciclo che utilizza ZMM _mm512_mask_compressstoreu_ps è leggermente più lento di _mm256_mask_compressstoreu_ps su hardware CSLX reale. (Non sono sicuro che si trattasse di un microbenchmark che consentirebbe alla versione a 256 bit di uscire dalla "modalità vettoriale a 512 bit" e di aumentare il clock, o se ci fosse un codice a 512 bit circostante.)
Sospetto che i negozi disallineati stiano danneggiando la versione a 512 bit. vcompressps probabilmente esegue effettivamente un archivio vettoriale mascherato a 256 o 512 bit e, se supera il limite di una riga della cache, deve fare un lavoro extra . Poiché il puntatore di output in genere non è un multiplo di 16 elementi, un archivio a 512 bit a riga intera sarà quasi sempre disallineato.
Per qualche motivo, gli archivi a 512 bit disallineati possono essere peggiori degli archivi a 256 bit suddivisi in linee di cache, oltre a verificarsi più spesso; sappiamo già che la vettorizzazione a 512 bit di altre cose sembra essere più sensibile all'allineamento. Ciò potrebbe essere dovuto semplicemente all'esaurimento dei buffer di carico diviso quando si verificano ogni volta, o forse il meccanismo di fallback per la gestione delle divisioni della riga della cache è meno efficiente per i vettori a 512 bit.
Sarebbe interessante confrontare vcompressps in un registro, con negozi separati e completamente vettoriali sovrapposti . Probabilmente è la stessa cosa, ma il negozio può microfondersi quando si tratta di un'istruzione separata. E se c'è qualche differenza tra negozi mascherati e negozi sovrapposti, questo lo rivelerebbe.
Un'altra idea discussa nei commenti qui sotto è stata l'utilizzo di vpermt2ps per costruire vettori completi per negozi allineati. Questo sarebbe difficile da fare senza ramificazioni, e la ramificazione quando riempiamo un vettore probabilmente prevederà erroneamente a meno che la maschera di bit non abbia uno schema abbastanza regolare o grandi esecuzioni di tutto-0 e tutto-1.
Potrebbe essere possibile un'implementazione branchless con una catena di dipendenze trasportata da loop di 4 o 6 cicli attraverso il vettore in costruzione, con un vpermt2ps e una miscela o qualcosa per sostituirlo quando è "pieno". Con un vettore allineato memorizza ogni iterazione, ma spostando il puntatore di output solo quando il vettore è pieno.
Questo è probabilmente più lento di vcompressps con archivi non allineati sulle attuali CPU Intel.
Se stai prendendo di mira AMD Zen, questo metodo potrebbe essere preferito, a causa del pdepand pext molto lento su ryzen (18 cicli ciascuno).
Ho escogitato questo metodo, che utilizza una LUT compressa, che è 768 (+1 padding) byte, invece di 8k. Richiede una trasmissione di un singolo valore scalare, che viene quindi spostato di una quantità diversa in ciascuna corsia, quindi mascherato ai 3 bit inferiori, che fornisce una LUT 0-7.
Ecco la versione intrinseca, insieme al codice per compilare LUT.
//Generate Move mask via: _mm256_movemask_ps(_mm256_castsi256_ps(mask)); etc
__m256i MoveMaskToIndices(u32 moveMask) {
u8 *adr = g_pack_left_table_u8x3 + moveMask * 3;
__m256i indices = _mm256_set1_epi32(*reinterpret_cast<u32*>(adr));//lower 24 bits has our LUT
// __m256i m = _mm256_sllv_epi32(indices, _mm256_setr_epi32(29, 26, 23, 20, 17, 14, 11, 8));
//now shift it right to get 3 bits at bottom
//__m256i shufmask = _mm256_srli_epi32(m, 29);
//Simplified version suggested by wim
//shift each lane so desired 3 bits are a bottom
//There is leftover data in the lane, but _mm256_permutevar8x32_ps only examines the first 3 bits so this is ok
__m256i shufmask = _mm256_srlv_epi32 (indices, _mm256_setr_epi32(0, 3, 6, 9, 12, 15, 18, 21));
return shufmask;
}
u32 get_nth_bits(int a) {
u32 out = 0;
int c = 0;
for (int i = 0; i < 8; ++i) {
auto set = (a >> i) & 1;
if (set) {
out |= (i << (c * 3));
c++;
}
}
return out;
}
u8 g_pack_left_table_u8x3[256 * 3 + 1];
void BuildPackMask() {
for (int i = 0; i < 256; ++i) {
*reinterpret_cast<u32*>(&g_pack_left_table_u8x3[i * 3]) = get_nth_bits(i);
}
}
Ecco l'assembly generato da MSVC:
lea ecx, DWORD PTR [rcx+rcx*2]
lea rax, OFFSET FLAT:unsigned char * g_pack_left_table_u8x3 ; g_pack_left_table_u8x3
vpbroadcastd ymm0, DWORD PTR [rcx+rax]
vpsrlvd ymm0, ymm0, YMMWORD PTR [email protected]
Aggiungerà ulteriori informazioni a un'ottima risposta di @PeterCordes:https://stackoverflow.com/a/36951611/5021064.
Ho eseguito le implementazioni di std::remove dallo standard C++ per i tipi interi con esso. L'algoritmo, una volta che puoi eseguire la compressione, è relativamente semplice:caricare un registro, comprimere, archiviare. Per prima cosa mostrerò le variazioni e poi i benchmark.
Ho finito con due variazioni significative sulla soluzione proposta:
__m128iregistri, qualsiasi tipo di elemento, utilizzando_mm_shuffle_epi8istruzioni__m256iregistri, tipo di elemento di almeno 4 byte, utilizzando_mm256_permutevar8x32_epi32
Quando i tipi sono più piccoli di 4 byte per un registro a 256 bit, li divido in due registri a 128 bit e li comprimo/memorizzo separatamente.
Collegamento all'esploratore del compilatore dove puoi vedere l'assembly completo (c'è un using type e width (in elementi per confezione) in basso, che puoi collegare per ottenere diverse varianti):https://gcc.godbolt.org/z/yQFR2t
NOTA:il mio codice è in C++17 e utilizza un wrapper simd personalizzato, quindi non so quanto sia leggibile. Se vuoi leggere il mio codice -> la maggior parte è dietro il link in alto include su godbolt. In alternativa, tutto il codice è su github.
Le implementazioni di @PeterCordes rispondono a entrambi i casi
Nota:insieme alla maschera, calcolo anche il numero di elementi rimanenti usando il popcount. Forse c'è un caso in cui non è necessario, ma non l'ho ancora visto.
Maschera per _mm_shuffle_epi8
- Scrivi un indice per ogni byte in mezzo byte:
0xfedcba9876543210 - Ricevi coppie di indici in 8 cortometraggi racchiusi in
__m128i - Distribuiscili usando
x << 4 | x & 0x0f0f
Esempio di diffusione degli indici. Diciamo che vengono selezionati il 7° e il 6° elemento.
Significa che lo short corrispondente sarebbe:0x00fe . Dopo << 4 e | otterremmo 0x0ffe . E poi cancelliamo il secondo f .
Codice maschera completo:
// helper namespace
namespace _compress_mask {
// mmask - result of `_mm_movemask_epi8`,
// `uint16_t` - there are at most 16 bits with values for __m128i.
inline std::pair<__m128i, std::uint8_t> mask128(std::uint16_t mmask) {
const std::uint64_t mmask_expanded = _pdep_u64(mmask, 0x1111111111111111) * 0xf;
const std::uint8_t offset =
static_cast<std::uint8_t>(_mm_popcnt_u32(mmask)); // To compute how many elements were selected
const std::uint64_t compressed_idxes =
_pext_u64(0xfedcba9876543210, mmask_expanded); // Do the @PeterCordes answer
const __m128i as_lower_8byte = _mm_cvtsi64_si128(compressed_idxes); // 0...0|compressed_indexes
const __m128i as_16bit = _mm_cvtepu8_epi16(as_lower_8byte); // From bytes to shorts over the whole register
const __m128i shift_by_4 = _mm_slli_epi16(as_16bit, 4); // x << 4
const __m128i combined = _mm_or_si128(shift_by_4, as_16bit); // | x
const __m128i filter = _mm_set1_epi16(0x0f0f); // 0x0f0f
const __m128i res = _mm_and_si128(combined, filter); // & 0x0f0f
return {res, offset};
}
} // namespace _compress_mask
template <typename T>
std::pair<__m128i, std::uint8_t> compress_mask_for_shuffle_epi8(std::uint32_t mmask) {
auto res = _compress_mask::mask128(mmask);
res.second /= sizeof(T); // bit count to element count
return res;
}
Maschera per _mm256_permutevar8x32_epi32
Questa è quasi una soluzione per una @PeterCordes:l'unica differenza è _pdep_u64 bit (lo suggerisce come una nota).
La maschera che ho scelto è 0x5555'5555'5555'5555 . L'idea è:ho 32 bit di mmask, 4 bit per ciascuno degli 8 numeri interi. Ho 64 bit che voglio ottenere => devo convertire ogni bit di 32 bit in 2 => quindi 0101b =5. Anche il moltiplicatore cambia da 0xff a 3 perché otterrò 0x55 per ogni intero, non 1.
Codice maschera completo:
// helper namespace
namespace _compress_mask {
// mmask - result of _mm256_movemask_epi8
inline std::pair<__m256i, std::uint8_t> mask256_epi32(std::uint32_t mmask) {
const std::uint64_t mmask_expanded = _pdep_u64(mmask, 0x5555'5555'5555'5555) * 3;
const std::uint8_t offset = static_cast<std::uint8_t(_mm_popcnt_u32(mmask)); // To compute how many elements were selected
const std::uint64_t compressed_idxes = _pext_u64(0x0706050403020100, mmask_expanded); // Do the @PeterCordes answer
// Every index was one byte => we need to make them into 4 bytes
const __m128i as_lower_8byte = _mm_cvtsi64_si128(compressed_idxes); // 0000|compressed indexes
const __m256i expanded = _mm256_cvtepu8_epi32(as_lower_8byte); // spread them out
return {expanded, offset};
}
} // namespace _compress_mask
template <typename T>
std::pair<__m256i, std::uint8_t> compress_mask_for_permutevar8x32(std::uint32_t mmask) {
static_assert(sizeof(T) >= 4); // You cannot permute shorts/chars with this.
auto res = _compress_mask::mask256_epi32(mmask);
res.second /= sizeof(T); // bit count to element count
return res;
}
Benchmark
Processore:Intel Core i7 9700K (una moderna CPU di livello consumer, nessun supporto AVX-512)
Compiler:clang, build from trunk vicino alla versione 10
Opzioni del compilatore:--std=c++17 --stdlib=libc++ -g -Werror -Wall -Wextra -Wpedantic -O3 -march=native -mllvm -align-all-functions=7
Libreria di micro-benchmark:google benchmark
Controllo per l'allineamento del codice:
Se non hai familiarità con il concetto, leggi questo o guarda questo
Tutte le funzioni nel binario del benchmark sono allineate al limite di 128 byte. Ogni funzione di benchmarking viene duplicata 64 volte, con una diapositiva noop diversa all'inizio della funzione (prima di entrare nel ciclo). I numeri principali che mostro sono minimi per ogni misurazione. Penso che funzioni poiché l'algoritmo è inline. Sono anche convalidato dal fatto che ottengo risultati molto diversi. In fondo alla risposta mostro l'impatto dell'allineamento del codice.
Nota:codice di benchmarking. BENCH_DECL_ATTRIBUTES è solo noinline
Il benchmark rimuove una certa percentuale di 0 da un array. Testi gli array con {0, 5, 20, 50, 80, 95, 100} percento di zero.
Testo 3 dimensioni:40 byte (per vedere se è utilizzabile per array davvero piccoli), 1000 byte e 10.000 byte. Raggruppo per dimensione perché SIMD dipende dalla dimensione dei dati e non da un numero di elementi. Il conteggio degli elementi può essere derivato da una dimensione dell'elemento (1000 byte è 1000 caratteri ma 500 short e 250 int). Poiché il tempo necessario per il codice non simd dipende principalmente dal conteggio degli elementi, le vincite dovrebbero essere maggiori per i caratteri.
Grafici:x – percentuale di zeri, y – tempo in nanosecondi. padding :min indica che questo è il minimo tra tutti gli allineamenti.
40 byte di dati, 40 caratteri
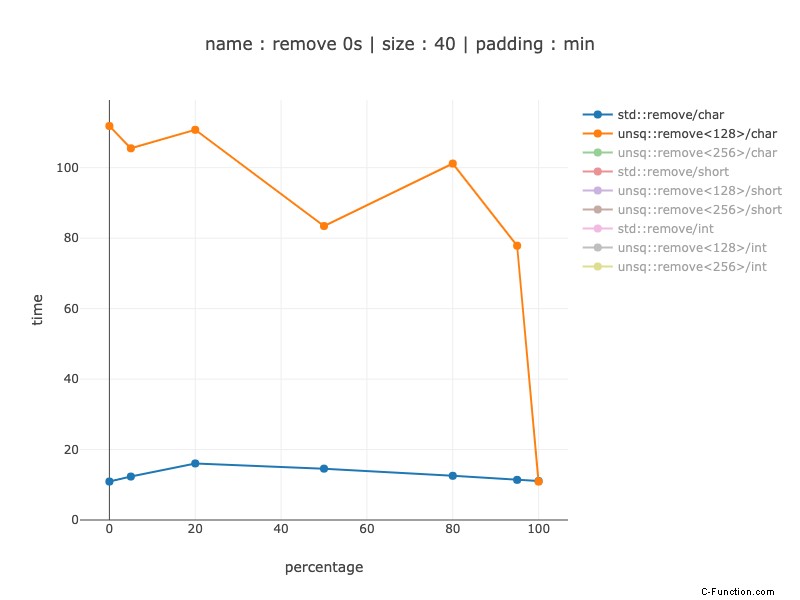
Per 40 byte questo non ha senso nemmeno per i caratteri:la mia implementazione diventa circa 8-10 volte più lenta quando si utilizzano registri a 128 bit su codice non simd. Quindi, ad esempio, il compilatore dovrebbe fare attenzione a farlo.
1000 byte di dati, 1000 caratteri
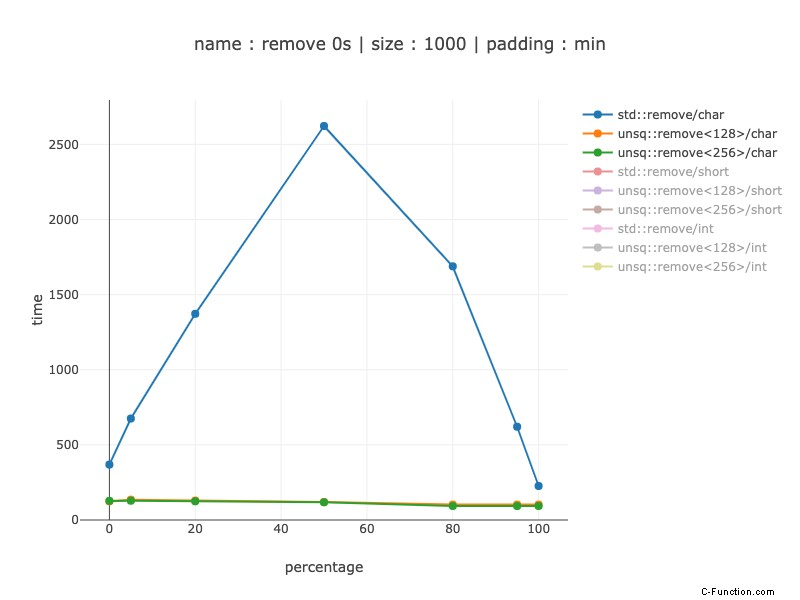
Apparentemente la versione non simd è dominata dalla previsione del ramo:quando otteniamo una piccola quantità di zeri otteniamo una velocità inferiore:per nessun 0 – circa 3 volte, per il 5% di zeri – circa 5-6 volte accelera. Perché quando il predittore di ramo non può aiutare la versione non sim, c'è un'accelerazione di circa 27 volte. È una proprietà interessante del codice simd che le sue prestazioni tendono a dipendere molto meno dai dati. L'utilizzo del registro 128 vs 256 non mostra praticamente alcuna differenza, poiché la maggior parte del lavoro è ancora suddivisa in 2 128 registri.
1000 byte di dati, 500 cortocircuiti
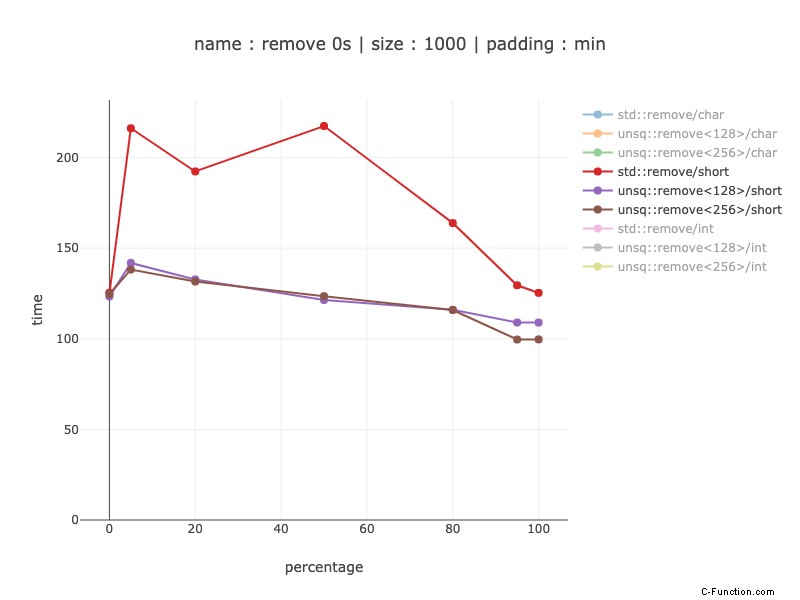
Risultati simili per i cortometraggi tranne che con un guadagno molto più piccolo - fino a 2 volte.
Non so perché i cortometraggi lo fanno molto meglio dei caratteri per il codice non sim:mi aspetto che i cortometraggi siano due volte più veloci, poiché ci sono solo 500 cortometraggi, ma la differenza è in realtà fino a 10 volte.
1000 byte di dati, 250 int
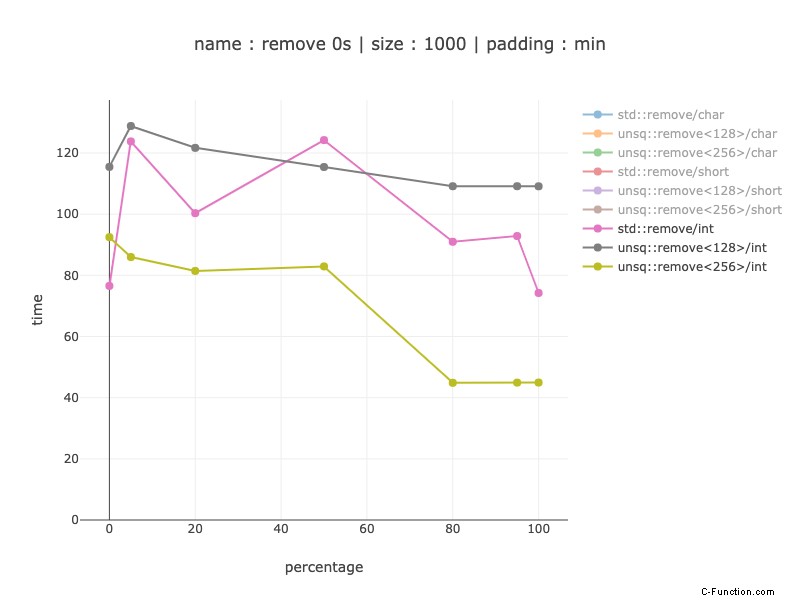
Per un 1000 solo una versione a 256 bit ha senso:20-30% di vincita senza 0 esclusi per rimuovere ciò che è così (previsione del ramo perfetta, nessuna rimozione per codice non sim).
10.000 byte di dati, 10.000 caratteri
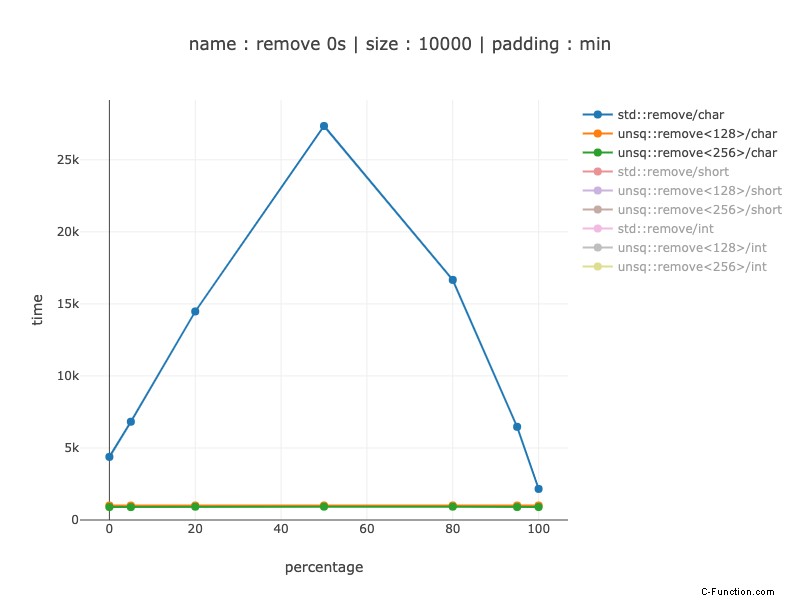
Lo stesso ordine di grandezza vince come per 1000 caratteri:da 2-6 volte più veloce quando il predittore di ramo è utile a 27 volte quando non lo è.
Stesse trame, solo versioni simd:
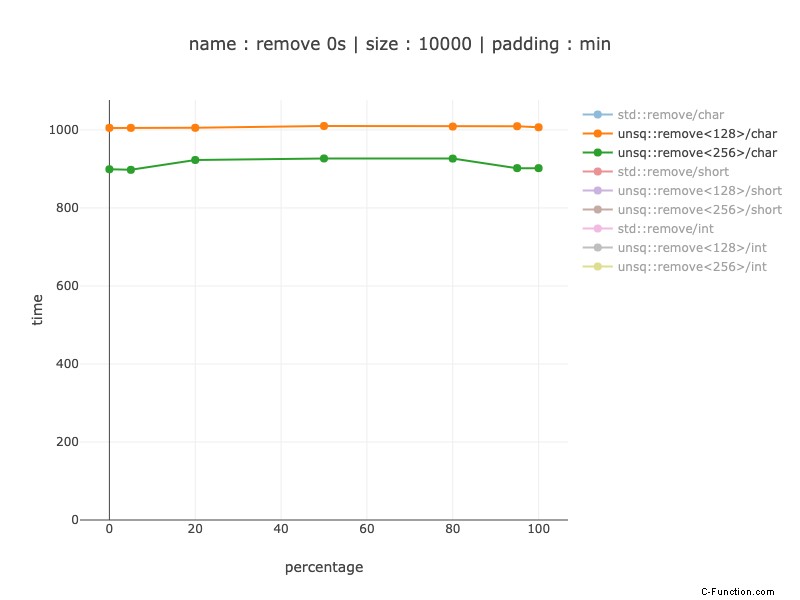
Qui possiamo vedere una vincita del 10% dall'utilizzo di registri a 256 bit e dalla loro divisione in 2 registri da 128 bit:circa il 10% più veloce. In termini di dimensioni cresce da 88 a 129 istruzioni, il che non è molto, quindi potrebbe avere senso a seconda del caso d'uso. Per la linea di base, la versione non Simd contiene 79 istruzioni (per quanto ne so, queste sono però più piccole di quelle SIMD).
10.000 byte di dati, 5.000 short
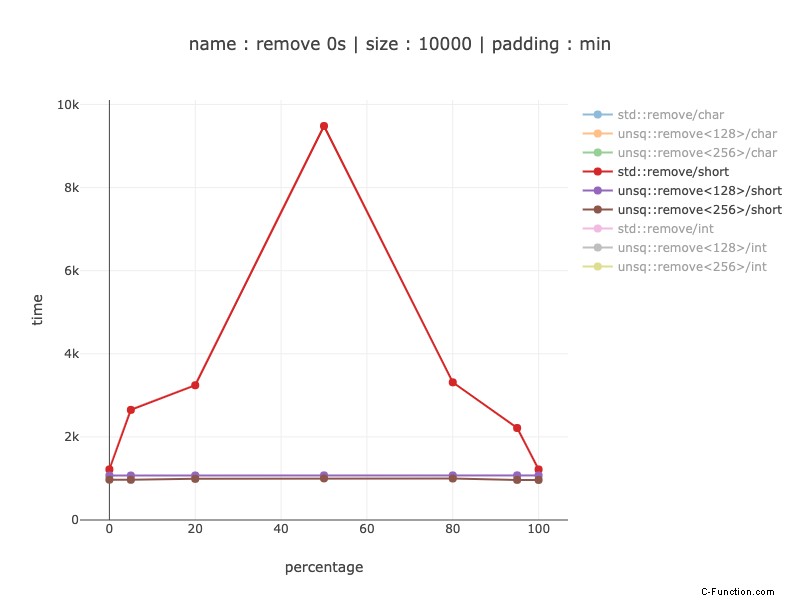
Dal 20% a 9 volte vincono, a seconda della distribuzione dei dati. Non mostra il confronto tra i registri a 256 e 128 bit:è quasi lo stesso assembly dei caratteri e la stessa vittoria per 256 bit uno di circa il 10%.
10.000 byte di dati, 2.500 int
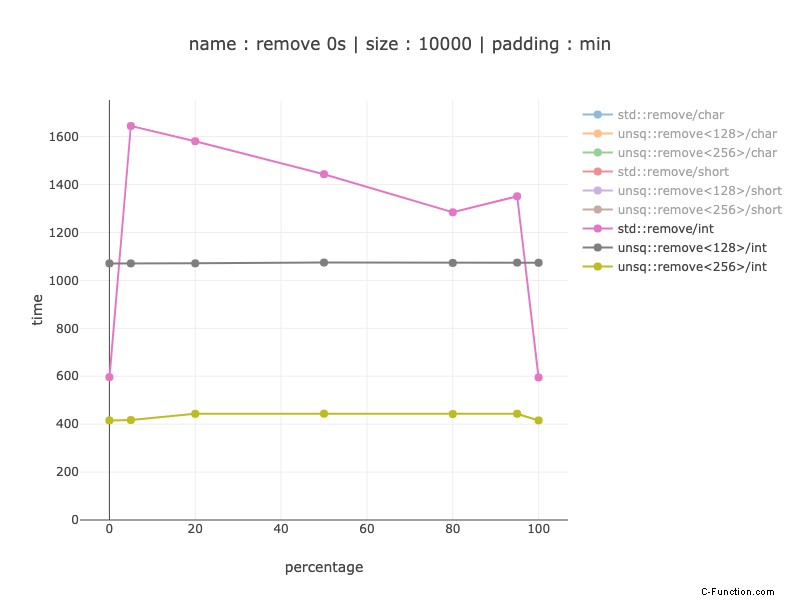
Sembra avere molto senso usare registri a 256 bit, questa versione è circa 2 volte più veloce rispetto ai registri a 128 bit. Quando si confronta con un codice non simd, da una vincita del 20% con una previsione del ramo perfetta a 3,5 - 4 volte non appena non lo è.
Conclusione:quando si dispone di una quantità sufficiente di dati (almeno 1000 byte) questa può essere un'ottimizzazione molto utile per un processore moderno senza AVX-512
PS:
Sulla percentuale di elementi da rimuovere
Da un lato è raro filtrare metà dei tuoi elementi. D'altra parte un algoritmo simile può essere utilizzato nella partizione durante l'ordinamento => che in realtà dovrebbe avere una selezione del ramo del ~50%.
Impatto sull'allineamento del codice
La domanda è:quanto vale, se il codice è mal allineato
(in generale, c'è ben poco da fare al riguardo).
Sto mostrando solo per 10.000 byte.
I grafici hanno due righe per min e per max per ogni punto percentuale (il che significa che non è un allineamento di codice migliore/peggiore, è il miglior allineamento di codice per una determinata percentuale).
Impatto sull'allineamento del codice – non Simd
Caratteri:
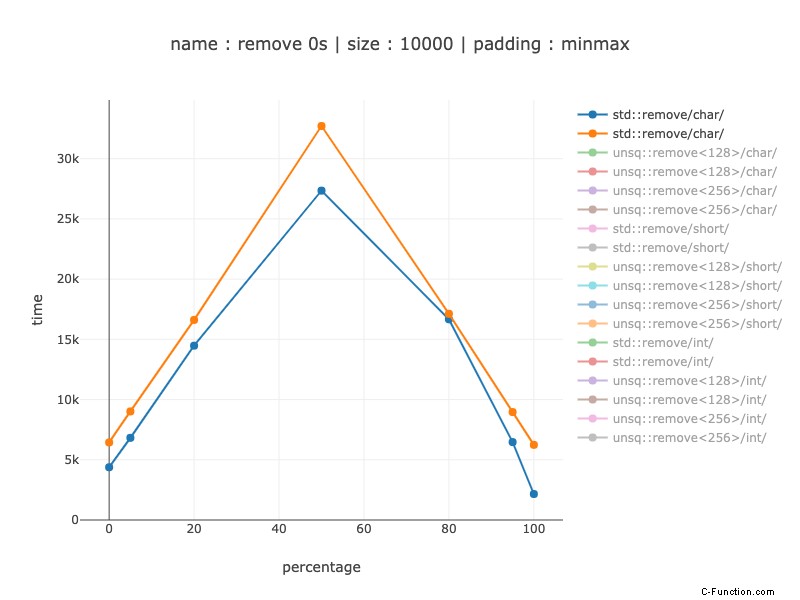
Dal 15-20% per una previsione di filiale scadente a 2-3 volte quando la previsione di filiale ha aiutato molto. (è noto che il predittore di diramazione è influenzato dall'allineamento del codice).
Pantaloncini:
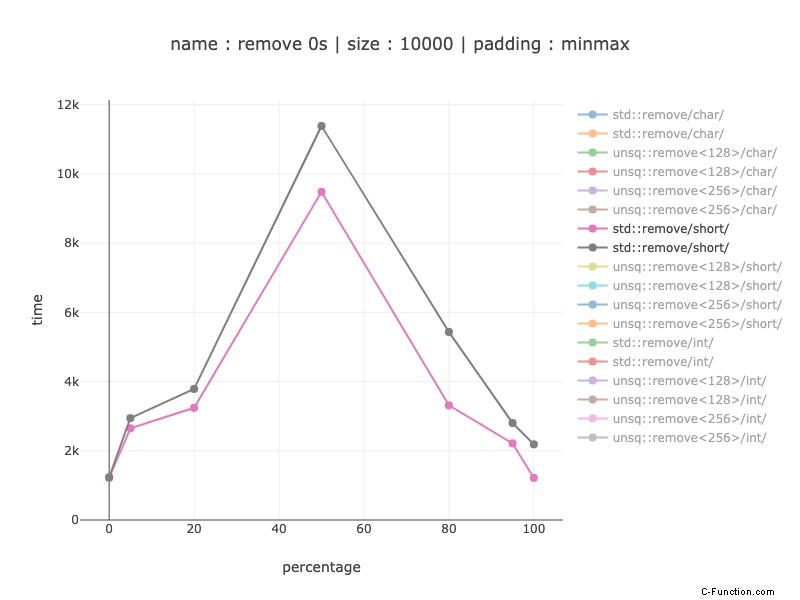
Per qualche ragione, lo 0 percento non è affatto influenzato. Può essere spiegato da std::remove prima eseguendo la ricerca lineare per trovare il primo elemento da rimuovere. Apparentemente la ricerca lineare dei cortometraggi non è influenzata.
Oltre a questo, dal 10% a 1,6-1,8 volte il valore
Int:
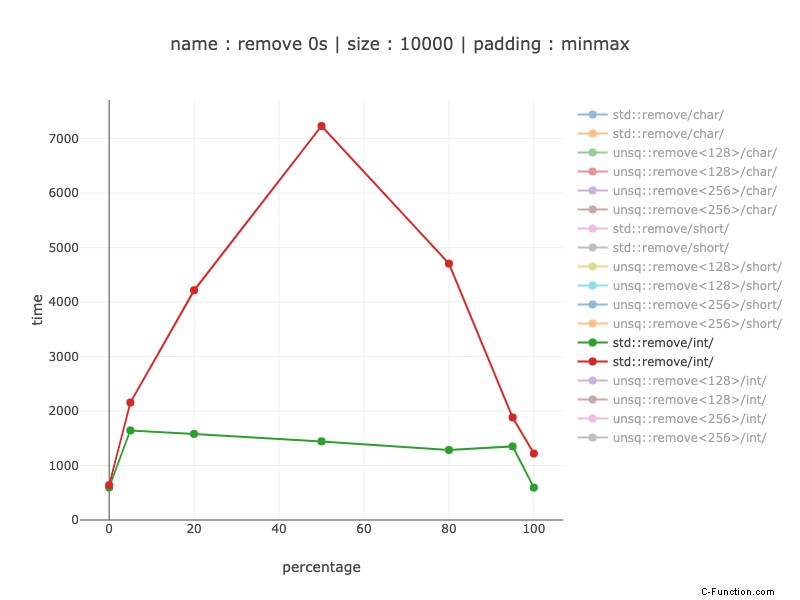
Come per i cortometraggi:nessuno 0 non è interessato. Non appena entriamo nella rimozione della parte, va da 1,3 volte a 5 volte il valore dell'allineamento migliore.
Impatto sull'allineamento del codice - versioni simd
Non mostra shorts e ints 128, poiché è quasi lo stesso assembly dei caratteri
Caratteri – registro a 128 bit
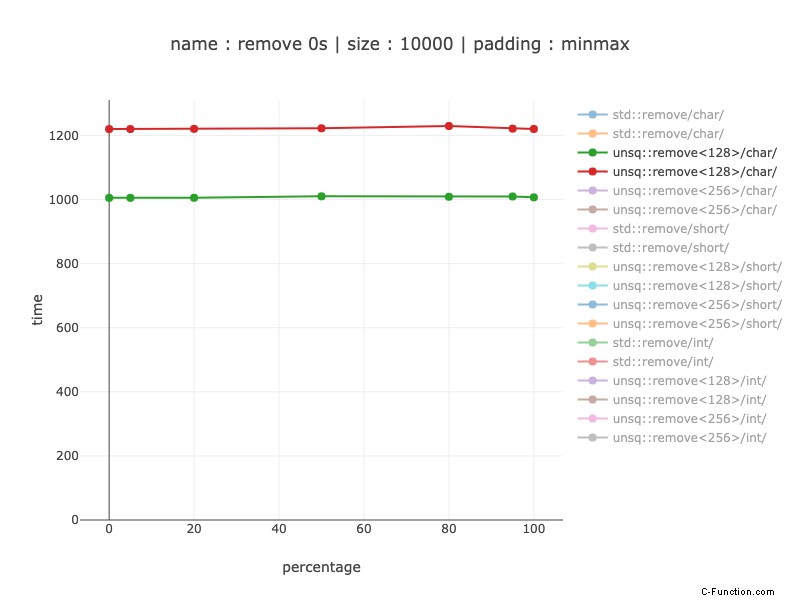
Circa 1,2 volte più lento
Caratteri – registro a 256 bit
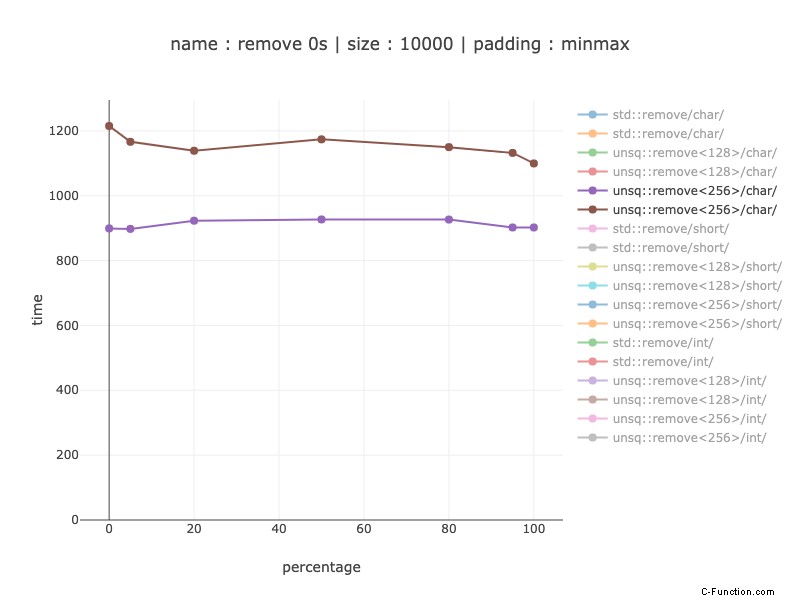
Circa 1,1 – 1,24 volte più lento
Ints:registro a 256 bit
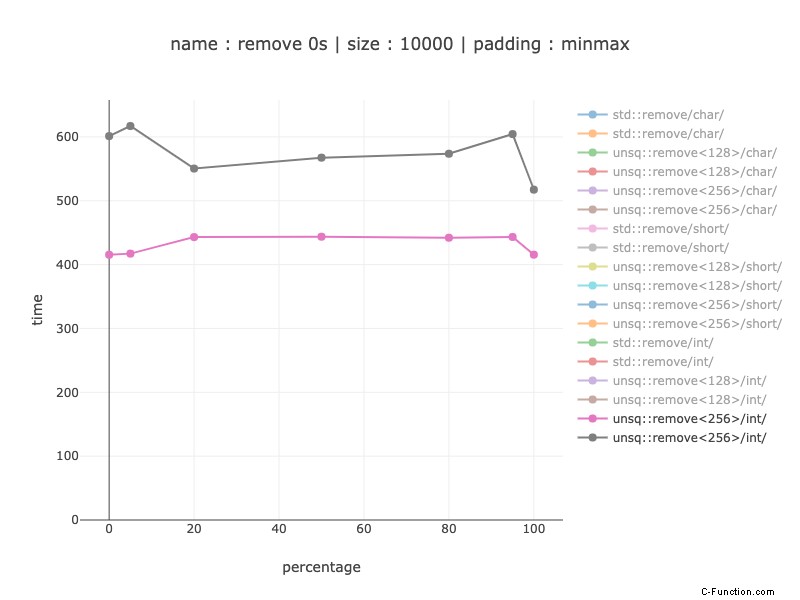
1,25 – 1,35 volte più lento
Possiamo vedere che per la versione simd dell'algoritmo, l'allineamento del codice ha un impatto significativamente minore rispetto alla versione non simd. Sospetto che ciò sia dovuto praticamente alla mancanza di filiali.
Nel caso in cui qualcuno sia interessato, ecco una soluzione per SSE2 che utilizza un'istruzione LUT invece di una data LUT alias una tabella di salto. Tuttavia, con AVX sarebbero necessari 256 casi.
Ogni volta che chiami LeftPack_SSE2 di seguito utilizza essenzialmente tre istruzioni:jmp, shufps, jmp. Cinque dei sedici casi non hanno bisogno di modificare il vettore.
static inline __m128 LeftPack_SSE2(__m128 val, int mask) {
switch(mask) {
case 0:
case 1: return val;
case 2: return _mm_shuffle_ps(val,val,0x01);
case 3: return val;
case 4: return _mm_shuffle_ps(val,val,0x02);
case 5: return _mm_shuffle_ps(val,val,0x08);
case 6: return _mm_shuffle_ps(val,val,0x09);
case 7: return val;
case 8: return _mm_shuffle_ps(val,val,0x03);
case 9: return _mm_shuffle_ps(val,val,0x0c);
case 10: return _mm_shuffle_ps(val,val,0x0d);
case 11: return _mm_shuffle_ps(val,val,0x34);
case 12: return _mm_shuffle_ps(val,val,0x0e);
case 13: return _mm_shuffle_ps(val,val,0x38);
case 14: return _mm_shuffle_ps(val,val,0x39);
case 15: return val;
}
}
__m128 foo(__m128 val, __m128 maskv) {
int mask = _mm_movemask_ps(maskv);
return LeftPack_SSE2(val, mask);
}
Questo è forse un po' in ritardo anche se di recente mi sono imbattuto in questo problema esatto e ho trovato una soluzione alternativa che utilizzava un'implementazione rigorosamente AVX. Se non ti interessa se gli elementi decompressi vengono scambiati con gli ultimi elementi di ciascun vettore, anche questo potrebbe funzionare. Quella che segue è una versione AVX:
inline __m128 left_pack(__m128 val, __m128i mask) noexcept
{
const __m128i shiftMask0 = _mm_shuffle_epi32(mask, 0xA4);
const __m128i shiftMask1 = _mm_shuffle_epi32(mask, 0x54);
const __m128i shiftMask2 = _mm_shuffle_epi32(mask, 0x00);
__m128 v = val;
v = _mm_blendv_ps(_mm_permute_ps(v, 0xF9), v, shiftMask0);
v = _mm_blendv_ps(_mm_permute_ps(v, 0xF9), v, shiftMask1);
v = _mm_blendv_ps(_mm_permute_ps(v, 0xF9), v, shiftMask2);
return v;
}
In sostanza, ogni elemento in val viene spostato una volta a sinistra utilizzando il campo di bit, 0xF9 per fondersi con la sua variante non spostata. Successivamente, entrambe le versioni spostate e non spostate vengono unite alla maschera di input (che ha il primo elemento diverso da zero trasmesso attraverso i restanti elementi 3 e 4). Ripeti questo processo altre due volte, trasmettendo il secondo e il terzo elemento di mask ai suoi elementi successivi su ogni iterazione e questo dovrebbe fornire una versione AVX del _pdep_u32() Istruzione BMI2.
Se non hai AVX, puoi facilmente sostituire ogni _mm_permute_ps() con _mm_shuffle_ps() per una versione compatibile con SSE4.1.
E se stai usando la doppia precisione, ecco una versione aggiuntiva per AVX2:
inline __m256 left_pack(__m256d val, __m256i mask) noexcept
{
const __m256i shiftMask0 = _mm256_permute4x64_epi64(mask, 0xA4);
const __m256i shiftMask1 = _mm256_permute4x64_epi64(mask, 0x54);
const __m256i shiftMask2 = _mm256_permute4x64_epi64(mask, 0x00);
__m256d v = val;
v = _mm256_blendv_pd(_mm256_permute4x64_pd(v, 0xF9), v, shiftMask0);
v = _mm256_blendv_pd(_mm256_permute4x64_pd(v, 0xF9), v, shiftMask1);
v = _mm256_blendv_pd(_mm256_permute4x64_pd(v, 0xF9), v, shiftMask2);
return v;
}
Inoltre _mm_popcount_u32(_mm_movemask_ps(val)) può essere utilizzato per determinare il numero di elementi rimasti dopo l'imballaggio a sinistra.