Penso che il divario tra a e b Non importa davvero. Dopo aver lasciato solo uno spazio vuoto tra b e c Ho i seguenti risultati su Haswell:
k %
-----
1 48
2 48
3 48
4 48
5 46
6 53
7 59
8 67
9 73
10 81
11 85
12 87
13 87
...
0 86
Poiché Haswell è noto per essere esente da conflitti bancari, l'unica spiegazione rimasta è la falsa dipendenza tra gli indirizzi di memoria (e hai trovato il posto giusto nel manuale di microarchitettura di Agner Fog che spiega esattamente questo problema). La differenza tra il conflitto del banco e la falsa condivisione è che il conflitto del banco impedisce di accedere allo stesso banco due volte durante lo stesso ciclo di clock mentre la falsa condivisione impedisce la lettura da qualche offset in un pezzo di memoria 4K subito dopo aver scritto qualcosa con lo stesso offset (e non solo durante lo stesso ciclo di clock ma anche per più cicli di clock dopo la scrittura).
Dal momento che il tuo codice (per k=0 ) scrive su qualsiasi offset subito dopo facendo due letture dallo stesso offset e non leggevo da esso per molto tempo, questo caso dovrebbe essere considerato "migliore", quindi ho inserito k=0 a fine tavola. Per k=1 si legge sempre dall'offset che è stato sovrascritto di recente, il che significa falsa condivisione e quindi degrado delle prestazioni. Con k più grande il tempo tra la scrittura e la lettura aumenta e il core della CPU ha più possibilità di passare i dati scritti attraverso tutta la gerarchia della memoria (il che significa due traduzioni di indirizzi per la lettura e la scrittura, l'aggiornamento dei dati e dei tag della cache e il recupero dei dati dalla cache, la sincronizzazione dei dati tra i core e probabilmente molti più roba). k=12 o 24 clock (sulla mia CPU) sono sufficienti perché ogni dato scritto sia pronto per le successive operazioni di lettura, quindi a partire da questo valore le prestazioni tornano alla normalità. Non sembra molto diverso da 20+ clock su AMD (come detto da @Mysticial).
TL;DR :Per determinati valori di k , si verificano troppe condizioni di aliasing 4K, che è la causa principale del degrado della larghezza di banda. Nell'aliasing 4K, un carico viene bloccato inutilmente, aumentando così la latenza del carico effettiva e bloccando tutte le istruzioni dipendenti successive. Ciò a sua volta si traduce in un utilizzo ridotto della larghezza di banda L1. Per questi valori di k , la maggior parte delle condizioni di aliasing 4K può essere eliminata suddividendo il loop come segue:
for(int i=0; i<n/64; i++) {
_mm256_store_ps(z1+64*i+ 0,_mm256_add_ps(_mm256_load_ps(x1+64*i+ 0), _mm256_load_ps(y1+64*i+ 0)));
_mm256_store_ps(z1+64*i+ 8,_mm256_add_ps(_mm256_load_ps(x1+64*i+ 8), _mm256_load_ps(y1+64*i+ 8)));
}
for(int i=0; i<n/64; i++) {
_mm256_store_ps(z1+64*i+ 16,_mm256_add_ps(_mm256_load_ps(x1+64*i+16), _mm256_load_ps(y1+64*i+ 16)));
_mm256_store_ps(z1+64*i+ 24,_mm256_add_ps(_mm256_load_ps(x1+64*i+24), _mm256_load_ps(y1+64*i+ 24)));
}
for(int i=0; i<n/64; i++) {
_mm256_store_ps(z1+64*i+ 32,_mm256_add_ps(_mm256_load_ps(x1+64*i+32), _mm256_load_ps(y1+64*i+ 32)));
_mm256_store_ps(z1+64*i+ 40,_mm256_add_ps(_mm256_load_ps(x1+64*i+40), _mm256_load_ps(y1+64*i+ 40)));
}
for(int i=0; i<n/64; i++) {
_mm256_store_ps(z1+64*i+ 48,_mm256_add_ps(_mm256_load_ps(x1+64*i+48), _mm256_load_ps(y1+64*i+ 48)));
_mm256_store_ps(z1+64*i+ 56,_mm256_add_ps(_mm256_load_ps(x1+64*i+56), _mm256_load_ps(y1+64*i+ 56)));
}
Questa suddivisione elimina la maggior parte dell'aliasing 4K per i casi in cui k è un intero positivo dispari (come 1). La larghezza di banda L1 raggiunta è migliorata di circa il 50% su Haswell. C'è ancora spazio per miglioramenti, ad esempio, srotolando il ciclo e trovando un modo per non utilizzare la modalità di indirizzamento indicizzato per carichi e magazzini.
Tuttavia, questa suddivisione non elimina l'aliasing 4K per i valori pari di k . Quindi è necessario utilizzare una divisione diversa per valori pari di k . Tuttavia, quando k è 0, è possibile ottenere prestazioni ottimali senza dividere il ciclo. In questo caso, le prestazioni sono vincolate al back-end sulle porte 1, 2, 3, 4 e 7 contemporaneamente.
Potrebbe esserci una penalità di alcuni cicli in alcuni casi quando si esegue un caricamento e si memorizza contemporaneamente, ma in questo caso particolare questa penalità sostanzialmente non esiste perché sostanzialmente non esistono tali conflitti (ad esempio, gli indirizzi di carichi simultanei e i negozi sono sufficientemente distanti). Inoltre, la dimensione totale del working set rientra in L1, quindi non c'è traffico L1-L2 oltre la prima esecuzione del ciclo.
Il resto di questa risposta include una spiegazione dettagliata di questo riepilogo.
Innanzitutto, osserva che i tre array hanno una dimensione totale di 24 KB. Inoltre, poiché si stanno inizializzando gli array prima di eseguire il ciclo principale, la maggior parte degli accessi nel ciclo principale raggiungerà L1D, che ha una dimensione di 32 KB e un'associativa a 8 vie sui moderni processori Intel. Quindi non dobbiamo preoccuparci di errori o precaricamento dell'hardware. L'evento di performance più importante in questo caso è LD_BLOCKS_PARTIAL.ADDRESS_ALIAS , che si verifica quando un confronto di indirizzi parziale che coinvolge un caricamento successivo risulta in una corrispondenza con un negozio precedente e tutte le condizioni di inoltro del negozio sono soddisfatte, ma le posizioni di destinazione sono effettivamente diverse. Intel si riferisce a questa situazione come aliasing 4K o false store forwarding. La riduzione delle prestazioni osservabile dell'aliasing 4K dipende dal codice circostante.
Misurando cycles , LD_BLOCKS_PARTIAL.ADDRESS_ALIAS e MEM_UOPS_RETIRED.ALL_LOADS , possiamo vederlo per tutti i valori di k dove la larghezza di banda raggiunta è molto più piccola della larghezza di banda di picco, LD_BLOCKS_PARTIAL.ADDRESS_ALIAS e MEM_UOPS_RETIRED.ALL_LOADS sono quasi uguali. Anche per tutti i valori di k dove la larghezza di banda raggiunta è vicina alla larghezza di banda di picco, LD_BLOCKS_PARTIAL.ADDRESS_ALIAS è molto piccolo rispetto a MEM_UOPS_RETIRED.ALL_LOADS . Ciò conferma che si sta verificando un degrado della larghezza di banda a causa della maggior parte dei carichi che soffrono di aliasing 4K.
Il manuale di ottimizzazione Intel Sezione 12.8 dice quanto segue:
Cioè, ci sono due condizioni necessarie per un caricamento successivo per alias con un negozio precedente:
- I bit 5-11 dei due indirizzi lineari devono essere uguali.
- Le posizioni a cui si accede devono sovrapporsi (in modo che possano esserci dei dati da inoltrare).
Sui processori che supportano AVX-512, mi sembra che un singolo carico uop possa caricare fino a 64 byte. Quindi penso che l'intervallo per la prima condizione dovrebbe essere 6-11 anziché 5-11.
L'elenco seguente mostra la sequenza di accessi alla memoria basata su AVX (32 byte) e i 12 bit meno significativi dei relativi indirizzi per due diversi valori di k .
======
k=0
======
load x+(0*64+0)*4 = x+0 where x is 4k aligned 0000 000|0 0000
load y+(0*64+0)*4 = y+0 where y is 4k aligned 0000 000|0 0000
store z+(0*64+0)*4 = z+0 where z is 4k aligned 0000 000|0 0000
load x+(0*64+8)*4 = x+32 where x is 4k aligned 0000 001|0 0000
load y+(0*64+8)*4 = y+32 where y is 4k aligned 0000 001|0 0000
store z+(0*64+8)*4 = z+32 where z is 4k aligned 0000 001|0 0000
load x+(0*64+16)*4 = x+64 where x is 4k aligned 0000 010|0 0000
load y+(0*64+16)*4 = y+64 where y is 4k aligned 0000 010|0 0000
store z+(0*64+16)*4= z+64 where z is 4k aligned 0000 010|0 0000
load x+(0*64+24)*4 = x+96 where x is 4k aligned 0000 011|0 0000
load y+(0*64+24)*4 = y+96 where y is 4k aligned 0000 011|0 0000
store z+(0*64+24)*4 = z+96 where z is 4k aligned 0000 011|0 0000
load x+(0*64+32)*4 = x+128 where x is 4k aligned 0000 100|0 0000
load y+(0*64+32)*4 = y+128 where y is 4k aligned 0000 100|0 0000
store z+(0*64+32)*4= z+128 where z is 4k aligned 0000 100|0 0000
.
.
.
======
k=1
======
load x+(0*64+0)*4 = x+0 where x is 4k aligned 0000 000|0 0000
load y+(0*64+0)*4 = y+0 where y is 4k+64 aligned 0000 010|0 0000
store z+(0*64+0)*4 = z+0 where z is 4k+128 aligned 0000 100|0 0000
load x+(0*64+8)*4 = x+32 where x is 4k aligned 0000 001|0 0000
load y+(0*64+8)*4 = y+32 where y is 4k+64 aligned 0000 011|0 0000
store z+(0*64+8)*4 = z+32 where z is 4k+128 aligned 0000 101|0 0000
load x+(0*64+16)*4 = x+64 where x is 4k aligned 0000 010|0 0000
load y+(0*64+16)*4 = y+64 where y is 4k+64 aligned 0000 100|0 0000
store z+(0*64+16)*4= z+64 where z is 4k+128 aligned 0000 110|0 0000
load x+(0*64+24)*4 = x+96 where x is 4k aligned 0000 011|0 0000
load y+(0*64+24)*4 = y+96 where y is 4k+64 aligned 0000 101|0 0000
store z+(0*64+24)*4 = z+96 where z is 4k+128 aligned 0000 111|0 0000
load x+(0*64+32)*4 = x+128 where x is 4k aligned 0000 100|0 0000
load y+(0*64+32)*4 = y+128 where y is 4k+64 aligned 0000 110|0 0000
store z+(0*64+32)*4= z+128 where z is 4k+128 aligned 0001 000|0 0000
.
.
.
Si noti che quando k=0, nessun carico sembra soddisfare le due condizioni dell'aliasing 4K. D'altra parte, quando k=1, tutti i carichi sembrano soddisfare le condizioni. Tuttavia, è noioso farlo manualmente per tutte le iterazioni e tutti i valori di k . Così ho scritto un programma che fondamentalmente genera gli indirizzi degli accessi alla memoria e calcola il numero totale di carichi che hanno subito l'aliasing 4K per diversi valori di k . Un problema che ho riscontrato è che non conosciamo, per un dato carico, il numero di negozi che sono ancora nel buffer del negozio (non sono stati ancora impegnati). Pertanto, ho progettato il simulatore in modo che possa utilizzare throughput del negozio diversi per diversi valori di k , che sembra riflettere meglio ciò che sta effettivamente accadendo su un processore reale. Il codice può essere trovato qui.
La figura seguente mostra il numero di casi di aliasing 4K prodotti dal simulatore rispetto al numero misurato utilizzando LD_BLOCKS_PARTIAL.ADDRESS_ALIAS su Haswell. Ho ottimizzato il throughput del negozio utilizzato nel simulatore per ogni valore di k per rendere le due curve il più simili possibile. La seconda figura mostra il throughput del negozio inverso (cicli totali diviso per il numero totale di negozi) utilizzato nel simulatore e misurato su Haswell. Si noti che il throughput del negozio quando k=0 non ha importanza perché non esiste comunque alcun aliasing 4K. Poiché ci sono due carichi per ogni negozio, il throughput del carico inverso è la metà del throughput del negozio inverso.
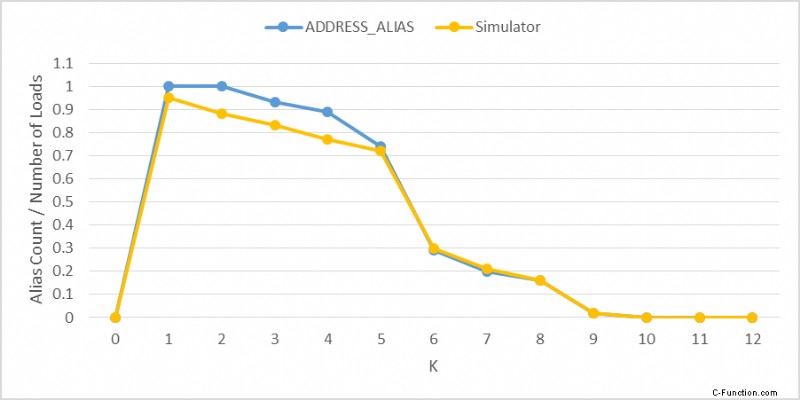
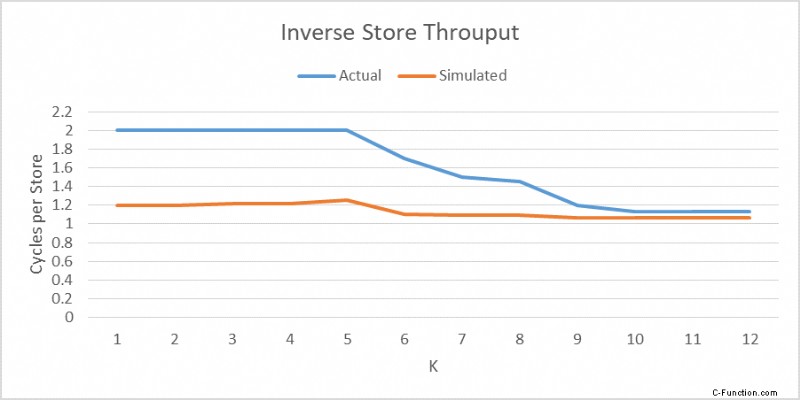
Ovviamente la quantità di tempo che ogni negozio rimane nel buffer del negozio è diversa su Haswell e sul simulatore, quindi avevo bisogno di utilizzare throughput diversi per rendere simili le due curve. Il simulatore può essere utilizzato per mostrare in che modo il throughput del negozio può influire sul numero di alias 4K. Se il throughput del negozio è molto vicino a 1c/store, il numero di casi di aliasing 4K sarebbe stato molto inferiore. Le condizioni di aliasing 4K non comportano svuotamenti della pipeline, ma possono comportare replay uop dalla RS. In questo caso particolare, però, non ho osservato alcun replay.
In realtà c'è una penalità di alcuni cicli quando si esegue un caricamento e un'archiviazione contemporaneamente, ma possono verificarsi solo quando gli indirizzi del carico e dell'archivio sono entro 64 byte (ma non uguali) su Haswell o 32 byte su Ivy Bridge e Ponte Sabbioso. Strani effetti sulle prestazioni dei negozi dipendenti vicini in un ciclo di ricerca di puntatori su IvyBridge. L'aggiunta di un carico extra lo accelera? In questo caso, gli indirizzi di tutti gli accessi sono allineati a 32 byte, ma, su IvB, le porte L1 hanno tutte una dimensione di 16 byte, quindi la penalità può essere incorsa su Haswell e IvB. In effetti, poiché i carichi e gli archivi possono richiedere più tempo per ritirarsi e poiché sono presenti più buffer di caricamento rispetto ai buffer di archivio, è più probabile che un caricamento successivo assuma un falso alias di un archivio precedente. Ciò solleva la questione, tuttavia, di come la penalità alias 4K e la penalità di accesso L1 interagiscono tra loro e contribuiscono alla prestazione complessiva. Usando il CYCLE_ACTIVITY.STALLS_LDM_PENDING evento e la funzione di monitoraggio delle prestazioni della latenza del carico MEM_TRANS_RETIRED.LOAD_LATENCY_GT_* , mi sembra che non ci sia una penale di accesso L1 osservabile. Ciò implica che il più delle volte gli indirizzi di carichi e magazzini contemporanei non inducono la penalità. Pertanto, la penalità per l'aliasing 4K è la causa principale del degrado della larghezza di banda.
Ho usato il seguente codice per effettuare misurazioni su Haswell. Questo è essenzialmente lo stesso codice emesso da g++ -O3 -mavx .
%define SIZE 64*64*2
%define K_ 10
BITS 64
DEFAULT REL
GLOBAL main
EXTERN printf
EXTERN exit
section .data
align 4096
bufsrc1: times (SIZE+(64*K_)) db 1
bufsrc2: times (SIZE+(64*K_)) db 1
bufdest: times SIZE db 1
section .text
global _start
_start:
mov rax, 1000000
.outer:
mov rbp, SIZE/256
lea rsi, [bufsrc1]
lea rdi, [bufsrc2]
lea r13, [bufdest]
.loop:
vmovaps ymm1, [rsi]
vaddps ymm0, ymm1, [rdi]
add rsi, 256
add rdi, 256
add r13, 256
vmovaps[r13-256], ymm0
vmovaps ymm2, [rsi-224]
vaddps ymm0, ymm2, [rdi-224]
vmovaps [r13-224], ymm0
vmovaps ymm3, [rsi-192]
vaddps ymm0, ymm3, [rdi-192]
vmovaps [r13-192], ymm0
vmovaps ymm4, [rsi-160]
vaddps ymm0, ymm4, [rdi-160]
vmovaps [r13-160], ymm0
vmovaps ymm5, [rsi-128]
vaddps ymm0, ymm5, [rdi-128]
vmovaps [r13-128], ymm0
vmovaps ymm6, [rsi-96]
vaddps ymm0, ymm6, [rdi-96]
vmovaps [r13-96], ymm0
vmovaps ymm7, [rsi-64]
vaddps ymm0, ymm7, [rdi-64]
vmovaps [r13-64], ymm0
vmovaps ymm1, [rsi-32]
vaddps ymm0, ymm1, [rdi-32]
vmovaps [r13-32], ymm0
dec rbp
jg .loop
dec rax
jg .outer
xor edi,edi
mov eax,231
syscall