El algoritmo de clasificación de esta pregunta se vuelve dos veces más rápido (!) si -fprofile-arcs está habilitado en gcc (4.7.2). El código C muy simplificado de esa pregunta (resultó que puedo inicializar la matriz con todos ceros, el comportamiento de rendimiento extraño permanece pero hace que el razonamiento sea mucho más simple):
#include <time.h>
#include <stdio.h>
#define ELEMENTS 100000
int main() {
int a[ELEMENTS] = { 0 };
clock_t start = clock();
for (int i = 0; i < ELEMENTS; ++i) {
int lowerElementIndex = i;
for (int j = i+1; j < ELEMENTS; ++j) {
if (a[j] < a[lowerElementIndex]) {
lowerElementIndex = j;
}
}
int tmp = a[i];
a[i] = a[lowerElementIndex];
a[lowerElementIndex] = tmp;
}
clock_t end = clock();
float timeExec = (float)(end - start) / CLOCKS_PER_SEC;
printf("Time: %2.3f\n", timeExec);
printf("ignore this line %d\n", a[ELEMENTS-1]);
}
Después de jugar con las banderas de optimización durante mucho tiempo, resultó que -ftree-vectorize también produce este comportamiento extraño, por lo que podemos tomar -fprofile-arcs fuera de la cuestión. Después de perfilar con perf Descubrí que la única diferencia relevante es:
Caso rápido gcc -std=c99 -O2 simp.c (se ejecuta en 3,1 s)
cmpl %esi, %ecx
jge .L3
movl %ecx, %esi
movslq %edx, %rdi
.L3:
Caso lento gcc -std=c99 -O2 -ftree-vectorize simp.c (se ejecuta en 6,1 s)
cmpl %ecx, %esi
cmovl %edx, %edi
cmovl %esi, %ecx
En cuanto al primer fragmento:dado que la matriz solo contiene ceros, siempre saltamos a .L3 . Puede beneficiarse enormemente de la predicción de ramas.
Supongo que el cmovl las instrucciones no pueden beneficiarse de la predicción de bifurcaciones.
Preguntas:
-
¿Son correctas todas mis conjeturas anteriores? ¿Esto hace que el algoritmo sea lento?
-
En caso afirmativo, ¿cómo puedo evitar que gcc emita esta instrucción (aparte del trivial
-fno-tree-vectorization) solución, por supuesto) pero aún haciendo tantas optimizaciones como sea posible? -
¿Qué es esto
-ftree-vectorization? La documentación es bastante
vaga, necesitaría un poco más de explicación para entender lo que está pasando.
Actualización: Desde que surgió en los comentarios:el extraño comportamiento de rendimiento w.r.t. el -ftree-vectorize la bandera permanece con datos aleatorios. Como señala Yakk, para la ordenación por selección, en realidad es difícil crear un conjunto de datos que daría lugar a muchas predicciones erróneas de rama.
Ya que también surgió:tengo una CPU Core i5.
Basado en el comentario de Yakk, creé una prueba. El código a continuación (en línea sin impulso) por supuesto ya no es un algoritmo de clasificación; Solo saqué el lazo interior. Su único objetivo es examinar el efecto de la predicción de ramas:Omitimos el if rama en el for bucle con probabilidad p .
#include <algorithm>
#include <cstdio>
#include <random>
#include <boost/chrono.hpp>
using namespace std;
using namespace boost::chrono;
constexpr int ELEMENTS=1e+8;
constexpr double p = 0.50;
int main() {
printf("p = %.2f\n", p);
int* a = new int[ELEMENTS];
mt19937 mt(1759);
bernoulli_distribution rnd(p);
for (int i = 0 ; i < ELEMENTS; ++i){
a[i] = rnd(mt)? i : -i;
}
auto start = high_resolution_clock::now();
int lowerElementIndex = 0;
for (int i=0; i<ELEMENTS; ++i) {
if (a[i] < a[lowerElementIndex]) {
lowerElementIndex = i;
}
}
auto finish = high_resolution_clock::now();
printf("%ld ms\n", duration_cast<milliseconds>(finish-start).count());
printf("Ignore this line %d\n", a[lowerElementIndex]);
delete[] a;
}
Los bucles de interés:
Esto se denominará cmov
g++ -std=c++11 -O2 -lboost_chrono -lboost_system -lrt branch3.cpp
xorl %eax, %eax
.L30:
movl (%rbx,%rbp,4), %edx
cmpl %edx, (%rbx,%rax,4)
movslq %eax, %rdx
cmovl %rdx, %rbp
addq $1, %rax
cmpq $100000000, %rax
jne .L30
Esto se denominará sin cmov , el -fno-if-conversion Turix señaló la bandera en su respuesta.
g++ -std=c++11 -O2 -fno-if-conversion -lboost_chrono -lboost_system -lrt branch3.cpp
xorl %eax, %eax
.L29:
movl (%rbx,%rbp,4), %edx
cmpl %edx, (%rbx,%rax,4)
jge .L28
movslq %eax, %rbp
.L28:
addq $1, %rax
cmpq $100000000, %rax
jne .L29
La diferencia lado a lado
cmpl %edx, (%rbx,%rax,4) | cmpl %edx, (%rbx,%rax,4)
movslq %eax, %rdx | jge .L28
cmovl %rdx, %rbp | movslq %eax, %rbp
| .L28:
El tiempo de ejecución en función del parámetro de Bernoulli p
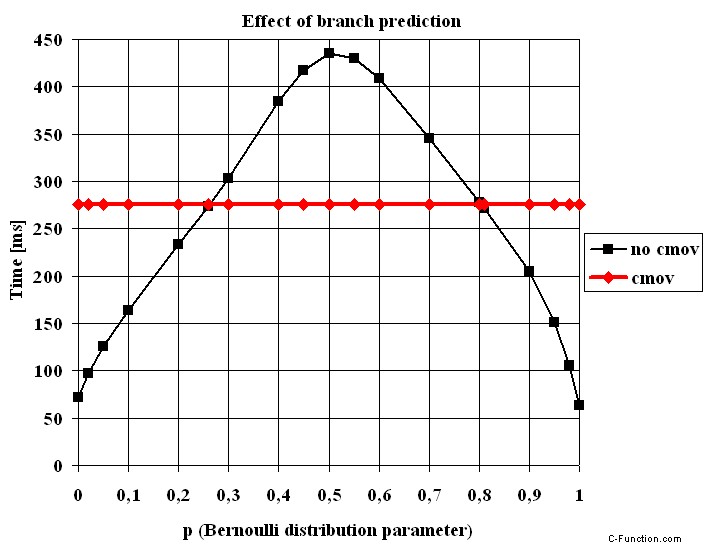
El código con el cmov la instrucción es absolutamente insensible a p . El código sin el cmov instrucción es el ganador si p<0.26 o 0.81<p y es como máximo 4,38 veces más rápido (p=1 ). Por supuesto, la peor situación para el predictor de bifurcación es alrededor de p=0.5 donde el código es 1,58 veces más lento que el código con cmov instrucción.
Respuestas:
Nota:Respondido antes de que se agregara la actualización del gráfico a la pregunta; algunas referencias de código ensamblador aquí pueden estar obsoletas.
(Adaptado y ampliado de nuestro chat anterior, que fue lo suficientemente estimulante como para hacerme investigar un poco más).
Primero (según nuestro chat anterior), parece que la respuesta a su primera pregunta es "sí". En el código vectorial "optimizado", la optimización que afecta (negativamente) al rendimiento es branch predica ción , mientras que en el código original el rendimiento se ve afectado (positivamente) por la predicción de la rama . (Tenga en cuenta la 'a adicional ' en el primero.)
Con respecto a su tercera pregunta:aunque en su caso, en realidad no se está realizando ninguna vectorización, desde el paso 11 ("Ejecución condicional") aquí parece que uno de los pasos asociados con las optimizaciones de vectorización es "aplanar" condicionales dentro de bucles específicos, como este bit en tu ciclo:
if (a[j] < a[lowerElementIndex]
lowerElementIndex = j;
Aparentemente, esto sucede incluso si no hay vectorización.
Esto explica por qué el compilador usa las instrucciones de movimiento condicional (cmovl ). El objetivo allí es evitar una rama por completo (en lugar de tratar de predecir correctamente). En cambio, los dos cmovl las instrucciones se enviarán por la canalización antes del resultado del cmpl anterior se conoce y el resultado de la comparación se "reenviará" para habilitar/evitar los movimientos antes de su reescritura (es decir, antes de que surtan efecto).
Tenga en cuenta que si el ciclo se hubiera vectorizado, podría haber valido la pena para llegar al punto en el que se pudieran realizar múltiples iteraciones a través del ciclo en paralelo.
Sin embargo, en su caso, el intento de optimización en realidad resulta contraproducente porque en el ciclo aplanado, los dos movimientos condicionales se envían a través de la canalización cada vez que se realiza el ciclo. Esto en sí mismo podría no ser tan malo, excepto que existe un riesgo de datos RAW que provoca el segundo movimiento (cmovl %esi, %ecx ) para tener que esperar hasta el acceso a la matriz/memoria (movl (%rsp,%rsi,4), %esi ) se completa, incluso si el resultado finalmente se ignorará. De ahí la enorme cantidad de tiempo dedicado a ese cmovl en particular. . (Supongo que esto es un problema con su procesador que no tiene una lógica lo suficientemente compleja integrada en su implementación de predicación/reenvío para lidiar con el peligro).
Por otro lado, en el caso no optimizado, como averiguaste correctamente, branch prediction puede ayudar a evitar tener que esperar el resultado del acceso a la matriz/memoria correspondiente allí (el movl (%rsp,%rcx,4), %ecx instrucción). En ese caso, cuando el procesador predice correctamente una rama tomada (que para una matriz de todos 0 será cada vez, pero [incluso] en una matriz aleatoria debería [todavía] ser aproximadamente más que [editado por el comentario de @Yakk] la mitad del tiempo), no tiene que esperar a que finalice el acceso a la memoria para continuar y poner en cola las siguientes instrucciones en el bucle. Entonces, en las predicciones correctas, obtiene un impulso, mientras que en las predicciones incorrectas, el resultado no es peor que en el caso "optimizado" y, además, es mejor debido a la capacidad de evitar a veces tener los 2 "desperdiciados" cmovl instrucciones en proceso.
[Se eliminó lo siguiente debido a mi suposición errónea sobre su procesador según su comentario.]
Volviendo a sus preguntas, sugeriría mirar el enlace anterior para obtener más información sobre las banderas relevantes para la vectorización, pero al final, estoy bastante seguro de que está bien ignorar esa optimización. dado que su Celeron no es capaz de usarlo (en este contexto) de todos modos.
[Agregado después de que se eliminó lo anterior]
Referente a su segunda pregunta ("...cómo puedo evitar que gcc emita esta instrucción... "), podría probar el -fno-if-conversion y -fno-if-conversion2 banderas (no estoy seguro si siempre funcionan, ya no funcionan en mi mac), aunque no creo que su problema sea con el cmovl instrucción en general (es decir, no siempre use esos indicadores), solo con su uso en este contexto particular (donde la predicción de ramas será muy útil dado el punto de @Yakk sobre su algoritmo de ordenación).
Algunas respuestas de código
#include <time.h>
#include <stdio.h>
#define ELEMENTS 100000 int main() { int a[ELEMENTS] = { 0 };
clock_t start = clock();
for (int i = 0;
i <
ELEMENTS;
++i) {
int lowerElementIndex = i;
for (int j = i+1;
j <
ELEMENTS;
++j) {
if (a[j] <
a[lowerElementIndex]) {
lowerElementIndex = j;
}
}
int tmp = a[i];
a[i] = a[lowerElementIndex];
a[lowerElementIndex] = tmp;
} clock_t end = clock();
float timeExec = (float)(end - start) / CLOCKS_PER_SEC;
printf("Time: %2.3f\n", timeExec);
printf("ignore this line %d\n", a[ELEMENTS-1]);
} cmpl %esi, %ecx
jge .L3
movl %ecx, %esi
movslq %edx, %rdi .L3: cmpl %ecx, %esi
cmovl %edx, %edi
cmovl %esi, %ecx #include <algorithm>
#include <cstdio>
#include <random>
#include <boost/chrono.hpp>
using namespace std;
using namespace boost::chrono;
constexpr int ELEMENTS=1e+8;
constexpr double p = 0.50;
int main() { printf("p = %.2f\n", p);
int* a = new int[ELEMENTS];
mt19937 mt(1759);
bernoulli_distribution rnd(p);
for (int i = 0 ;
i <
ELEMENTS;
++i){
a[i] = rnd(mt)? i : -i;
} auto start = high_resolution_clock::now();
int lowerElementIndex = 0;
for (int i=0;
i<ELEMENTS;
++i) {
if (a[i] <
a[lowerElementIndex]) {
lowerElementIndex = i;
} } auto finish = high_resolution_clock::now();
printf("%ld ms\n", duration_cast<milliseconds>(finish-start).count());
printf("Ignore this line %d\n", a[lowerElementIndex]);
delete[] a;
} xorl %eax, %eax .L30:
movl (%rbx,%rbp,4), %edx
cmpl %edx, (%rbx,%rax,4)
movslq %eax, %rdx
cmovl %rdx, %rbp
addq $1, %rax
cmpq $100000000, %rax
jne .L30 xorl %eax, %eax .L29:
movl (%rbx,%rbp,4), %edx
cmpl %edx, (%rbx,%rax,4)
jge .L28
movslq %eax, %rbp .L28:
addq $1, %rax
cmpq $100000000, %rax
jne .L29 cmpl %edx, (%rbx,%rax,4) |
cmpl %edx, (%rbx,%rax,4) movslq %eax, %rdx
|
jge .L28 cmovl %rdx, %rbp
|
movslq %eax, %rbp
| .L28: if (a[j] <
a[lowerElementIndex]
lowerElementIndex = j;