Antes de empezar
Esta publicación de blog presenta iframes, archivos SVG interactivos y gráficos que pueden no mostrarse correctamente en dispositivos portátiles. Lo sentimos. Sin embargo, los gráficos son interactivos, por lo que puede ampliar y ver los valores exactos.
Si yo fuera un compilador, simplemente pondría todos tus bytes en tu binario
Ha habido algunos debates interesantes y apasionados sobre std::embed últimamente.
std::embed Seguramente sería una gran herramienta para tener en la caja de herramientas de uno, y estoy seguro de que se adoptará alguna versión con el tiempo, una vez que se alcance un consenso (todavía tengo que encontrar a alguien que no esté convencido de la utilidad de esa propuesta).
Pero la estandarización (de cualquier cosa) es un desafío, así que mientras tanto, quiero explorar una de las motivaciones para std::embed :
La compilación de arreglos grandes requiere mucho tiempo y recursos. Para cualquier compilador.
¿Cómo es eso? Bueno...
Por supuesto, como insinuó ThePhd, si este ejercicio es agotador para su CPU, no es nada comparado con lo que le hace a su RAM:
50000000 ints, eso es alrededor de 200 MB y tal vez eso sea un poco ridículo. Hay casos de uso válidos para arreglos grandes.
Por ejemplo, el sistema de recursos de Qt crea un sistema de archivos para recursos incrustados.<charconv> , funciones criptográficas y otras se basan en tablas de búsqueda. Si desea que estas características sean constexpr , no puedes usar trucos de enlazador (además de ¿quién quiere usar trucos de enlazador?)
Es posible que haya notado que estoy trabajando en las propiedades de Unicode, e incluso con un empaquetado de bits cuidadoso, estas tablas tienen miles de elementos.
Twitter tuvo muchos otros casos de uso interesantes, para compartir, por ejemplo, ¡las personas incrustan pesos de redes neuronales en binarios dirigidos a plataformas integradas!
Hola #cplusplus twitter, ¿cuáles son sus casos de uso para datos binarios incrustados muy grandes/matrices const int en C++?
– Corentin (@Cor3ntin) 21 de diciembre de 2019Hay un truco bien conocido para hacer que sus programas sean significativamente más rápidos:¡Use literales de cadena!
int array[] = {1, 1, /*, ..., */ 1, 1}; //slow
const char* literal = // Fast
"\x00\x00\x00\x01\x00\x00\x00\x01"
/*....*/
"\x00\x00\x00\x01\x00\x00\x00\x01";
Desafortunadamente, hay una trampa:MSVC no puede tener literales de cadena mayores de 65535 bytes.
Creo que eliminar esta limitación sería romper el ABI y, por lo tanto, es poco probable que suceda. Odio la estabilidad ABI.
De todos modos, surge la pregunta:¿Por qué las cadenas literales son mucho más rápidas que las matrices? Hay algunas herramientas que nos ayudan a echar un vistazo bajo el capó del compilador. Una de esas herramientas es el -ast-dump opción de clang que... bien descarga su representación interna. Esa herramienta está convenientemente disponible en Compiler Explorer:
Y ese es nuestro culpable:Clang representa cada número como su propio NODO AST, mientras que un literal de cadena siempre es un nodo y cada byte está representado por un byte.
IntegerLiteral tiene que hacer un seguimiento de:
- El valor
- Información de tipo para ese valor (incluyendo constancia, firma, tipo exacto (
int,long, etc.) - La ubicación de origen de ese valor.
- Y algunas cosas más.
Al final, cada nodo podría almacenar bien alrededor de 100 bytes por un valor de 4 bytes.
Más críticamente, cada subexpresión de InitListExpr pueden tener un tipo completamente diferente y pueden ser expresiones completas, llamadas a funciones, lambdas y creación de instancias de plantillas de eventos.
struct a {
operator int() const;
};
template <typename T>
struct V {
static constexpr int v = 42;
};
int array[] = {a(), V<int>::v, []<typename T>(T i) {return T(); }(0)};
Y al mismo tiempo, las listas de inicializadores se pueden usar para inicializar cualquier cosa:instancias de clase, matrices, agregados, std::initializer_list y versión de plantilla de todo lo anterior.
La inicialización en C++ es cualquier cosa menos trivial. En sonido metálico, las diez mil líneas de SemaInit.cpp hará la mayor parte de ese trabajo, y lo hará, para cada elemento de lo que ingenuamente esperábamos que fuera una simple matriz de números enteros, comprobará que es realmente convertible al tipo de esa matriz.
Esto es mucho trabajo para nuestro pobre compilador.
Mejorando el rendimiento para matrices enteras
Dado que las matrices de enteros o bytes son algo comunes, ¿podemos mejorar el rendimiento de ese caso de uso? ¡Es hora de clonar llvm!
Clang es una base de código masiva. Ya jugué un poco con él, pero no hice nada particularmente impresionante con él. Aparte del tamaño y la complejidad, Clang sigue siendo un compilador. Hay algunos bits:
- A lexer, preprocesamiento y tokenización
- Un analizador
- Análisis semántico
- Generación de infrarrojos LLVM
- Magia que transforma IR en código objeto
¿Por dónde empezamos? Mi primera idea fue introducir un atributo para que el desarrollador pudiera decirle al compilador que analizara las matrices de una manera específica:
[[clang::literal_array]]
int array[] = {1, 2, 3, 4};
Pero rápidamente se me ocurrió que tener que decirle manualmente al compilador que sea eficiente sería una molestia y tendría beneficios limitados.
Nuevo plan:detecte y optimice el patrón automáticamente. Hay muchas maneras de orientarse en una gran base de código:perfiladores, depuradores, lectura de código. Mucha lectura.
Muy pronto, encontré lo que estaba buscando:
/// ParseBraceInitializer - Called when parsing an initializer that has a
/// leading open brace.
///
/// initializer: [C99 6.7.8]
/// '{' initializer-list '}'
/// '{' initializer-list ',' '}'
/// [GNU] '{' '}'
///
/// initializer-list:
/// designation[opt] initializer ...[opt]
/// initializer-list ',' designation[opt] initializer ...[opt]
///
ExprResult Parser::ParseBraceInitializer();
¡Incluso fui bendecido con algunos comentarios útiles! Esa función devuelve un InitListExpr que tiene una subexpresión para cada elemento de la lista. Sabemos que es un problema, ¡así que hagamos otra cosa!
Vamos a Lex la lista completa (hasta la llave de cierre), y si todos los tokens son constantes numéricas, devolveremos un nuevo tipo de expresión:
// Try to parse the initializer as a list of numeral literal
// To improve compile time of large arrays
if(NextToken().is(tok::numeric_constant)) {
ExprResult E = ParseListOfLiteralsInitializer();
if(!E.isInvalid()) {
return E;
}
//otherwise carry on
}
Implementando ParseListOfLiteralsInitializer no fue difícil. Clang tiene instalaciones para realizar un análisis tentativo y revertir el estado del lexer cuando las suposiciones no funcionan.
Pero ahora necesitaba un nuevo Expr escriba para volver. Un poco más de trabajo, Expr los tipos deben manejarse por todas partes, cientos de lugares para cambiar. Al momento de escribir esto, apenas hice el 10 por ciento de ese trabajo.
Le di un mal nombre
class ListOfLiteralExpr : public Expr {
public:
ListOfLiteralExpr(ASTContext &Context,
SourceLocation LBraceLoc,
ArrayRef<llvm::APInt> Values,
QualType Ty,
SourceLocation RBraceLoc);
};
Primer borrador:la ubicación de cada llave con fines de diagnóstico, una lista de valores, el tipo de cada elemento (int, largo, versión sin firmar, etc.). Y eso es todo. Tenga en cuenta que llvm::APInt ya es más grande y más complejo de lo que necesitamos. Más sobre eso más adelante. La optimización principal es asumir que cada elemento tiene el mismo tipo:si encontramos, por ejemplo, {1, 1L}; , tendríamos que rescatar y tomar el InitListExpr camino.
Mi enfoque no es específicamente eficiente. Probablemente sea mejor analizar una lista pequeña como InitListExpr En cualquier caso, nunca analizo listas de menos de 2 elementos como ListOfLiteralExpr por una razón que será obvia en un minuto.
Hasta ahora he tenido éxito en la creación de un tipo de expresión mucho más rápido de analizar que InitListExpr . Todavía no tan rápido como StringLiteral aunque:una cadena es 1 token, mientras que tengo un par de tokens para analizar por entero. Pero el Lexer es bastante rápido, dejémoslo así porque tengo problemas mayores.
No se dio cuenta cuando comencé por ese camino, pero pronto me enfrentaría a una realidad espantosa:introduje una expresión que es una versión optimizada de InitListExpr . Por lo tanto, tendré que lidiar con la abrumadora complejidad de SemaInit.cpp Un archivo que requiere un gran conocimiento tanto de la inicialización en C++ como de Clang.
Yo tampoco sabía.
De acuerdo, eso no es del todo cierto:
También debe comprender C, OpenCL y los detalles de las extensiones GCC y MSVC. ¡Estaba condenado al fracaso!
El problema principal es que Clang opera en expression.My ListOfLiteralExpr type es una expresión pero sus elementos no lo son!
Sin embargo, hice algunos progresos al crear una nueva clase
class AbstractInitListExpr : public Expr {};
class ListOfLiteralExpr : public AbstractInitListExpr {};
class InitListExpr : public AbstractInitListExpr {};
Lo que me permite compartir automáticamente algún código entre mi ListOfLiteralExpr y el InitListExpr existente , en lugares donde ambas clases tenían la información necesaria como el número de elementos o el tipo de un elemento (pero no el elemento) en sí mismo.
Comprender algo sobre SemaInit tomó un tiempo. Por lo que pude deducir, clang opera múltiples pases en la lista de inicialización y construye una secuencia de operaciones para realizar antes de finalmente la inicialización. Tanto C++ como C pueden ser un poco locos:
struct A {
int a;
struct {
int b;
int c;
};
int d;
int e;
} a = {1, 2, 3, .e = 4};
int x [10] = { [1] = 10};
Hay que resolver conversiones, sobrecargas, etc. y seamos sinceros, no tengo ni idea de lo que estoy haciendo.
Pero hackeé algo
void InitializationSequence::InitializeFrom(
Sema &S,
const InitializedEntity &Entity,
const InitializationKind &Kind,
MultiExprArg Args,
bool TopLevelOfInitList,
bool TreatUnavailableAsInvalid);
Encontrar dónde colocar las cosas es la mitad del trabajo:compuse ese código:es desagradable y está plagado de errores:no se quejará de conversiones largas a cortas, por ejemplo, y convertir ListOfLiteralExpr a InitListExpr no es eficiente. Estoy penalizando el caso general por el bien de las matrices grandes.
if(auto* ListExpr = dyn_cast_or_null<ListOfLiteralExpr>(Initializer)) {
// TODO CORENTIN: HANDLE MORE CASES
if (const ArrayType *DestAT = Context.getAsArrayType(DestType)) {
//Nasty
if(DestAT->getElementType()->isIntegerType()) {
TryListOfLiteralInitialization(S, Entity, Kind, ListExpr, *this,
TreatUnavailableAsInvalid);
return;
}
}
else {
//Convert back ListOfLiteralExpr to InitListExpr
}
}
Pero funciona en la mayoría de los casos, pero no para las plantillas, no lo he manejado en absoluto, así que std::array a{1, 2, 3}; no compila.
TryListOfLiteralInitialization es muy simple, en virtud de la omisión de detalles críticos:solo verifico que el tipo que estoy inicializando sea una matriz del tamaño correcto (o tamaño incompleto, ¡eso también funciona!).
En última instancia, alrededor de 12000 líneas en SemaDecl.cpp , llegamos a una conclusión exitosa, aunque anticlimática, de todo ese asunto:
VDecl->setInit(Init);
Hemos terminado con el análisis sintáctico y el análisis semántico (realmente es solo un gran paso, el análisis c++ depende en gran medida del contexto; espero que eso no lo mantenga despierto por la noche).
Lo único que queda por hacer es generar algo de código. Entiendo esa parte menos, pero tejiendo AbstractInitListExpr en la parte del código que maneja Code Generation (IR):GGExprAgg (Emisor de expresión agregada), resultó bastante fácil:
Podría diferir a otra parte del código:Evaluación de Expresión Constante, donde ocurre toda la bondad de constexpr y el plegamiento constante:
Agregar un visitante en ArrayExprEvaluator fue fácil:
bool ArrayExprEvaluator::VisitListOfLiteralExpr(const ListOfLiteralExpr *E) {
const ConstantArrayType *CAT = Info.Ctx.getAsConstantArrayType(E->getType());
assert(CAT && "ListOfLiteralExpr isn't an array ?!");
QualType EType = CAT->getElementType();
assert(EType->isIntegerType() && "unexpected literal type");
unsigned Elts = CAT->getSize().getZExtValue();
Result = APValue(APValue::UninitArray(),
std::min(E->getNumInits(), Elts), Elts);
for(unsigned I = 0; I < E->getNumInits(); I++ )
Result.getArrayInitializedElt(I) = APSInt(E->getInit(I));
return true;
}
Lo optimicé más tarde. Pero ahora tenemos suficiente para hacer algunos puntos de referencia, cortesía de algunos scripts de Python defectuosos
f.write("int a [] = {")
f.write(",".join(["1"] * elems))
f.write("}; int main (int argc, char**) { return a[argc]; }")
Hicimos el tiempo de compilación 3 veces mejor. ¡No está mal! Lleva menos de 10 segundos generar un archivo con 200 MB de datos.
Usando -ftime-trace , tenemos una mejor idea de las ganancias:puede leer más sobre -ftime-trace :aquí.¡Herramienta muy útil, especialmente para medir y optimizar los tiempos de compilación de su propio código!
Resulta que Chrome incluso admite la comparación de múltiples framgraph pirateando el archivo renderizado. No pude encontrar ningún visualizador además de chrome://tracing , por lo que un png tendrá que hacer:
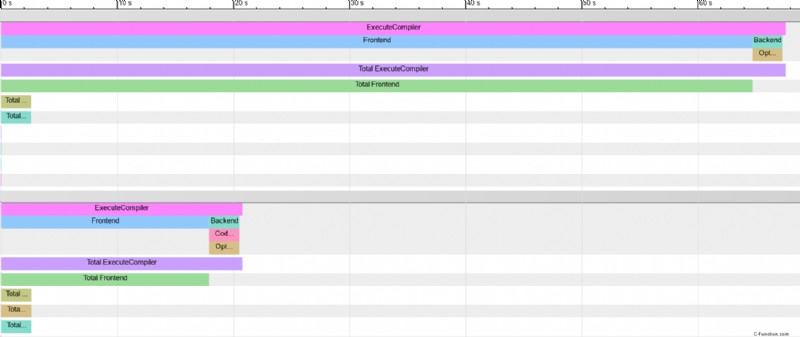
Curiosamente, el uso de la memoria no parece haber mejorado mucho.
Los tiempos de compilación de los arreglos pequeños se pierden en el ruido. Entonces, en el gráfico a continuación, mido el tiempo de compilación de 1000 arreglos del tamaño dado, el resultado luego se divide por 1000 para darnos un tiempo promedio por arreglo.
Parecería que la mejora es visible para los arreglos pequeños. Tómelo con una pizca de sal:las modificaciones probablemente pesimizan los casos que no son arreglos. .(Para valores pequeños, el archivo fuente comparado contiene 1000 arreglos del tamaño dado)
AstSmtWriter y módulos
Los encabezados precompilados, las unidades de encabezados de módulos y las interfaces de módulos comparten parte del mismo formato binario.AstSmtWriter y AstSmtReader son responsables de la serialización binaria de Sentencias (y Expresiones, Expresiones son Sentencias en sonido metálico - Tiene sentido).
Como quería ver cómo los módulos ayudan con grandes arreglos, implementé la serialización para mi ListOfLiteralExpr recién acuñado .
Al mismo tiempo, decidí hacer mi implementación un poco más limpia. Hasta ahora, almacené mis valores en un llvm::SmallVector<Values> .Pero, clang tiene su propio asignador y la expresión que necesita algo de espacio adicional puede pedir a los asignadores que coloquen los datos adicionales después del objeto.
class ListOfLiteralExpr final: public AbstractInitListExpr,
private llvm::TrailingObjects<ListOfLiteralExpr, unsigned, char>
{
unsigned numTrailingObjects(OverloadToken<unsigned>) const {
return 1;
}
unsigned numTrailingObjects(OverloadToken<char>) const {
return *getTrailingObjects<unsigned>();
}
ListOfLiteralExpr*
ListOfLiteralExpr::Create(ASTContext &Context,
SourceLocation LBraceLoc,
ArrayRef<uint64_t> Values,
QualType Ty,
SourceLocation RBraceLoc) {
void *Mem = Context.Allocate(totalSizeToAlloc<unsigned, char>(1,Bytes),
alignof(ListOfLiteralExpr));
auto * E = new (Mem)
ListOfLiteralExpr(Context, LBraceLoc, Values, Ty, RBraceLoc);
*E->getTrailingObjects<unsigned>() = Bytes;
return E;
}
¡Hay mucha maquinaria compleja ahí! Esto estaría en la memoria:
ListOfLiteralExpr instance| unsigned: number of bytes | char[Bytes]: the values
char[] ?
Sí, ListOfLiteralExpr está destinado a almacenar cualquier tipo de literal entero y estos pueden ser de diferentes tamaños. Y así almacenar una matriz de uint64_t sería ineficiente. Entonces, en su lugar, podemos almacenar una matriz de char y reinterpret_cast para escribir correspondiente al tamaño de nuestros valores enteros. Esto falla por completo si la plataforma de destino no tiene bytes de 8 bits. No me importaba en absoluto.
Ese truco se puede implementar con elegancia:
#include <tuple>
uint64_t f(const char* bytes, unsigned byte_size, unsigned index) {
template for (constexpr auto dummy :
std::tuple<uint8_t, uint16_t, uint32_t, uint64_t>()) {
if(byte_size == sizeof(dummy)) {
return reinterpret_cast<const decltype(dummy)*>(bytes)[index];
}
}
__builtin_unreachable();
}
Oh espera. Eso no se compilará hasta C++23. (Pero se compilará en el explorador del compilador). Tenemos que escribir manualmente muchas declaraciones if. O definir un Macr…
Ni siquiera vayas allí. Yo Te reto. Te reto el doble.
Ahora que todos nuestros números enteros están bien empaquetados en la memoria, el código de serialización es fácil:
void ASTStmtWriter::VisitListOfLiteralExpr(ListOfLiteralExpr* E) {
VisitExpr(E);
const auto S = E->sizeOfElementsAsUint64();
Record.writeUInt64(S);
Record.AddSourceLocation(E->getLBraceLoc());
Record.AddSourceLocation(E->getRBraceLoc());
Record.AddTypeRef(E->getInitsType());
Record.writeUInt64(E->getNumInits());
const auto Elems = E->getElementsAsUint64();
Record.append(Elems, Elems + S);
Code = serialization::EXPR_INIT_LITERALS_LIST;
}
Podría haber hecho un poco de trampa. Mira, el tipo subyacente de serialización es un flujo de uint64_t .Así que me aseguré de que mis bytes sean un múltiplo de sizeof(uint64_t) .Puede ser un poco desagradable. Pero no me importa porque
- Puedo copiar todo de manera eficiente
- Solo uso tantos bytes como necesito, mientras que los literales de cadena en los módulos clang usan un
uint64_tpara todos y cada uno de los personajes. No es que a nadie le deba importar mucho:el disco es barato
Leer es todo lo contrario.
Por cierto, esta es la razón por la que distribuir módulos compilados es una idea terrible:la serialización nunca se puede optimizar una vez que las personas comienzan a hacerlo. No.
Ahora podemos hacer algunos benchmarks con módulos
// Baseline
int i[] = {1, /*...*/, 1};
int main() {}
//Module
export module M;
export int i[] = {1, /*...*/, 1};
//importer
import M;
int main() {}
Los módulos parecen proporcionar algunos beneficios de rendimiento, pero estos beneficios no son evidentes hasta que la matriz es extravagantemente grande, más de 100 MB de datos binarios.
Una conclusión agridulce
Si soy generoso conmigo mismo, puedo estar un 20 % a favor de algo utilizable en producción y eventualmente fusionable en LLVM. De los muchos todos:
- Compatibilidad con puntos flotantes y caracteres literales:
- Integración mejor y más sensata en Sema Init
- Integración en herramientas
- Vea si la compilación constexpr de la matriz se puede mejorar aún más
Hay unas cuantas semanas más de esfuerzo. Y seguro, objetivamente, hice que el sonido resonara notablemente más rápido. En algunas cargas de trabajo. Cargas de trabajo poco realistas, tal vez. Los perfiladores y los gráficos bonitos son seductores. El sobreajuste es una forma segura de producir números estupendos. No creo que esté calificado para responder eso. La verdad es que tengo bastante claro que, algunos //FIXME a pesar de aquí y allá, LLVM es una máquina bien optimizada, y solo pude obtener algunas mejoras quitando capas de abstracciones. ¿Los mantenedores de clang agradecerían la mayor complejidad?
Sin embargo, hay otra forma de verlo:las personas se preocupan por los tiempos de compilación hasta el punto de sacrificar la capacidad de mantenimiento de su código por un ligero aumento en la velocidad de compilación.
Por un momento, puedo lamentar que el tiempo de compilación sea lo último para lo que la gente debería optimizar. Unos pocos microsegundos aquí y allá en Clang benefician a millones de personas.
Por otra parte, probablemente sería más inteligente poner esa energía en std::embed , ¡que supera todas las optimizaciones presentadas aquí por órdenes de magnitud!
Referencias y herramientas
Esta publicación de blog terminó representando aproximadamente una semana de trabajo. Confrontado con una gran base de código, solo puedo recomendar hardware y herramientas robustos:
- Valgrind, Vtune, Perf y Hotspot para análisis de rendimiento
- C-Reduce, una herramienta muy útil para encontrar el código más pequeño que reproduzca un bloqueo del compilador
- Compiler Explorer, el único compilador de C++ que uno debería necesitar
- FlameGraph y Plotly para generar los gráficos para la publicación de blog actual, con la ayuda de algunas secuencias de comandos de Python desagradables.
Las fuentes de LLVM ahora se encuentran en un increíble repositorio de Github fácil de clonar.
Puede encontrar el parche para ese artículo aquí.
No esperes nada de él:¡es un desarrollo impulsado por publicaciones de blog!
Gracias por leer, ¡déjame saber lo que piensas!