En otra publicación de invitado, Matt Bentley nos brinda nuevos conocimientos sobre el rendimiento de los contenedores, analizando las implicaciones en los costos de iteración de su implementación del concepto de "matriz de cubos".
En 2014 comencé a diseñar un motor de juego. Los programadores experimentados y los profesores cascarrabias te dirán que si haces un motor de juego, nunca harás un juego, lo cual es cierto, pero algo irrelevante. Aprenderás mucho al hacer un motor de juego, probablemente no te preocupes por el juego al final. La principal razón por la que quería desarrollar un motor de juego era que estaba cansado de ver juegos 2D muy básicos con un rendimiento increíblemente malo, incluso en computadoras rápidas. Si obtuvimos 15 fotogramas por segundo en los procesadores Intel 386 en la década de 1990, ¿por qué fue tan difícil para los juegos 2D modernos lograr la misma velocidad en un hardware exponencialmente mejor?
La razón principal parecía ser motores de juegos ineficientes y el uso de protocolos de gráficos no nativos con poca compatibilidad con versiones anteriores para equipos más antiguos. La mayoría de los juegos parecían ejecutarse con Unity, que en ese momento era muy lento para el trabajo en 2D, o requerían OpenGL 2.0, que en ese momento no era compatible con muchos equipos de menor especificación como mi 2009 basado en Intel Atom. netbook (todavía funcionando hasta el día de hoy, por cierto). Entonces, lo primero que hice fue desarrollar mi motor sobre el marco SDL2 (Simple Directmedia Layer), que usa el protocolo de gráficos nativo de cualquier plataforma en la que se esté ejecutando:DirectX para Windows, Quartz para MacOS, etcétera.
Lo segundo fue tratar de atender una amplia gama de escenarios de juegos en 2D, al mismo tiempo que introducía la menor cantidad posible de gastos generales. Esto significó aprender sobre quadtrees, los diversos contenedores disponibles en la biblioteca estándar de C++ y un montón de otras cosas relacionadas con el rendimiento. Al contrario de lo que piensan muchos que no son desarrolladores de juegos, diseñar un motor de juego es una de las cosas más complicadas que puede hacer, en cuanto a la programación. Realmente es bastante alucinante. El número de interacciones entre las diferentes partes de un juego es fenomenal. A pesar de eso, eventualmente logré encontrar algo razonablemente comprensible.
Sin embargo, seguí enfrentándome a un escenario particular. Para explicar más, debe comprender que la mayoría de los datos en los juegos tienen las siguientes características:
1. Se introduce en algún momento durante un nivel.
2. Se elimina o se destruye en algún momento durante un nivel.
3. Tiene una gran cantidad de interacciones y dependencias de otros datos (texturas, sonidos, etcétera).
4. Casi siempre hay más de uno de un tipo de datos determinado.
5. El orden secuencial de los datos generalmente no es relevante.
Esto no es una buena opción para el contenedor de datos std::vector de C++, que, si tuviera que creerle a la mayoría de la gente de C++, es el contenedor que debe usar para la mayoría de las cosas. La razón por la que no encaja bien es porque los vectores reasignan los objetos (elementos) que contienen en la memoria, tanto al insertar como al borrar cualquier elemento que no esté en la parte posterior del vector. Esto significa que los punteros a elementos vectoriales se invalidan, y luego todas las interacciones y dependencias de sus elementos ya no funcionan. Claro, puede acceder a los elementos a través de índices en lugar de punteros, pero sus índices también se invalidarán si borra o inserta en cualquier lugar que no sea la parte posterior del vector.
Hay una amplia gama de soluciones para std::vector en esta situación, cada una de las cuales podría escribir una publicación, pero ninguna se adapta ampliamente a todos los escenarios de motores de juegos y todas crean una sobrecarga computacional. Hay otros contenedores en la biblioteca estándar de C++ que hacen garantizar la validez del puntero posterior a la inserción/borrado, como include std::map y std::list, pero todos estos tienen un rendimiento de iteración terrible en el hardware moderno. Esto se debe a que no asignan sus elementos linealmente en la memoria, es decir, en un fragmento de memoria, sino que asignan elementos individualmente.
En comparación, un std::vector es básicamente solo una matriz que se copia en otra matriz más grande cuando está llena y se produce una inserción, por lo que es 100% lineal en la memoria. Debido al hecho de que las CPU modernas leen datos en el caché desde la memoria principal en fragmentos contiguos, si lee un elemento de un std::vector terminará leyendo un montón de elementos subsiguientes en el caché al mismo tiempo, siempre que los elementos en pregunta son al menos la mitad del tamaño del fragmento de lectura. Si está procesando elementos secuencialmente, esto significa que cuando procese el segundo elemento, ya estará en la memoria caché.
Si estás interesado en este tema, seguro que has visto esta tabla o algo muy parecido antes, pero para aquellos que no lo han hecho, lo reproduzco aquí:
| ejecutar instrucción típica | 1/1 000 000 000 s =1 nanoseg |
| obtener desde la memoria caché L1 | 0,5 nanosegundos |
| predicción errónea de rama | 5 nanosegundos |
| obtener desde la memoria caché L2 | 7 nanosegundos |
| Bloqueo/desbloqueo de exclusión mutua | 25 nanosegundos |
| obtener de la memoria principal | 100 nanosegundos |
| envía 2K bytes a través de una red de 1 Gbps | 20.000 nanosegundos |
| leer 1 MB secuencialmente de la memoria | 250.000 nanosegundos |
| obtener desde la nueva ubicación del disco (buscar) | 8 000 000 nanosegundos |
| leer 1 MB secuencialmente desde el disco | 20 000 000 nanosegundos |
| enviar paquete de EE. UU. a Europa y viceversa | 150 milisegundos =150 000 000 nanosegundos |
(fuente:http://norvig.com/21-days.html#answers)
Para la mayoría de las computadoras modernas, acceder a los datos en el caché L1 es entre 100 y 200 veces más rápido que acceder a ellos en la memoria principal. Esa es una gran diferencia. Entonces, cuando tiene una gran cantidad de datos para procesar, desde el lado del rendimiento, desea que se asigne linealmente en la memoria y desea procesarlos secuencialmente. Cuando usa una std::list, puede tener la ventaja de poder preservar la validez del puntero para elementos individuales independientemente de la inserción/borrado, pero debido a que no tiene garantía de almacenamiento de memoria lineal, es poco probable que los elementos subsiguientes se lean en el caché al mismo tiempo que el primer elemento, por lo que la velocidad del procesamiento secuencial se reduce.
Una vez que entendí esto, comencé a buscar alternativas. La primera solución que se me ocurrió fue en retrospectiva, bastante tonta y demasiado complicada. Era esencialmente un contenedor similar a un mapa que usaba los punteros originales a los elementos como claves. La arquitectura de esto era dos vectores:uno de puntero + pares de índice, uno de los elementos mismos. Cuando accedió a un elemento a través de su puntero, el contenedor realizó una búsqueda en los pares de punteros y devolvió el elemento a través de su índice en el segundo vector. Cuando ocurría la reasignación de elementos en el segundo vector debido a borrados o inserciones, los índices en el primer vector se actualizaban.
Le envié esto a Jonathan Blow, diseñador de los juegos Braid y The Witness, quien en esos días era algo menos famoso y aparentemente tenía más tiempo para educar a un neófito. Su opinión fue:no muy buena. Le pregunté cómo se vería "bueno" en este escenario, y habló sobre tener una matriz de punteros, cada uno apuntando a elementos en una segunda matriz, y luego actualizando la primera matriz cuando los elementos en la segunda se reasignan. Luego, el programador almacenaría punteros a los punteros en la primera matriz y eliminaría la referencia doble para obtener los elementos mismos. Pero también mencionó otro enfoque, el de tener una lista enlazada de múltiples fragmentos de memoria.
La ventaja del segundo enfoque era que no tendría que ocurrir ninguna reasignación tras la expansión de la capacidad del contenedor. Eso me interesó más, así que comencé a trabajar en algo similar, usando un campo de salto booleano para indicar los elementos borrados para que pudieran omitirse durante la iteración y tampoco fuera necesaria la reasignación de elementos durante el borrado. Más tarde descubrí que este concepto general a menudo se conoce como una "matriz de cubos" en la programación de juegos, y también existe en otros dominios de programación con varios nombres. Pero eso no sería hasta dentro de varios años, así que por ahora lo llamé una 'colonia', como una colonia humana donde la gente va y viene todo el tiempo, las casas se construyen y se destruyen, etcétera.
Mi implementación en realidad terminó siendo sustancialmente diferente de la mayoría de las matrices de cubos; por lo general, todos los "cubos" o bloques de memoria tienen un tamaño fijo. Colony siguió un principio de sentido común propugnado por la mayoría de las implementaciones de std::vector, que es:cada vez que el contenedor tiene que expandirse, duplica su capacidad. Esto funciona bien cuando el programador no sabe de antemano cuántos elementos se almacenarán, ya que el contenedor puede comenzar con una asignación de memoria muy pequeña para la primera inserción y luego crecer adecuadamente según la cantidad de inserciones que se hayan producido. También hice que los tamaños de bloque mínimos/máximos sean especificables, para adaptarse mejor a escenarios particulares y tamaños de caché.
Además, las matrices de cubos no tienden a reutilizar la memoria de los elementos borrados; en cambio, los nuevos elementos se insertan en la parte posterior del contenedor y los bloques de memoria se liberan para el sistema operativo cuando se vacían de elementos. Colony mantiene un registro de las ubicaciones de memoria de los elementos borrados y reutiliza esas ubicaciones al insertar nuevos elementos. Esto es posible porque es un contenedor desordenado (pero clasificable). Hacerlo tiene dos ventajas de rendimiento:se producen menos asignaciones/desasignaciones porque la memoria se reutiliza, y la reutilización de espacios de memoria ayuda a mantener los elementos más lineales en la memoria, en lugar de conservar grandes porciones de memoria no utilizada entre elementos no borrados.
En 2015 logré convertir a colony en un contenedor de plantillas de C++ completo (aunque con errores), lo que significa que podría usarse para almacenar cualquier tipo de datos. El rendimiento fue bastante bueno, de acuerdo con mis puntos de referencia (también con errores en ese momento). Todavía había una cosa que me molestaba me aunque. El acceso a nivel de bits es más lento que el acceso a nivel de bytes en una computadora moderna, pero usar un byte completo para un valor booleano en un campo de salto parecía un desperdicio; específicamente, usa 8 veces la cantidad de memoria que necesita. Así que pensé en cómo podría aprovechar los bits adicionales para crear un mejor rendimiento. Tenía algunas ideas, pero las resté importancia en mi propia mente.
Un día en la GDC 2015 de Nueva Zelanda, después de presentar una charla sobre Colony, me puse a hablar con un ex desarrollador de Lionhead que se había mudado de vuelta a Nueva Zelanda. El tipo era tan arrogante que me hizo enojar un poco. Esa noche, acostado en la cama y ligeramente furioso, canalicé la ira pensando en ese problema particular con Colony, y de repente, repasando las ecuaciones en mi cabeza, tuve una solución. Consejo profesional:nunca hagas enojar a un programador, podrías hacerlo mejor programando. Al día siguiente, mientras regresaba a casa en autobús, comencé a codificar lo que eventualmente se llamaría el patrón de campo saltado de conteo de saltos de alta complejidad.
La idea es extremadamente simple:en lugar de dejar que todos esos bits adicionales en el byte se desperdicien, utilícelos para contar la cantidad de elementos borrados que debe omitir para llegar al siguiente elemento no omitido. Entonces, mientras que un campo de salto booleano se ve así (donde '0' indica un elemento para procesar y '1' indica uno que se borra/se salta):
1 0 0 0 0 1 1 1 1 0 0 1 1
El campo de omisión de conteo de saltos de alta complejidad equivalente se ve así:
1 0 0 0 0 4 2 3 4 0 0 2 2
El primer '4', por supuesto, indica que debemos omitir cuatro espacios de memoria de elementos borrados en ese punto. El segundo 4 es el mismo pero para la iteración inversa. Los números intermedios, bueno, se vuelve un poco complicado, pero básicamente se usan cuando los espacios de memoria de elementos borrados se reutilizan, de modo que la serie de elementos borrados (o "bloque de salto") se puede dividir cuando una memoria no posterior / frontal el espacio se reutiliza. Ahora, por supuesto, si estamos expresando el campo de salto en bytes, eso significa que solo podemos contar hasta 255 elementos saltados a la vez. Esto limita efectivamente la capacidad de cada bloque de memoria en la colonia a 256 elementos, lo que no es muy bueno para la compatibilidad con la memoria caché, a menos que el tipo en sí sea razonablemente grande.
Así que actualicé el token de skipfield de tamaño de byte a un corto sin firmar (equivalente a uint_least16). Esto mejoró la capacidad máxima posible de bloques de memoria individuales a 65535 elementos en la mayoría de las plataformas. Probé entradas sin firmar, para una capacidad máxima posible de 4294967295, pero esto no logró ninguna mejora en términos de rendimiento en todos los tipos. Eventualmente, el tipo skipfield se convirtió en un parámetro de plantilla, de modo que los usuarios podían cambiar al tipo de caracteres sin firmar y ahorrar memoria y rendimiento para un número de elementos inferior a 1000.
Para volver a la iteración, mientras que el código de iteración para un campo de salto booleano se ve así en C++ (donde 'S' es la matriz de campo de salto e 'i' es el índice actual tanto en la matriz de campo de salto como en su correspondiente matriz de elementos):
hacer {
++i;
} mientras (S[i] ==1);
El código de iteración para el skipfield de conteo de saltos se ve así:
++i;
i +=S[i];
Lo que significa que, en comparación con un campo de salto booleano, una iteración de campo de salto que cuenta saltos (a) no tiene bucles y, por lo tanto, tiene menos instrucciones por iteración, y (b) no tiene ramificaciones. (a) es importante para grandes cantidades de datos. Imagínese si tuviera 6000 elementos borrados seguidos saltados en un campo de salto booleano; eso significaría 6000 lecturas del campo de salto y 6000 instrucciones de bifurcación, ¡solo para encontrar el siguiente elemento no borrado! En comparación, el skipfield de conteo de saltos solo necesita una lectura de skipfield por iteración y 2 cálculos en total. (b) es importante porque en los procesadores modernos, la bifurcación tiene un impacto problemático en el rendimiento debido a la canalización de la CPU.
Las canalizaciones permiten que múltiples instrucciones secuenciales se ejecuten en paralelo en una CPU cuando sea apropiado; esto solo sucede si las instrucciones no dependen de los resultados de los demás para la entrada. La ramificación reduce la eficiencia de la canalización al evitar que se procesen todas las instrucciones secuenciales posteriores hasta que se haya producido esta decisión. Los algoritmos de predicción de bifurcaciones en las CPU intentan aliviar este problema prediciendo, en función de decisiones de bifurcación pasadas, cuál es probable que sea la decisión de bifurcación y prealmacenando el código resultante de esa decisión en la canalización.
Pero algunas CPU son mejores que otras en esto y, a pesar de todo, siempre hay algunas impacto en el rendimiento de una predicción de bifurcación fallida. Tome los siguientes puntos de referencia comparando una versión anterior de colony usando un skipfield booleano para denotar borrados, versus std::vector usando un skipfield booleano para denotar borrados, y una colonia usando un skipfield de conteo de saltos. Las pruebas se realizaron en un procesador Core2, ahora una CPU obsoleta, pero demuestran un punto. Muestran el tiempo necesario para iterar, después de que se haya borrado un cierto porcentaje de todos los elementos, al azar:
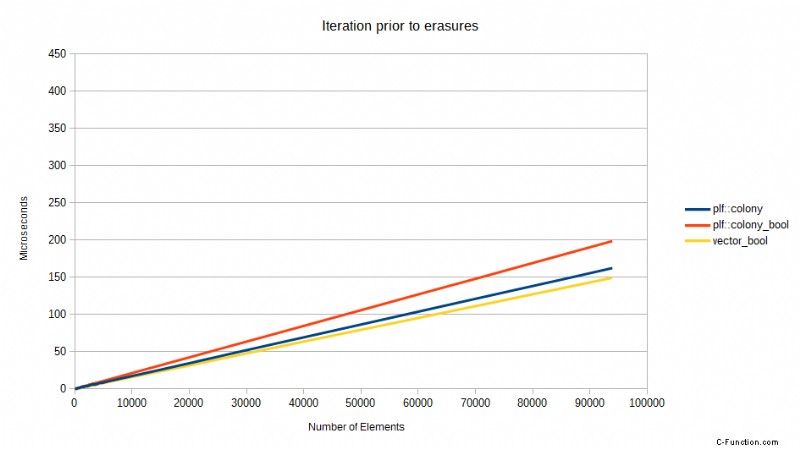
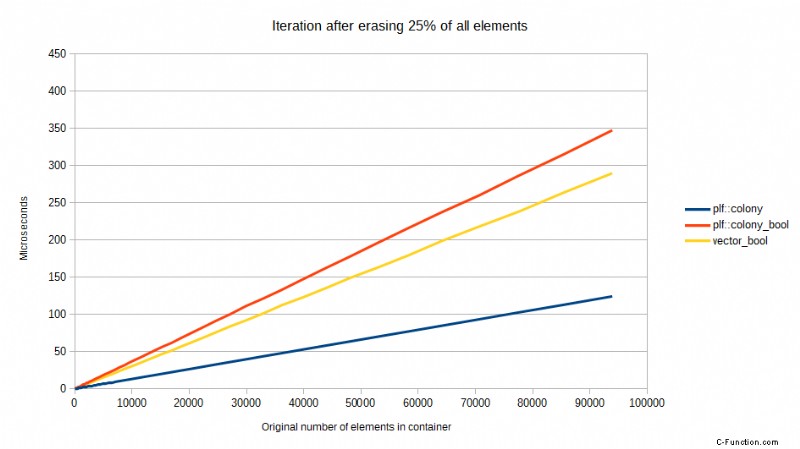
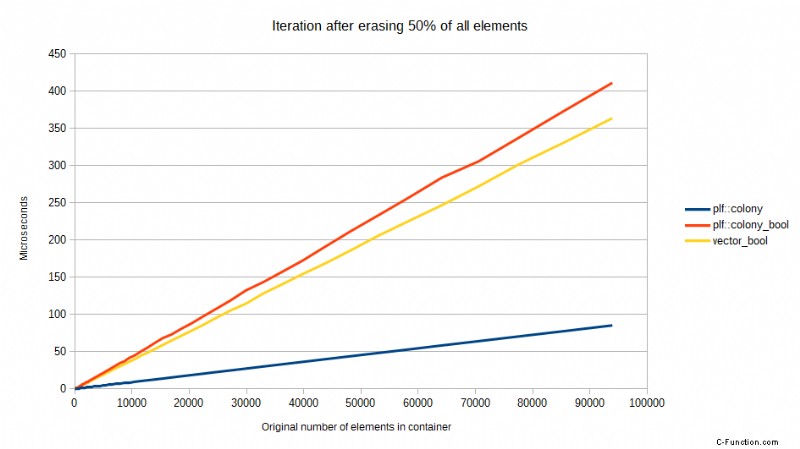
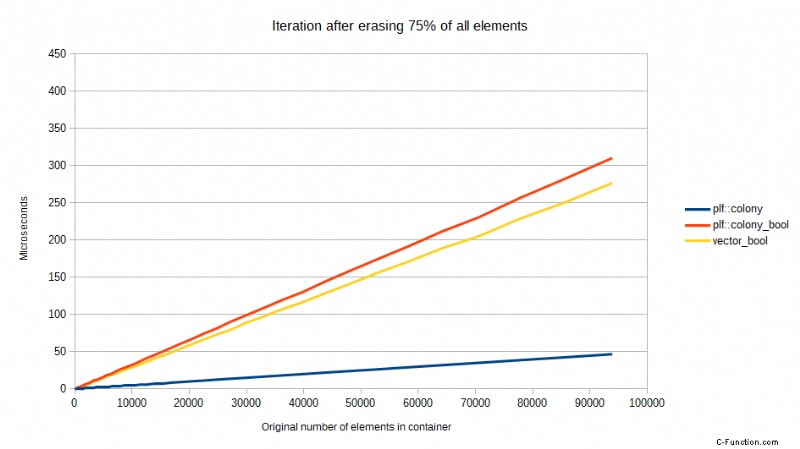
Estos puntos de referencia muestran un patrón extraño pero predecible en última instancia. Cuando no se ha borrado ningún elemento, el std::vector es el más rápido, mientras que la versión booleana de colony es la más lenta. Cuando se ha borrado el 25% de todos los elementos, de repente la colonia de conteo de saltos es significativamente más rápida que ambos enfoques booleanos. Cuando se ha borrado el 50%, hay una caída masiva en el rendimiento de los enfoques booleanos, pero el skipfield de conteo de saltos vuelve a funcionar mejor. Cuando se alcanza el 75 % de borrados, los dos enfoques booleanos funcionan mejor que con el 50 % de borrados, al igual que el enfoque de conteo de saltos. ¿Por qué es esto?
Bueno, resulta que hay un costo significativo para una predicción de bifurcación fallida en un procesador Intel Core2:los modelos posteriores de procesadores Intel tienen un mejor rendimiento aquí, pero aún se ven afectados. Cuando no se han producido borrados, el predictor de bifurcación puede ser correcto siempre, por lo que el vector con el campo de salto booleano es más rápido en ese punto (debido a su bloque de memoria singular en oposición a los bloques de memoria múltiples de la colonia). Sin embargo, una vez que obtiene el 25 % de borrados, la predicción de bifurcación solo puede ser correcta el 75 % de las veces, estadísticamente hablando. Cuando falla, la CPU tiene que vaciar el contenido de su canalización.
Con un 50% de borrados aleatorios, la predicción de bifurcación básicamente no puede funcionar:la mitad o más de todas las predicciones de bifurcación fallarán. Una vez que llegamos al 75 % de borrados, la predicción de bifurcación vuelve a ser correcta el 75 % de las veces, por lo que el rendimiento booleano de skipfield aumenta en comparación con el 50 %. Mientras tanto, el único factor de rendimiento relevante para el skipfield de conteo de saltos, que no tiene instrucciones de bifurcación durante la iteración, es el número total de lecturas del skipfield que debe realizar, que se reduce proporcionalmente al porcentaje de borrados. A partir de este ejemplo, ya podemos ver que un skipfield de conteo de saltos es más escalable que un skipfield booleano.
Mientras tanto, para las CPU sin penalizaciones tan severas por fallas en la predicción de bifurcaciones, la diferencia en los resultados entre los campos de salto booleanos y de conteo de saltos tiende a escalar proporcionalmente al porcentaje de borrado. Para un procesador Intel i5 de tercera generación, los resultados son los siguientes. Esta vez estoy mostrando una escala logarítmica para dar una visión más clara de las diferencias para una pequeña cantidad de elementos. También estoy usando un vector recto en lugar de un vector con bools para borrados, solo para dar una idea de cómo funciona el recorrido de elementos de colonia en comparación con el recorrido de memoria lineal sin espacios:
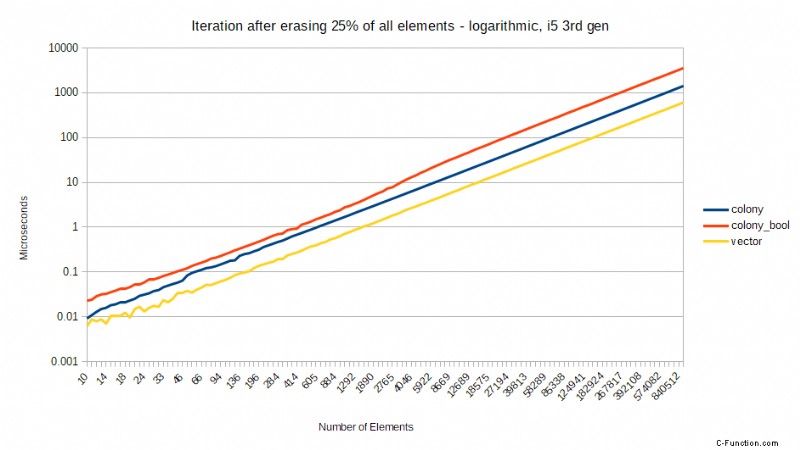
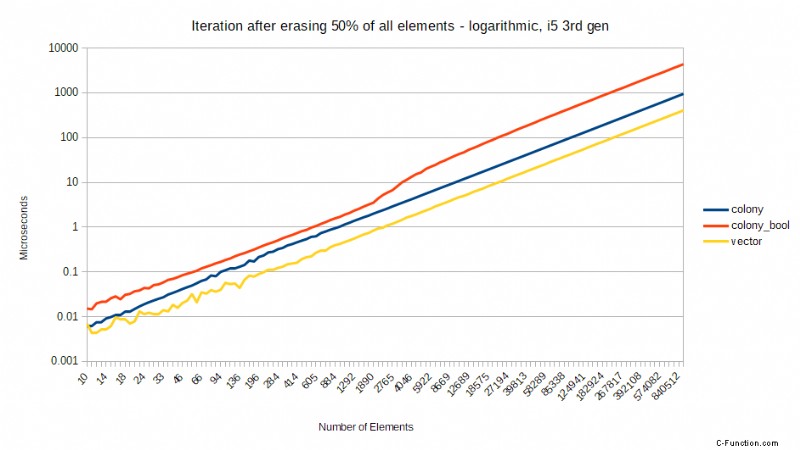
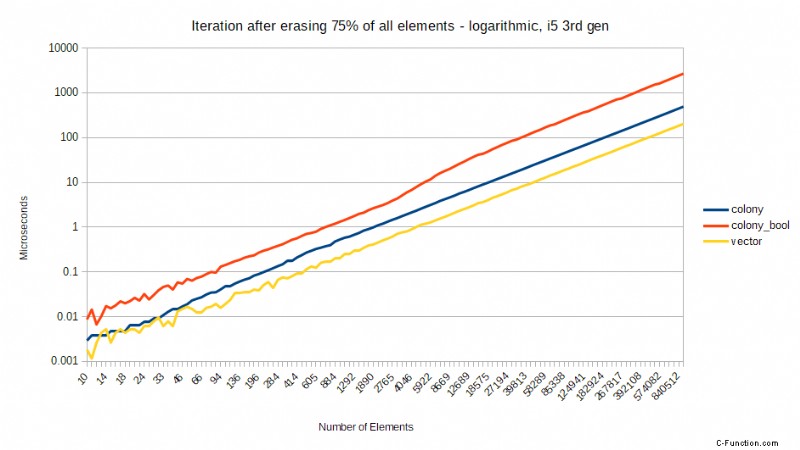
Como puede ver, la colonia con un skipfield de conteo de saltos permanece relativamente equidistante de std::vector en todos los niveles de borrado, y el rendimiento aumenta a medida que aumenta el número de borrados. La colonia con un campo de salto booleano empeora proporcionalmente a medida que aumenta el porcentaje de borrados; en promedio, 2 veces más de duración que el conteo saltado al 25 % de borrados, 3 veces más largo al 50 % de borrados y 4 veces más largo al 75 % de borrados. Esto refleja el número cada vez mayor de instrucciones necesarias para llegar al siguiente elemento cuando se utiliza un campo de salto booleano. Aun así, todavía hay un rendimiento ligeramente peor con un 50 % de borrados para el campo de salto booleano que con un 75 % de borrados, lo que indica una vez más que el error de predicción de bifurcación influye en los resultados. El tamaño de la instrucción de iteración O(1) libre de saltos del skipfield de conteo significa que no sufre ninguno de estos destinos.
Este conteo fijo de instrucciones para la iteración ha jugado bien en la oferta de Colony para convertirse en un contenedor de biblioteca estándar de C++. Los contenedores de C++ no pueden tener operaciones iteradoras que no tengan una complejidad de tiempo amortizado O(1), es decir, la cantidad de instrucciones necesarias para completar la operación debe ser aproximadamente la misma cada vez. Los campos de salto booleanos requieren un número desconocido de instrucciones (es decir, el número de repeticiones del ciclo mencionado anteriormente) para iterar, por lo que no son apropiados. La complejidad del tiempo no es muy importante para el rendimiento general hoy en día, pero afecta la latencia, que a veces puede ser importante.
Para los campos que favorecen la baja latencia, como el comercio y los juegos de alto rendimiento, un número desconocido de instrucciones puede, por ejemplo, anular la visualización oportuna de un búfer en un juego de computadora o perder la ventana de un trato comercial en particular. Entonces, el intercambio de tipos de skipfield tuvo un fuerte beneficio allí. Sin embargo, para mí personalmente, lo más importante para mí fue que la cantidad de bits ya no se desperdiciaba:aumentaban significativamente el rendimiento. En algunas situaciones, como escenarios de poca memoria, o donde el espacio de caché es especialmente limitado, aún podría tener más sentido optar por un campo de bits, pero ese tipo de situación generalmente necesita una solución personalizada de todos modos.
Con el paso de los años, la colonia se transformó bastante. El skipfield de conteo de saltos de alta complejidad fue reemplazado por una variante de baja complejidad con un mejor rendimiento general. El mecanismo inicial de almacenamiento de ubicación de elementos borrados, que era una pila de punteros de ubicación de elementos borrados, se reemplazó con listas libres por bloque de memoria de elementos borrados individuales, y luego por listas libres de bloques consecutivos de elementos borrados en lugar de ubicaciones individuales. Se han introducido muchas funciones y se ha producido mucha optimización. Durante el año pasado, alcanzó un punto de estabilidad.
Pero la estructura central básicamente se ha mantenido igual. Obtuve mi contenedor con ubicaciones de puntero fijas para elementos no borrados y, con suerte, el mundo también obtendrá algo de él. Aprendí mucho sobre CPU y arquitectura en el proceso. Sin embargo, lo más importante que aprendí fue que, con la mentalidad correcta, puedes marcar la diferencia. Esa mentalidad tiene que tener cierto nivel de impulso, pero también un elemento de altruismo, en realidad. Porque si no estás haciendo algo en parte por ti mismo, es difícil de sostener. Pero si no lo estás haciendo por los demás también, entonces, a largo plazo, no tiene sentido.
…Ah, y nunca terminé haciendo un juego 😉