
Los algoritmos STL son un fantástico conjunto de herramientas para mejorar la expresividad y la corrección de su código. Como se describe en la famosa charla C++ Seasoning de Sean Parent, la realidad es bastante sencilla:uno necesita conocer sus algoritmos.
Esta publicación te explica cómo se deben usar los algoritmos STL y qué pueden aportarte.
Algoritmos frente a bucles
Comencemos con un ejemplo de código que podría encontrarse en el código de producción. ¿Podría decir qué hace este código?
for (std::vector<company::salesForce::Employee>::const_iterator it = employees.begin(); it != employees.end(); ++it)
{
employeeRegister.push_back(*it);
}
Si eres como la mayoría de los desarrolladores que conozco, escanearás este código y te darás cuenta en 10 a 15 segundos de que este código hace una copia. de los elementos de la colección de empleados a algún registro.
Ahora, ¿puedes decir qué hace este segundo fragmento de código?
std::copy(employees.begin(), employees.end(), std::back_inserter(employeeRegister));
Incluso si no sabe lo que significa std::back_inserter (lo que sabrá de todos modos, si continúa leyendo la siguiente sección), puede instantáneamente sepa que los empleados se copian en un registro, porque está escrito en el código:copiar . En este ejemplo individual de dos líneas, la diferencia de tiempo no es tan grande, es solo de 10 a 15 segundos. Pero cuando multiplicas esto por el número de líneas en tu base de código, y cuando consideras casos de uso más complejos, esto realmente empeora la lectura del código.
std::copy es un algoritmo de STL, y puede ser encontrado por #include ing el encabezado <algorithm> . Me doy cuenta de que algunas cosas en este código son más ruido que información, como .begin() y .end(), por ejemplo, pero esto se refinará con rangos, que exploraremos en una publicación dedicada. De todos modos, este uso de STL establece la base para indicar explícitamente qué acción se realiza.
Básicamente, los algoritmos STL dicen qué lo hacen, no cómo ellos lo hacen. Esto realmente se relaciona con Respetar los niveles de abstracción, como se explica en la publicación dedicada a este principio central.
std::copiar y std::back_inserter
Si obtiene que el código anterior hace una copia pero aún no conoce los detalles de std::copy y std::back_inserter, profundicemos en ello ahora mismo. Este es un ejemplo importante de entender porque es bastante común. De lo contrario, puede pasar a la siguiente sección.
std::copy toma tres iteradores en input:
- El comienzo y fin del rango de entrada, que contiene los elementos que se van a copiar
- El comienzo de la salida rango, donde se deben poner las copias
Aquí está su prototipo:
template <typename InputIterator, typename OutputIterator> OutputIterator copy(InputIterator first, InputIterator last, OutputIterator out);
En STL, el comienzo de un rango es un iterador que apunta a su primer elemento y, por convención, el final de un rango es un iterador que apunta a uno después su último elemento:

El iterador de salida de std::copy es el comienzo del rango en el que se copiarán los elementos.
std::copy itera sobre los rangos de entrada y sucesivamente copia todos los elementos en el rango comenzando con el iterador de salida:
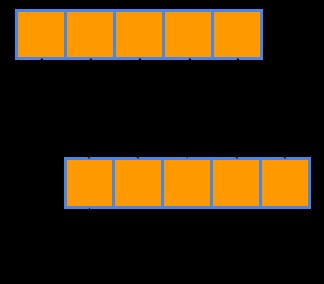
Como se ve en la figura anterior, std::copy necesita algo de espacio en la colección de salida para colocar todos los elementos que copia de la entrada. Sin embargo, la mayoría de las veces, calcular de antemano cuánto espacio se debe hacer en la colección de salida y cambiar su tamaño no es práctico.
Aquí es donde std::back_inserter entra en juego. std::back_inserter crea un iterador que está conectado al contenedor que se le pasa. Y cuando escriba a través de este iterador, de hecho llamará al método push_back de este contenedor con el valor que está tratando de escribir. Esto evita que el programador, usted, cambie el tamaño de la colección de salida si es un vector (como lo es en la mayoría de los casos), porque el iterador de salida crea espacio directamente cada vez que std::copy escribe a través de él.
Como resultado, el código que usa std::copy se puede escribir de esta manera:
std::copy(employees.begin(), employees.end(), std::back_inserter(employeeRegister));
Esto es C++ normal. Esto es lo que ofrece el lenguaje de forma nativa a partir de este escrito (<=C++17), aunque el tema de los rangos permite ir mucho más allá. Debería poder leer dicho código y no tener miedo de escribirlo.
Las ventajas de usar algoritmos
Como se explicó anteriormente, una de las principales ventajas que aportan los algoritmos es la expresividad, al elevar el nivel de abstracción del código. Es decir, muestran qué lo hacen, en lugar de cómo se implementan.
Sin embargo, también traen consigo varias otras ventajas:
- Evitan algunos errores comunes , como errores de uno en uno o tratar con colecciones vacías. Cuando escribe un bucle for, siempre debe asegurarse de que se detenga en el paso correcto y se comporte correctamente cuando no haya ningún elemento sobre el que iterar. Todos los algoritmos se ocupan de esto por usted.
- Al usar algoritmos STL, obtienes una implementación de cierto nivel de calidad . Estos algoritmos han sido implementados por personas que sabían lo que estaban haciendo y se han probado exhaustivamente. Al usarlos, se beneficia de este nivel de calidad.
- Los algoritmos STL te brindan la mejor complejidad algorítmica puedes obtener.
std::copyes bastante sencillo hacerlo bien, pero hay otros algoritmos más complejos que podrían implementarse ingenuamente en O(n²) pero que podrían optimizarse a O(n), por ejemplo, como algoritmos en conjuntos. STL ofrece la mejor implementación en este sentido.
- El diseño de STL desvincula los algoritmos de los datos con los que operan, de modo que los datos y las operaciones pueden evolucionar de forma independiente, al menos hasta cierto punto.
Dos errores a tener en cuenta al adoptar algoritmos
Con suerte, ya habrá decidido usar algoritmos STL para mejorar su código. Pero antes de comenzar, hay dos trampas clásicas que debe conocer.
No utilice for_each para cada problema
Si vienes del hábito de escribir para bucles, podrías sentirte atraído por std::for_each , porque este algoritmo parece un bucle for. De hecho for_each aplica sucesivamente una función (o funtor o lambda) a todos los elementos de una colección:
template <typename InputIterator, typename Function> Function for_each(InputIterator first, InputIterator last, Function f);
std::for_each es de hecho un algoritmo STL y por esta razón es bueno tenerlo en su caja de herramientas. Pero hay principalmente un caso específico en el que for_each se adapta de forma efectiva:cuando realiza efectos secundarios . De hecho, for_each debe usarse para modificar los elementos de la colección en la que se aplica, o para realizar efectos secundarios en un sentido más general, como enviar información a un registrador o a un servicio externo.
Si, por ejemplo, necesita contar la cantidad de veces que un valor está presente en una colección, no use for_each. Utilice std::count .
Si necesita saber si hay al menos un elemento que satisfaga un predicado en su colección, no use for_each. Utilice std::any_of .
Si necesita saber si todos los elementos de una colección satisfacen un predicado dado, use std::all_of .
Si necesitas saber si una colección es una permutación de otra, de la manera más eficiente posible, usa std::is_permutation .
Y así sucesivamente.
STL ofrece una gran variedad de formas de expresar su intención de hacer que su código sea lo más expresivo posible. Puede beneficiarse de esto eligiendo el algoritmo que mejor se adapte a cada situación dada (o escribir el suyo propio, como veremos en una publicación futura).
Tantos algoritmos
La variedad de algoritmos que hay puede ser algo abrumadora. El segundo escollo al pasar a los algoritmos es que cuando los busca en una referencia como esta, reconocerá un par de ellos, como copiar, contar o encontrar, y verá fácilmente cómo pueden serle útiles.
Pero junto a en la lista hay algoritmos cuyos nombres pueden parecerte misteriosos, como std::lexicographical_compare, std::set_symmetric_difference o std::is_heap_until.
Una reacción natural sería ignorar estos algoritmos de aspecto extraño, porque puede pensar que son muy complicados o diseñados para situaciones específicas que nunca encontrará. Seguro que tuve esta reacción cuando comencé con los algoritmos STL.
Pero esto está mal. Casi todos los algoritmos son útiles en el código del día a día.
Tomemos el ejemplo de std::set_difference . ¿Conoces este algoritmo? Hace una diferencia de conjuntos (un conjunto en el sentido de una colección ordenada, no solo std::set). Es decir, con una colección ordenada A y una colección ordenada B, set_difference genera los elementos en A que no presente en B:
¿Cómo puede ser útil?
Tomemos un ejemplo de un modelo de cálculo que realiza el almacenamiento en caché. Cada vez que se calcula este modelo, produce varios resultados que se pueden agregar a la memoria caché. Representamos el caché como un contenedor asociativo con claves y valores donde se permiten varias claves idénticas, que es para lo que está hecho std::multimap.
Entonces el modelo produce resultados de esta manera:
std::multimap<Key, Value> computeModel();
Y el almacenamiento en caché puede aceptar nuevos datos de esta manera:
void addToCache(std::multimap<Key, Value> const& results);
En la implementación de la función addToCache, debemos tener cuidado de no agregar resultados que ya existen en el caché, para evitar que se acumulen duplicados.
Así es como esto podría implementarse sin usar algoritmos:
for (std::multimap<Key, Value>::const_iterator it = newResults.begin(); it != newResults.end(); ++it)
{
std::pair<std::multimap<Key, Value>::const_iterator, std::multimap<Key, Value>::const_iterator> range = cachedResults.equal_range(it->first);
if (range.first == range.second)
{
std::multimap<Key, Value>::const_iterator it2 = it;
while (!(it2->first < it->first) && !(it->first < it2->first))
{
++it2;
}
cachedResults.insert(it, it2);
}
} No te sugiero que intentes entender el código anterior línea por línea. Más bien, podemos reformular el problema de otra manera:necesitamos agregar al caché los elementos que están en los resultados, pero que no están en el caché. Esto es para lo que está hecho std::set_difference:
std::multimap<Key, Value> resultsToAdd; std::set_difference(newResults.begin(), newResults.end(), cachedResults.begin(), cachedResults.end(), std::inserter(resultsToAdd, resultsToAdd.end()), compareFirst); std::copy(resultsToAdd.begin(), resultsToAdd.end(), std::inserter(cachedResults, cachedResults.end()));
std::inserter es similar a std::back_inserter excepto que llama al método de inserción del contenedor con el que está asociado en lugar de push_back, y compareFirst es una función que definimos para decirle a std::set_difference que compare elementos en sus claves en lugar de en el par clave-valor.
Compara las dos piezas de código. El segundo cuenta lo que hace (una diferencia establecida), mientras que el primero solo invita a descifrarlo. Sin embargo, en este ejemplo en particular, quedan demasiados argumentos que se pasan a set_difference, lo que puede hacer que sea algo difícil de entender cuando no está acostumbrado. Este problema se resuelve principalmente con el concepto de rangos, presentado en esta publicación.
Al igual que entiendes construcciones de lenguaje como if y for , debe comprender los componentes del STL para poder comprender lo que el código intenta decirle. Dicho claramente, necesitas conocer tus algoritmos .
Aprenderlos todos lleva tiempo, pero es una inversión útil. Los presentaré a lo largo de varias publicaciones agrupadas por temas (el primero está programado para el 17 de enero) para que pueda ver la lógica entre ellos. Con suerte, esto debería facilitarle recordar tantos de ellos como sea posible, con la menor cantidad de esfuerzo posible.
Artículos relacionados:
- Respetar los niveles de abstracción
- Rangos:el STL al siguiente nivel