C++ ofrece muchas formas de operar en los elementos de una colección.
Pero, ¿qué hay de operar con los elementos de dos colecciones?
Hay un algoritmo STL que puede tomar dos colecciones:std::transform . Por ejemplo, si queremos multiplicar los respectivos elementos de dos colecciones podemos usar std::transform así:
auto const inputs1 = std::vector<int>{1, 2, 3, 4, 5};
auto const inputs2 = std::set<int>{10, 20, 30, 40, 50};
auto results = std::vector<int>{};
std::transform(begin(inputs1), end(inputs1), begin(inputs2), back_inserter(results), std::multiplies{});
Y desde C++17, std::transform también puede tomar 3 colecciones de entrada.
Pero si queremos componer varios pasos en los algoritmos, por ejemplo, multiplicando solo los elementos cuya suma es menor que 42, entonces ya no podemos usar los algoritmos STL convenientemente.
De vuelta a lo bueno antiguo bucle for:
auto const inputs1 = std::vector<int>{1, 2, 3, 4, 5};
auto const inputs2 = std::set<int>{10, 20, 30, 40, 50};
auto results = std::vector<int>{};
auto input1 = begin(inputs1);
auto input2 = begin(inputs2);
for (; input1 != end(inputs1) && input2 != end(inputs2); ++input1, ++input2)
{
if (*input1 + *input2 < 41)
{
results.push_back(*input1 * *input2);
}
}
Tenga en cuenta que este código realiza una verificación de que no accedemos a elementos más allá del final de inputs2 (que std::transform no). Pero aparte de esta ventaja, es bastante feo hacia el comienzo del bucle.
Necesitamos una mejor manera.
zip
El siguiente paso lógico después de los algoritmos STL son las vistas de rango. ¿Qué tienen que ofrecer los rangos cuando se trata de manipular varias colecciones?
Una vista que ofrece range-v3 (pero que no está planeada para C++20) es view::zip . view::zip toma cualquier cantidad de colecciones y presenta una vista de std::tuple s que contienen los elementos de esta colección.
Entonces podemos combinar view::zip con cualquier otra vista. En nuestro caso, usaremos view::filter y view::transform :
auto const inputs1 = std::vector<int>{1, 2, 3, 4, 5};
auto const inputs2 = std::set<int>{10, 20, 30, 40, 50};
std::vector<int> results = ranges::view::zip(inputs1, inputs2)
| ranges::view::filter([](std::tuple<int, int> const& values){ return std::get<0>(values) + std::get<1>(values) < 41; })
| ranges::view::transform([](std::tuple<int, int> const& values){ return std::get<0>(values) * std::get<1>(values); });
He escrito los tipos de tuplas para dejar claro que las tuplas se pasan, pero podríamos ocultarlas con auto :
std::vector<int> results = ranges::view::zip(inputs1, inputs2)
| ranges::view::filter([](auto&& values){ return std::get<0>(values) + std::get<1>(values) < 41; })
| ranges::view::transform([](auto&& values){ return std::get<0>(values) * std::get<1>(values); });
Este uso de auto en lambdas está en C++14, pero la biblioteca de rangos requiere C++14 de todos modos.
En C++17, también podemos usar enlaces estructurados en lugar de std::get . Esto agrega una declaración en la lambda, pero podría verse mejor:
auto const inputs1 = std::vector<int>{1, 2, 3, 4, 5};
auto const inputs2 = std::set<int>{10, 20, 30, 40, 50};
std::vector<int> results = ranges::view::zip(inputs1, inputs2)
| ranges::view::filter([](auto&& values){ auto const& [a,b] = values; return a + b < 41; })
| ranges::view::transform([](auto&& values){ auto const& [a,b] = values; return a * b; }); ¿Por qué los rangos requieren tuplas, para empezar?
Corrígeme si me equivoco, pero tengo entendido que es porque zip simula una gama de elementos ensamblados de las dos colecciones de entrada. Y en ese rango, el elemento ensamblado no puede estar flotando en el aire, debe almacenarse en algo. Se representan como tuplas.
Aún así, sería bueno no tener que usar tuplas en absoluto. mux lo permite.
mux
mux es un nuevo componente de la biblioteca de tuberías. Toma varias colecciones, las atraviesa y envía sus respectivos elementos a la siguiente tubería en la tubería.
Se puede representar así:
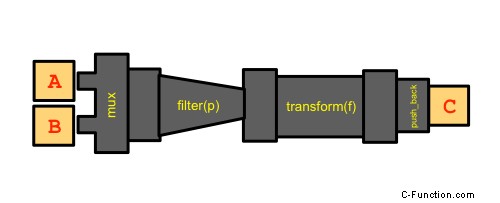
Con el código correspondiente:
auto const input1 = std::vector<int>{1, 2, 3, 4, 5};
auto const input2 = std::vector<int>{10, 20, 30, 40, 50};
auto results = std::vector<int>{};
pipes::mux(input1, input2)
>>= pipes::filter([](int a, int b){ return a + b < 41; })
>>= pipes::transform(std::multiplies{})
>>= pipes::push_back(results); Como puede ver, no se utilizan tuplas.
¿Por qué no mux hay que usar tuplas? Proviene del diseño de la biblioteca de tuberías. A diferencia de los rangos, las tuberías no simulan rangos de elementos ensamblados. Ellos envían datos a la siguiente tubería. Por lo tanto mux envía los elementos respectivos a la tubería siguiente, como en una llamada de función. No se necesita una tupla.
Los rangos y las tuberías tienen diferentes diseños. No es que uno sea mejor o peor, simplemente son diferentes. Esto les permite hacer bien cosas diferentes.
Cómo mux funciona
mux en sí misma es una función bastante tonta:simplemente ensambla varios rangos juntos:
template<typename... Ranges>
struct mux_ranges
{
std::tuple<Ranges const&...> inputs;
explicit mux_ranges(Ranges const&... inputs) : inputs(inputs...) {}
};
template<typename... Ranges>
auto mux(Ranges&&... ranges)
{
static_assert(sizeof...(Ranges) > 0, "There should be at least one range in mux.");
return mux_ranges<std::decay_t<Ranges>...>(FWD(ranges)...);
}
La parte que contiene la lógica es operator>>= . Aquí está su implementación:
template<typename... Ranges, typename Pipeline, detail::IsAPipeline<Pipeline> = true>
void operator>>= (mux_ranges<Ranges...> muxRanges, Pipeline&& pipeline)
{
auto const beginIterators = detail::transform(muxRanges.ranges, [](auto&& range){ return begin(range); });
auto const endIterators = detail::transform(muxRanges.ranges, [](auto&& range){ return end(range); });
for(auto iterators = beginIterators;
!detail::match_on_any(iterators, endIterators);
detail::increment(iterators))
{
sendTupleValues(detail::dereference(iterators), pipeline);
}
} Analicemos este código línea por línea:
auto const beginIterators = detail::transform(muxRanges.ranges, [](auto&& range){ return begin(range); });
auto const endIterators = detail::transform(muxRanges.ranges, [](auto&& range){ return end(range); });
Usamos el algoritmo en tuplas transform para crear una tupla de begin y una tupla de end iteradores fuera de la tupla entrante de rangos.
for(auto iterators = beginIterators;
Creamos una tupla de iteradores, todos inicializados al comienzo de cada uno de los rangos entrantes.
!detail::match_on_any(iterators, endIterators);
Queremos dejar de iterar sobre los rangos entrantes tan pronto como uno de ellos haya llegado a su fin.
Aquí está la implementación de match_on_any :
template<typename... Ts>
bool match_on_any(std::tuple<Ts...> const& tuple1, std::tuple<Ts...> const& tuple2)
{
auto matchOnAny = false;
detail::for_each2(tuple1, tuple2, [&matchOnAny](auto&& element1, auto&& element2)
{
if (!matchOnAny && element1 == element2)
{
matchOnAny = true;
}
});
return matchOnAny;
}
Si conoce el algoritmo de la tupla for_each2 , este código es bastante sencillo. Itera sobre dos tuplas y verifica si tienen al menos un elemento en común.
Volver a la implementación de operator>>= :
detail::increment(iterators))
Incrementamos cada iterador usando el simple for_each esta vez:
template<typename... Ts>
void increment(std::tuple<Ts...>& tuple)
{
for_each(tuple, [](auto&& element){ ++element; });
} Y finalmente:
{
sendTupleValues(detail::dereference(iterators), pipeline);
}
Hay dos funciones en juego aquí. El primero es dereference , que es solo una llamada a operator* en cada iterador de la tupla:
template<typename... Ts>
auto dereference(std::tuple<Ts...> const& tuple)
{
return transform(tuple, [](auto&& element) -> decltype(auto) { return *element; });
}
Y el segundo es sendTupleValues , que envía todos los valores en una tupla a una canalización:
namespace detail
{
template<typename... Ts, typename Pipeline, size_t... Is>
void sendTupleValues(std::tuple<Ts...> const& tuple, Pipeline& pipeline, std::index_sequence<Is...>)
{
send(std::get<Is>(tuple)..., pipeline);
}
}
template<typename... Ts, typename Pipeline>
void sendTupleValues(std::tuple<Ts...> const& tuple, Pipeline& pipeline)
{
detail::sendTupleValues(tuple, pipeline, std::make_index_sequence<sizeof...(Ts)>{});
} Hacer que las tuberías acepten varios valores
Antes de mux entró en la biblioteca, las tuberías como filter y transform solo podía aceptar un valor:
template<typename Predicate>
class filter_pipe : public pipe_base
{
public:
template<typename Value, typename TailPipeline>
void onReceive(Value&& value, TailPipeline&& tailPipeline)
{
if (predicate_(value))
{
send(FWD(value)..., tailPipeline);
}
}
// rest of filter...
Para ser compatible con mux , ahora necesitan manejar varios valores, usando plantillas variadas:
template<typename Predicate>
class filter_pipe : public pipe_base
{
public:
template<typename... Values, typename TailPipeline>
void onReceive(Values&&... values, TailPipeline&& tailPipeline)
{
if (predicate_(values...))
{
send(FWD(values)..., tailPipeline);
}
}
// rest of filter... Operando en varias colecciones
mux permite trabajar sobre varias colecciones sin utilizar tuplas. Pero cubre el caso de uso más básico:reunir varias colecciones y trabajar en los elementos emparejados.
Pero podemos ir más allá en esta dirección. Por ejemplo, generando todas las combinaciones posibles de elementos de las colecciones de entrada. Esto es lo que veremos en una publicación futura, con cartesian_product .
Mientras tanto, todos sus comentarios son bienvenidos en mux ! ¿Qué opinas sobre mux? ? ¿Qué cambiarías?