
Parece que no es fácil mover datos de la CPU a la GPU de manera eficiente. Especialmente, si nos gusta hacerlo con frecuencia, como cada cuadro, por ejemplo. Afortunadamente, OpenGL (desde la versión 4.4) nos brinda una nueva técnica para combatir este problema. Se llama búfer mapeado persistente que proviene de la extensión ARB_buffer_storage.
Repasemos esta extensión. ¿Puede mejorar su código de renderizado?
Esta publicación es una introducción al tema Búferes mapeados persistentes, consulte
la Segunda Parte con BenchmarkResults
Introducción
Lo primero que me gustaría mencionar es que ya hay una cantidad decente de artículos que describen los búferes mapeados persistentes. He aprendido mucho, especialmente de los búferes mapeados [email protected] y ¡Maximizar el rendimiento de carga de VBO! -juegos java.
Esta publicación sirve como resumen y recapitulación de las técnicas modernas que se utilizan para manejar las actualizaciones del búfer. He usado esas técnicas en mi sistema de partículas
- espere un poco hasta la próxima publicación sobre las optimizaciones del renderizador.
Bien... pero hablemos de nuestro héroe principal en esta historia:la técnica de búfer mapeada persistente.
Apareció en ARB_buffer_storage y se convirtió en el núcleo de OpenGL 4.4. Le permite mapear el búfer una vez y mantener el puntero para siempre. No es necesario desasignarlo y soltar el puntero del controlador... toda la magia ocurre debajo.
El mapeo persistente también se incluye en el moderno conjunto de técnicas de OpenGL llamado "AZDO" - Aproximación a la sobrecarga del conductor cero . Como puede imaginar, al mapear el búfer solo una vez, reducimos significativamente la cantidad de llamadas a funciones pesadas de OpenGL y, lo que es más importante, luchamos contra los problemas de sincronización.
Una nota: este enfoque puede simplificar el código de renderizado y hacerlo más robusto, aún así, intente permanecer tanto como sea posible solo en el lado de la GPU. Cualquier transferencia de datos de CPU a GPU será mucho más lenta que la comunicación de GPU a GPU.
Mover datos
Pasemos ahora por el proceso de actualización de los datos en un búfer. Podemos hacerlo al menos de dos maneras diferentes:glBuffer*Data yglMapBuffer*.
Para ser precisos:queremos mover algunos datos de la memoria de la aplicación (CPU) a la GPU para que los datos puedan usarse en la representación. Estoy especialmente interesado en el caso en el que lo hacemos en cada cuadro, como en un sistema de partículas:calculas una nueva posición en la CPU, pero luego quieres renderizarla. Se necesita transferencia de memoria de CPU a GPU. Un ejemplo aún más complicado sería actualizar cuadros de video:carga datos de un archivo multimedia, lo decodifica y luego modifica los datos de textura que luego se muestran.
A menudo, este proceso se conoce como transmisión .
En otros términos:la CPU está escribiendo datos, la GPU está leyendo.
Aunque menciono 'mover ', la GPU puede leer directamente desde la memoria del sistema (usando GART). Por lo tanto, no hay necesidad de copiar datos de un búfer (en el lado de la CPU) a un búfer que está en el lado de la GPU. En ese enfoque, deberíamos pensar en "hacer que los datos sean visibles ' a GPU.
glBufferData/glBufferSubData
Esos dos procedimientos (¡disponibles desde OpenGL 1.5!) copiarán sus datos de entrada en la memoria anclada. Una vez hecho esto, se puede iniciar una transferencia DMA asíncrona y el procedimiento invocado regresa. Después de esa llamada, incluso puede eliminar su fragmento de memoria de entrada.
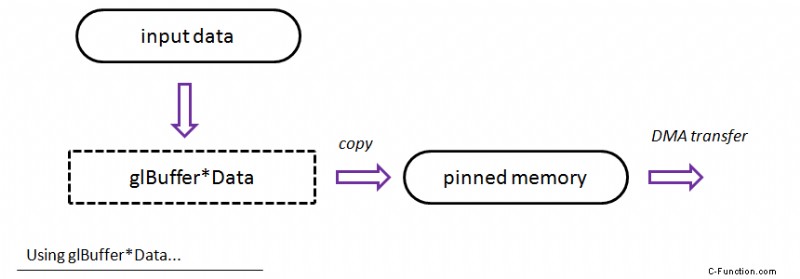
La imagen de arriba muestra un flujo "teórico" para este método:los datos se pasan a las funciones glBuffer*Data y luego, internamente, OpenGL realiza la transferencia DMA a la GPU...
Nota:glBufferData invalida y reasigna todo el búfer. UseglBufferSubData solo para actualizar los datos internos.
glMap*/glUnmap*
Con el enfoque de mapeo, simplemente obtiene un puntero a la memoria anclada (¡podría depender de la implementación real!). Puede copiar sus datos de entrada y luego llamar a glUnmap para decirle al controlador que ha terminado con la actualización. Por lo tanto, parece el enfoque con glBufferSubData, pero usted mismo se las arregla para copiar los datos. Además, obtiene más control sobre todo el proceso.
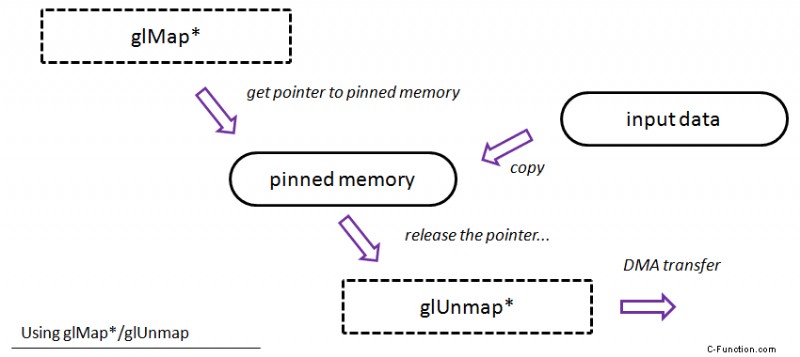
Un flujo "teórico" para este método:obtiene un puntero a (probablemente) la memoria anclada, luego puede copiar sus datos originales (o calcularlos), al final debe liberar el puntero a través del método glUnmapBuffer.
… Todos los métodos anteriores parecen bastante fáciles:solo paga por la transferencia de memoria. Podría ser así si no existiera tal asincronización...
Sincronización
Desafortunadamente, la vida no es tan fácil:debe recordar que la GPU y la CPU (e incluso el controlador) se ejecutan de forma asíncrona. Cuando envíe un drawcall, no se ejecutará de inmediato... se registrará en la cola de comandos, pero probablemente la GPU lo ejecutará mucho más tarde. Cuando actualizamos los datos de un búfer, es posible que se detenga fácilmente:la GPU esperará mientras modificamos los datos. Necesitamos ser más inteligentes al respecto.
Por ejemplo, cuando llama a glMapBuffer, el controlador puede crear una exclusión mutua para que la CPU y la GPU no modifiquen el búfer (que es un recurso compartido) al mismo tiempo. Si sucede a menudo, perderemos mucha potencia de GPU. La GPU puede bloquearse incluso en una situación en la que su búfer solo se registra para renderizarse y no leerse actualmente.
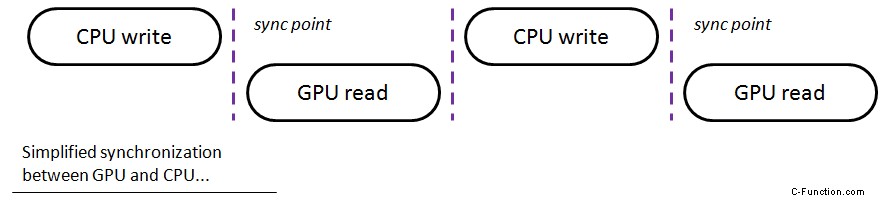
En la imagen de arriba, traté de mostrar una vista muy genérica y simplificada de cómo funcionan la GPU y la CPU cuando necesitan sincronizarse:esperar el uno al otro. En un escenario de la vida real, esos espacios pueden tener diferentes tamaños y puede haber múltiples puntos de sincronización en un cuadro. Cuanta menos espera, más rendimiento podemos obtener.
Por lo tanto, reducir los problemas de sincronización es otro incentivo para que todo suceda en la GPU.
Almacenamiento en búfer doble (múltiple)/huérfano
Una idea muy recomendable es utilizar el doble o incluso triple almacenamiento en búfer para resolver el problema con la sincronización:
- crear dos búferes
- actualizar el primero
- en el siguiente cuadro actualice el segundo
- intercambiar ID de búfer...
De esa forma, la GPU puede dibujar (leer) desde un búfer mientras usted actualiza el siguiente.
¿Cómo puedes hacer eso en OpenGL?
- utilice explícitamente varios búferes y use el algoritmo de operación por turnos para actualizarlos.
- use glBufferData con puntero NULL antes de cada actualización:
- todo el búfer se volverá a crear para que podamos almacenar nuestros datos de forma incompleta en un lugar nuevo
- la GPU usará el búfer antiguo; no será necesaria ninguna sincronización
- GPU probablemente se dará cuenta de que las siguientes asignaciones de búfer son similares, por lo que usará los mismos fragmentos de memoria. Recuerde que este enfoque no se sugirió en la versión anterior de OpenGL.
- usar glMapBufferRange con
GL_MAP_INVALIDATE_BUFFER_BIT- utilice adicionalmente el bit NO SINCRONIZADO y realice la sincronización por su cuenta.
- también hay un procedimiento llamado glInvalidateBufferData que hace el mismo trabajo
Almacenamiento en búfer triple
La GPU y la CPU se ejecutan de forma asíncrona... pero también hay otro factor:el controlador. Puede suceder (y en las implementaciones de controladores de escritorio sucede con bastante frecuencia) que el controlador también se ejecute de forma asíncrona. Para resolver este escenario de sincronización aún más complicado, podría considerar el almacenamiento en búfer triple:
- un búfer para cpu
- uno para el conductor
- uno para gpu
De esta manera, no debería haber paradas en la canalización, pero debe sacrificar un poco más de memoria para sus datos.
Más lectura en el blog @hacksoflife
- VBO de doble búfer
- Doble búfer, parte 2:por qué AGP podría ser su amigo
- Uno más sobre VBO -glBufferSubData
Asignación persistente
Ok, hemos cubierto técnicas comunes para la transmisión de datos, pero ahora, hablemos más detalladamente sobre la técnica de búferes mapeados persistentes.
Suposiciones:
GL_ARB_buffer_storagedebe estar disponible o OpenGL 4.4
Creación:
glGenBuffers(1, &vboID);
glBindBuffer(GL_ARRAY_BUFFER, vboID);
flags = GL_MAP_WRITE_BIT | GL_MAP_PERSISTENT_BIT | GL_MAP_COHERENT_BIT;
glBufferStorage(GL_ARRAY_BUFFER, MY_BUFFER_SIZE, 0, flags);
Mapeo (solo una vez después de la creación...):
flags = GL_MAP_WRITE_BIT | GL_MAP_PERSISTENT_BIT | GL_MAP_COHERENT_BIT;
myPointer = glMapBufferRange(GL_ARRAY_BUFFER, 0, MY_BUFFER_SIZE, flags);
Actualización:
// wait for the buffer
// just take your pointer (myPointer) and modyfy underlying data...
// lock the buffer
Como sugiere su nombre, le permite mapear el búfer una vez y mantener el puntero para siempre. Al mismo tiempo te queda el problema de sincronización
- es por eso que hay comentarios sobre esperar y bloquear el búfer en el código anterior.
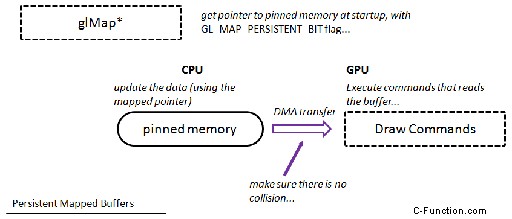
En el diagrama puede ver que, en primer lugar, necesitamos obtener un puntero a la memoria intermedia (pero lo hacemos solo una vez), luego podemos actualizar los datos (sin llamadas especiales a OpenGL). La única acción adicional que debemos realizar es la sincronización o asegurarnos de que la GPU no lea mientras escribimos al mismo tiempo. Todas las transferencias DMA necesarias son invocadas por el controlador.
El GL_MAP_COHERENT_BIT flag hace que los cambios en la memoria sean automáticamente visibles para la GPU. Sin esta bandera, habría establecido manualmente una barrera de memoria. Aunque parece que GL_MAP_COHERENT_BIT debería ser más lento que las barreras de memoria explícitas y personalizadas y la sincronización, mis primeras pruebas no mostraron ninguna diferencia significativa. Necesito pasar más tiempo en eso... ¿Quizás tienes más pensamientos sobre eso? Por cierto:incluso en la presentación original de AZDO, los autores mencionan usar GL_MAP_COHERENT_BIT así que esto no debería ser un problema serio :)
Sincronizando
// waiting for the buffer
GLenum waitReturn = GL_UNSIGNALED;
while (waitReturn != GL_ALREADY_SIGNALED && waitReturn != GL_CONDITION_SATISFIED)
{
waitReturn = glClientWaitSync(syncObj, GL_SYNC_FLUSH_COMMANDS_BIT, 1);
}
// lock the buffer:
glDeleteSync(syncObj);
syncObj = glFenceSync(GL_SYNC_GPU_COMMANDS_COMPLETE, 0);
Cuando escribimos en el búfer, colocamos un objeto de sincronización. Luego, en el siguiente cuadro, debemos esperar hasta que se señale este objeto de sincronización. En otras palabras, esperamos hasta que la GPU procese todos los comandos antes de configurar esa sincronización.
Almacenamiento en búfer triple
Pero podemos hacerlo mejor:al usar el almacenamiento en búfer triple podemos estar seguros de que la GPU y la CPU no tocarán los mismos datos en el búfer:
- asigne un búfer con 3x del tamaño original
- mapearlo para siempre
- ID de búfer =0
- actualizar/dibujar
- actualizar
bufferIDrango del búfer solamente - dibuja ese rango
bufferID = (bufferID+1)%3
- actualizar
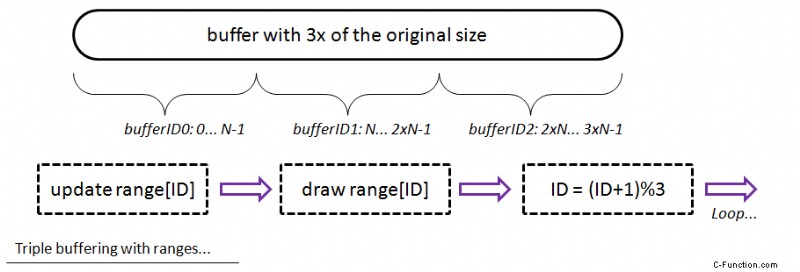
De esa manera, en el siguiente cuadro actualizará otra parte del búfer para que no haya conflicto.
Otra forma sería crear tres búferes separados y actualizarlos de manera similar.
Demostración

He bifurcado la aplicación de demostración del ejemplo de Ferran Sole y la he extendido un poco.
Aquí está el repositorio de github:fenbf/GLSamples
- número configurable de triángulos
- número configurable de búferes:simple/doble/triple
- sincronización opcional
- indicador de depuración opcional
- modo de referencia
- salida:
- número de fotogramas
- contador que se incrementa cada vez que esperamos el búfer
Los resultados completos se publicarán en la próxima publicación:ver aquí
Resumen
Esta fue una publicación larga, pero espero haber explicado todo de una manera decente. Pasamos por un enfoque estándar de actualizaciones de búfer (transmisión de búfer), vimos nuestro principal problema:la sincronización. Luego describí el uso de búfer mapeados de persistencia.
¿Debería usar búferes mapeados persistentes? Aquí está el breve resumen sobre eso:
Ventajas
- Fácil de usar
- El puntero obtenido se puede pasar en la aplicación
- En la mayoría de los casos, aumenta el rendimiento para actualizaciones de búfer muy frecuentes (cuando los datos provienen del lado de la CPU)
- reduce la sobrecarga del conductor
- minimiza las paradas de la GPU
- Recomendado para técnicas AZDO
Inconvenientes
- No lo use para búferes estáticos o búferes que no requieren actualizaciones desde el lado de la CPU.
- Mejor rendimiento con almacenamiento en búfer triple (puede ser un problema cuando tiene búferes grandes, porque necesita mucha memoria para asignar).
- Necesita hacer una sincronización explícita.
- En OpenGL 4.4, por lo que solo la GPU más reciente puede admitirlo.
En la próxima publicación compartiré mis resultados de la aplicación Demo. He comparado el enfoque de glMapBuffer con glBuffer*Data y el mapeo persistente.
Preguntas interesantes:
- ¿Esta extensión es mejor o peor que AMD_pinned_memory?
- ¿Qué pasa si olvidas sincronizar o lo haces de forma incorrecta? No obtuve ningún bloqueo de aplicaciones y apenas vi artefactos, pero ¿cuál es el resultado esperado de tal situación?
- ¿Qué sucede si olvida usar GL_MAP_COHERENT_BIT? ¿Hay tanta diferencia de rendimiento?
Referencias
- [PDF] OpenGL Insights, Capítulo 28 - Transferencias de búfer asíncronas por Ladislav Hrabcak y ArnaudMasserann, un capítulo gratuito de [OpenGLInsights].(http://openglinsights.com/)
- Mappedbuffers [email protected]
- ¡Maximizando el rendimiento de carga de [email protected] Forum
- Objeto de búfer @OpenGLWiki
- Búfer ObjectStreaming@OpenGL Wiki
- mapeo de búfer persistente:¿qué clase de magia es esta?@OpenGL Forum
Proyecto de código