El hash multiplicativo de Knuth se usa para calcular un valor hash en {0, 1, 2, ..., 2^p - 1} de un entero k.
Supongamos que p está entre 0 y 32, el algoritmo funciona así:
-
Calcule alfa como el entero más cercano a 2^32 (-1 + sqrt(5)) / 2. Obtenemos alfa =2 654 435 769.
-
Calcule k * alfa y reduzca el resultado módulo 2^32:
k * alfa =n0 * 2^32 + n1 con 0 <=n1 <2^32
-
Mantenga los p bits más altos de n1:
n1 =m1 * 2^(32-p) + m2 con 0 <=m2 <2^(32 - p)
Entonces, una implementación correcta del algoritmo multiplicativo de Knuth en C++ es:
std::uint32_t knuth(int x, int p) {
assert(p >= 0 && p <= 32);
const std::uint32_t knuth = 2654435769;
const std::uint32_t y = x;
return (y * knuth) >> (32 - p);
}
Olvidar cambiar el resultado por (32 - p) es un gran error. Como se perderían todas las buenas propiedades del hachís. Transformaría una secuencia par en una secuencia par, lo que sería muy malo ya que todas las ranuras impares permanecerían desocupadas. Eso es como tomar un buen vino y mezclarlo con Coca-Cola. Por cierto, la web está llena de personas que citan incorrectamente a Knuth y usan una multiplicación por 2 654 435 761 sin tomar los bits más altos. Acabo de abrir el Knuth y nunca dijo tal cosa. Parece que un tipo que decidió que era "inteligente" decidió tomar un número primo cercano al 2 654 435 769.
Tenga en cuenta que la mayoría de las implementaciones de tablas hash no permiten este tipo de firma en su interfaz, ya que solo permiten
uint32_t hash(int x);
y reducir hash(x) módulo 2^p para calcular el valor hash de x. Esas tablas hash no pueden aceptar el hash multiplicativo de Knuth. Esta podría ser la razón por la que tanta gente arruinó por completo el algoritmo al olvidarse de tomar los p bits más altos. Por lo tanto, no puede usar el hash multiplicativo de Knuth con std::unordered_map o std::unordered_set . Pero creo que esas tablas hash usan un número primo como tamaño, por lo que el hash multiplicativo de Knuth no es útil en este caso. Usando hash(x) = x sería una buena opción para esas mesas.
Fuente:"Introducción a los algoritmos, tercera edición", Cormen et al., 13.3.2 p:263
Fuente:"El arte de la programación informática, volumen 3, clasificación y búsqueda", D.E. Knuth, 6,4 p:516
Ok, lo busqué en TAOCP volumen 3 (2da edición), sección 6.4, página 516.
Esta implementación no es correcta, aunque como mencioné en los comentarios puede dar el resultado correcto de todos modos.
Una forma correcta (creo, siéntase libre de leer el capítulo relevante de TAOCP y verificar esto) es algo como esto:(importante:sí, debe cambiar el resultado a la derecha para reducirlo, no usar AND bit a bit. Sin embargo, eso no es la responsabilidad de esta función - la reducción de rango no es propiamente parte del hash en sí mismo)
uint32_t hash(uint32_t v)
{
return v * UINT32_C(2654435761);
// do not comment about the lack of right shift. I'm not ignoring it. read on.
}
Tenga en cuenta el uint32_t 's (a diferencia de int 's):se aseguran de que la multiplicación desborde el módulo 2^32, como se supone que debe hacer si elige 32 como tamaño de palabra. Tampoco hay desplazamiento a la derecha por k aquí, porque no hay razón para dar la responsabilidad de la reducción de rango a la función hash básica y, en realidad, es más útil obtener el resultado completo. La constante 2654435761 proviene de la pregunta, la constante sugerida real es 2654435769, pero esa es una pequeña diferencia que, hasta donde yo sé, no afecta la calidad del hash.
Otras implementaciones válidas desplazan el resultado hacia la derecha en cierta cantidad (aunque no el tamaño completo de la palabra, eso no tiene sentido y a C++ no le gusta), dependiendo de cuántos bits de hash necesite. O pueden usar otra constante (sujeto a ciertas condiciones) o un tamaño de palabra diferente. Reducir el módulo hash algo no una implementación válida, pero un error común, probablemente sea una forma estándar de facto de reducir el rango en un hash. Los bits inferiores de un hash multiplicativo son los bits de peor calidad (dependen de menos de la entrada), solo desea usarlos si realmente necesita más bits, mientras que al reducir el módulo de hash, una potencia de dos devolvería solo las peores partes . De hecho, eso es equivalente a tirar la mayoría de los bits de entrada también. Reducir el módulo que no es potencia de dos no es tan malo, ya que mezcla los bits más altos, pero no es así como se definió el hash multiplicativo.
Entonces, para ser claros, sí, hay un desplazamiento a la derecha, pero eso es reducción de rango no hashing y solo puede ser responsabilidad de la tabla hash, ya que depende de su tamaño interno.
El tipo no debe estar firmado, de lo contrario, el desbordamiento no está especificado (por lo tanto, posiblemente sea incorrecto, no solo en arquitecturas que no son de complemento a 2, sino también en compiladores demasiado inteligentes) y el desplazamiento a la derecha opcional sería un desplazamiento firmado (incorrecto).
En la página que menciono en la parte superior, hay esta fórmula:
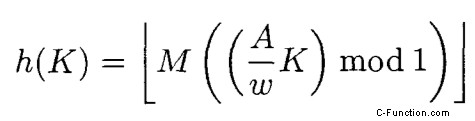
Aquí tenemos A =2654435761 (o 2654435769), w =2 32 y M =2 32 . Calcular AK/w da un resultado de punto fijo con el formato Q32.32, el paso mod 1 toma solo los 32 bits de fracción. Pero eso es lo mismo que hacer una multiplicación modular y luego decir que el resultado son los bits de fracción. Por supuesto, cuando se multiplica por M, todos los bits de fracción se convierten en bits enteros debido a cómo se eligió M, por lo que se simplifica a una simple multiplicación modular antigua. Cuando M es una potencia menor de dos, eso simplemente desplaza el resultado a la derecha, como se mencionó.
Puede que llegue tarde, pero aquí hay una implementación de Java del método de Knuth:
Para una tabla hash de tamaño N:
public long hash(int key) {
long l = 2654435769L;
return (key * l >> 32) % N ;
}