Lo siguiente se basa en mi experiencia como investigador de la visión. A partir de su pregunta, parece estar interesado en posibles algoritmos y métodos, en lugar de solo en una pieza de código funcional. Primero doy un script de Python rápido y sucio para sus imágenes de muestra y se muestran algunos resultados para demostrar que posiblemente podría resolver su problema. Después de sacarlos del camino, trato de responder a sus preguntas sobre algoritmos de detección robustos.
Resultados rápidos
Algunas imágenes de muestra (todas las imágenes excepto la suya se descargan de flickr.com y tienen licencia CC) con los círculos detectados (sin cambiar/sintonizar ningún parámetro, se usa exactamente el siguiente código para extraer los círculos en todas las imágenes):
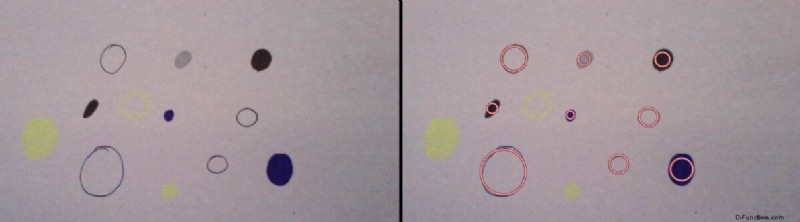


Código (basado en MSER Blob Detector)
Y aquí está el código:
import cv2
import math
import numpy as np
d_red = cv2.cv.RGB(150, 55, 65)
l_red = cv2.cv.RGB(250, 200, 200)
orig = cv2.imread("c.jpg")
img = orig.copy()
img2 = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
detector = cv2.FeatureDetector_create('MSER')
fs = detector.detect(img2)
fs.sort(key = lambda x: -x.size)
def supress(x):
for f in fs:
distx = f.pt[0] - x.pt[0]
disty = f.pt[1] - x.pt[1]
dist = math.sqrt(distx*distx + disty*disty)
if (f.size > x.size) and (dist<f.size/2):
return True
sfs = [x for x in fs if not supress(x)]
for f in sfs:
cv2.circle(img, (int(f.pt[0]), int(f.pt[1])), int(f.size/2), d_red, 2, cv2.CV_AA)
cv2.circle(img, (int(f.pt[0]), int(f.pt[1])), int(f.size/2), l_red, 1, cv2.CV_AA)
h, w = orig.shape[:2]
vis = np.zeros((h, w*2+5), np.uint8)
vis = cv2.cvtColor(vis, cv2.COLOR_GRAY2BGR)
vis[:h, :w] = orig
vis[:h, w+5:w*2+5] = img
cv2.imshow("image", vis)
cv2.imwrite("c_o.jpg", vis)
cv2.waitKey()
cv2.destroyAllWindows()
Como puede ver, se basa en el detector de manchas MSER. El código no preprocesa la imagen aparte del simple mapeo en escala de grises. Por lo tanto, se espera que se pierdan esas manchas amarillas tenues en sus imágenes.
Teoría
En resumen:no nos dice lo que sabe sobre el problema, aparte de dar solo dos imágenes de muestra sin una descripción de ellas. Aquí explico por qué en mi humilde opinión es importante tener más información sobre el problema antes de preguntar cuáles son los métodos eficientes para atacar el problema.
Volviendo a la pregunta principal:¿cuál es el mejor método para este problema? Veamos esto como un problema de búsqueda. Para simplificar la discusión supongamos que estamos buscando círculos con un tamaño/radio determinado. Así, el problema se reduce a encontrar los centros. Cada píxel es un centro candidato, por lo tanto, el espacio de búsqueda contiene todos los píxeles.
P = {p1, ..., pn}
P: search space
p1...pn: pixels
Para resolver este problema de búsqueda se deben definir otras dos funciones:
E(P) : enumerates the search space
V(p) : checks whether the item/pixel has the desirable properties, the items passing the check are added to the output list
Asumiendo que la complejidad del algoritmo no importa, se puede usar la búsqueda exhaustiva o de fuerza bruta en la que E toma cada píxel y lo pasa a V. En las aplicaciones en tiempo real, es importante reducir el espacio de búsqueda y optimizar la eficiencia computacional de V. .
Nos estamos acercando a la pregunta principal. Cómo podríamos definir V, para ser más precisos qué propiedades de los candidatos deberían ser medidas y cómo deberían resolver el problema de la dicotomía de dividirlos en deseables e indeseables. El enfoque más común es encontrar algunas propiedades que puedan usarse para definir reglas de decisión simples basadas en la medición de las propiedades. Esto es lo que estás haciendo por ensayo y error. Estás programando un clasificador aprendiendo de ejemplos positivos y negativos. Esto se debe a que los métodos que está utilizando no tienen idea de lo que quiere hacer. Tiene que ajustar/sintonizar los parámetros de la regla de decisión y/o preprocesar los datos de manera que se reduzca la variación en las propiedades (de los candidatos deseables) utilizadas por el método para el problema de dicotomía. Podría usar un algoritmo de aprendizaje automático para encontrar los valores de parámetros óptimos para un conjunto dado de ejemplos. Hay una gran cantidad de algoritmos de aprendizaje, desde árboles de decisión hasta programación genética, que puede usar para este problema. También podría usar un algoritmo de aprendizaje para encontrar los valores de parámetros óptimos para varios algoritmos de detección de círculos y ver cuál ofrece una mayor precisión. Esto elimina la carga principal del algoritmo de aprendizaje, solo necesita recopilar imágenes de muestra.
El otro enfoque para mejorar la solidez que a menudo se pasa por alto es utilizar información adicional fácilmente disponible. Si conoce el color de los círculos con prácticamente ningún esfuerzo adicional, podría mejorar significativamente la precisión del detector. Si conocía la posición de los círculos en el plano y deseaba detectar los círculos en la imagen, debe recordar que la transformación entre estos dos conjuntos de posiciones se describe mediante una homografía 2D. Y la homografía se puede estimar usando solo cuatro puntos. Entonces podría mejorar la robustez para tener un método sólido como una roca. El valor del conocimiento específico del dominio a menudo se subestima. Míralo de esta manera, en el primer enfoque tratamos de aproximar algunas reglas de decisión basadas en un número limitado de muestras. En el segundo enfoque, conocemos las reglas de decisión y solo necesitamos encontrar una manera de utilizarlas de manera efectiva en un algoritmo.
Resumen
Para resumir, hay dos enfoques para mejorar la precisión/robustez de la solución:
- Basado en herramientas :encontrar un algoritmo más fácil de usar/con menos parámetros/ajustar el algoritmo/automatizar este proceso mediante el uso de algoritmos de aprendizaje automático
- Basado en información :¿está utilizando toda la información fácilmente disponible? En la pregunta no menciona lo que sabe sobre el problema.
Para estas dos imágenes que ha compartido, usaría un detector de manchas, no el método HT. Para la resta del fondo, sugeriría intentar estimar el color del fondo, ya que en las dos imágenes no varía, mientras que el color de los círculos varía. Y la mayor parte del área está vacía.
Este es un gran problema de modelado. Tengo las siguientes recomendaciones/ideas:
- Divida la imagen a RGB y luego procese.
- preprocesamiento.
- Búsqueda de parámetros dinámicos.
- Añadir restricciones.
- Asegúrese de lo que está tratando de detectar.
Más detalladamente:
1:como se señaló en otras respuestas, la conversión directa a escala de grises descarta demasiada información:se perderán los círculos con un brillo similar al del fondo. Es mucho mejor considerar los canales de color de forma aislada o en un espacio de color diferente. Hay prácticamente dos formas de hacerlo:realizar HoughCircles en cada canal preprocesado de forma aislada, luego combine los resultados, o procese los canales, luego combínelos, luego opere HoughCircles . En mi intento a continuación, probé el segundo método, dividiendo en canales RGB, procesando y luego combinando. Tenga cuidado con la saturación excesiva de la imagen al combinar, yo uso cv.And para evitar este problema (en esta etapa, mis círculos son siempre anillos/discos negros sobre fondo blanco).
2:El preprocesamiento es bastante complicado y, a menudo, es mejor jugar con algo. He hecho uso de AdaptiveThreshold que es un método de convolución realmente poderoso que puede mejorar los bordes de una imagen mediante el umbral de píxeles en función de su promedio local (procesos similares también ocurren en la vía temprana del sistema visual de los mamíferos). Esto también es útil ya que reduce algo de ruido. He usado dilate/erode con un solo pase. Y he mantenido los otros parámetros como los tenías. Parece que usa Canny antes de HoughCircles ayuda mucho a encontrar 'círculos llenos', por lo que probablemente sea mejor mantenerlo. Este preprocesamiento es bastante pesado y puede generar falsos positivos con algo más de 'círculos llenos', pero en nuestro caso, ¿esto es quizás deseable?
3:Como ha observado, el parámetro param2 de HoughCircles (su parámetro LOW ) debe ajustarse para cada imagen para obtener una solución óptima, de hecho, de los documentos:
El problema es que el punto óptimo va a ser diferente para cada imagen. Creo que el mejor enfoque aquí es establecer una condición y hacer una búsqueda a través de diferentes param2 valores hasta que se cumpla esta condición. Tus imágenes muestran círculos que no se superponen y cuando param2 es demasiado bajo, por lo general obtenemos un montón de círculos superpuestos. Así que sugiero buscar el:
Así que seguimos llamando a HoughCircles con diferentes valores de param2 hasta que esto se cumpla. Hago esto en mi ejemplo a continuación, simplemente incrementando param2 hasta que alcanza el supuesto umbral. Sería mucho más rápido (y bastante fácil de hacer) si realiza una búsqueda binaria para encontrar cuándo se cumple esto, pero debe tener cuidado con el manejo de excepciones ya que opencv a menudo arroja errores para valores inocentes de param2 (al menos en mi instalación). Una condición diferente con la que sería muy útil comparar sería el número de círculos.
4:¿Hay más restricciones que podamos agregar al modelo? Cuantas más cosas podamos decirle a nuestro modelo, más fácil será la tarea que podemos hacer para detectar círculos. Por ejemplo, sabemos:
- El número de círculos. - incluso un límite superior o inferior es útil.
- Posibles colores de los círculos, o del fondo, o de 'no círculos'.
- Sus tamaños.
- Dónde pueden estar en una imagen.
5:¡Algunas de las manchas en sus imágenes solo podrían llamarse círculos! Considere las dos 'manchas no circulares' en su segunda imagen, mi código no puede encontrarlas (¡bien!), pero... si las 'photoshop' para que sean más circulares, mi código puede encontrarlas... Tal vez si desea detectar cosas que no son círculos, un enfoque diferente como Tim Lukins puede ser mejor.
Problemas
Haciendo mucho preprocesamiento AdaptiveThresholding y `Canny', puede haber mucha distorsión en las características de una imagen, lo que puede dar lugar a una detección de círculos falsos o a un informe de radio incorrecto. Por ejemplo, un disco sólido grande después del procesamiento puede aparecer como un anillo, por lo que HughesCircles puede encontrar el anillo interior. Además, incluso los documentos señalan que:
Si necesita una detección de radios más precisa, sugiero el siguiente enfoque (no implementado):
- En la imagen original, trazado de rayos desde el centro informado del círculo, en una cruz en expansión (4 rayos:arriba/abajo/izquierda/derecha)
- Haga esto por separado en cada canal RGB
- Combine esta información para cada canal para cada rayo de manera sensata (es decir, invierta, desplace, escale, etc. según sea necesario)
- tome el promedio de los primeros píxeles de cada rayo, utilícelo para detectar dónde se produce una desviación significativa en el rayo.
- Estos 4 puntos son estimaciones de puntos en la circunferencia.
- Utilice estas cuatro estimaciones para determinar un radio más preciso y una posición central (!).
- Esto podría generalizarse usando un anillo en expansión en lugar de cuatro rayos.
Resultados
El código al final funciona bastante bien la mayor parte del tiempo, estos ejemplos se realizaron con el código que se muestra:
Detecta todos los círculos en tu primera imagen:
Cómo se ve la imagen preprocesada antes de aplicar el filtro astuto (diferentes círculos de color son muy visibles):
Detecta todos menos dos (blobs) en la segunda imagen:
Segunda imagen alterada (las gotas se afinan en círculos y el óvalo grande se vuelve más circular, lo que mejora la detección), todo detectado:
Lo hace bastante bien en la detección de centros en esta pintura de Kandinsky (no puedo encontrar anillos concéntricos debido a la condición límite). 
Código:
import cv
import numpy as np
output = cv.LoadImage('case1.jpg')
orig = cv.LoadImage('case1.jpg')
# create tmp images
rrr=cv.CreateImage((orig.width,orig.height), cv.IPL_DEPTH_8U, 1)
ggg=cv.CreateImage((orig.width,orig.height), cv.IPL_DEPTH_8U, 1)
bbb=cv.CreateImage((orig.width,orig.height), cv.IPL_DEPTH_8U, 1)
processed = cv.CreateImage((orig.width,orig.height), cv.IPL_DEPTH_8U, 1)
storage = cv.CreateMat(orig.width, 1, cv.CV_32FC3)
def channel_processing(channel):
pass
cv.AdaptiveThreshold(channel, channel, 255, adaptive_method=cv.CV_ADAPTIVE_THRESH_MEAN_C, thresholdType=cv.CV_THRESH_BINARY, blockSize=55, param1=7)
#mop up the dirt
cv.Dilate(channel, channel, None, 1)
cv.Erode(channel, channel, None, 1)
def inter_centre_distance(x1,y1,x2,y2):
return ((x1-x2)**2 + (y1-y2)**2)**0.5
def colliding_circles(circles):
for index1, circle1 in enumerate(circles):
for circle2 in circles[index1+1:]:
x1, y1, Radius1 = circle1[0]
x2, y2, Radius2 = circle2[0]
#collision or containment:
if inter_centre_distance(x1,y1,x2,y2) < Radius1 + Radius2:
return True
def find_circles(processed, storage, LOW):
try:
cv.HoughCircles(processed, storage, cv.CV_HOUGH_GRADIENT, 2, 32.0, 30, LOW)#, 0, 100) great to add circle constraint sizes.
except:
LOW += 1
print 'try'
find_circles(processed, storage, LOW)
circles = np.asarray(storage)
print 'number of circles:', len(circles)
if colliding_circles(circles):
LOW += 1
storage = find_circles(processed, storage, LOW)
print 'c', LOW
return storage
def draw_circles(storage, output):
circles = np.asarray(storage)
print len(circles), 'circles found'
for circle in circles:
Radius, x, y = int(circle[0][2]), int(circle[0][0]), int(circle[0][1])
cv.Circle(output, (x, y), 1, cv.CV_RGB(0, 255, 0), -1, 8, 0)
cv.Circle(output, (x, y), Radius, cv.CV_RGB(255, 0, 0), 3, 8, 0)
#split image into RGB components
cv.Split(orig,rrr,ggg,bbb,None)
#process each component
channel_processing(rrr)
channel_processing(ggg)
channel_processing(bbb)
#combine images using logical 'And' to avoid saturation
cv.And(rrr, ggg, rrr)
cv.And(rrr, bbb, processed)
cv.ShowImage('before canny', processed)
# cv.SaveImage('case3_processed.jpg',processed)
#use canny, as HoughCircles seems to prefer ring like circles to filled ones.
cv.Canny(processed, processed, 5, 70, 3)
#smooth to reduce noise a bit more
cv.Smooth(processed, processed, cv.CV_GAUSSIAN, 7, 7)
cv.ShowImage('processed', processed)
#find circles, with parameter search
storage = find_circles(processed, storage, 100)
draw_circles(storage, output)
# show images
cv.ShowImage("original with circles", output)
cv.SaveImage('case1.jpg',output)
cv.WaitKey(0)
Ah, sí... las antiguas invariantes de color/tamaño para el problema de los círculos (también conocida como la transformada de Hough es demasiado específica y no robusta)...
En el pasado, confiaba mucho más en las funciones de análisis estructural y de formas de OpenCV. Puede obtener una muy buena idea de la carpeta "muestras" de lo que es posible, particularmente fitellipse.py y squares.py .
Para su aclaración, presento una versión híbrida de estos ejemplos y basada en su fuente original. Los contornos detectados están en verde y las elipses ajustadas en rojo.

Todavía no ha llegado:
- Los pasos de preprocesamiento necesitan un poco de ajuste para detectar los círculos más tenues.
- Puede probar más el contorno para determinar si es un círculo o no...
¡Buena suerte!
import cv
import numpy as np
# grab image
orig = cv.LoadImage('circles3.jpg')
# create tmp images
grey_scale = cv.CreateImage(cv.GetSize(orig), 8, 1)
processed = cv.CreateImage(cv.GetSize(orig), 8, 1)
cv.Smooth(orig, orig, cv.CV_GAUSSIAN, 3, 3)
cv.CvtColor(orig, grey_scale, cv.CV_RGB2GRAY)
# do some processing on the grey scale image
cv.Erode(grey_scale, processed, None, 10)
cv.Dilate(processed, processed, None, 10)
cv.Canny(processed, processed, 5, 70, 3)
cv.Smooth(processed, processed, cv.CV_GAUSSIAN, 15, 15)
#storage = cv.CreateMat(orig.width, 1, cv.CV_32FC3)
storage = cv.CreateMemStorage(0)
contours = cv.FindContours(processed, storage, cv.CV_RETR_EXTERNAL)
# N.B. 'processed' image is modified by this!
#contours = cv.ApproxPoly (contours, storage, cv.CV_POLY_APPROX_DP, 3, 1)
# If you wanted to reduce the number of points...
cv.DrawContours (orig, contours, cv.RGB(0,255,0), cv.RGB(255,0,0), 2, 3, cv.CV_AA, (0, 0))
def contour_iterator(contour):
while contour:
yield contour
contour = contour.h_next()
for c in contour_iterator(contours):
# Number of points must be more than or equal to 6 for cv.FitEllipse2
if len(c) >= 6:
# Copy the contour into an array of (x,y)s
PointArray2D32f = cv.CreateMat(1, len(c), cv.CV_32FC2)
for (i, (x, y)) in enumerate(c):
PointArray2D32f[0, i] = (x, y)
# Fits ellipse to current contour.
(center, size, angle) = cv.FitEllipse2(PointArray2D32f)
# Convert ellipse data from float to integer representation.
center = (cv.Round(center[0]), cv.Round(center[1]))
size = (cv.Round(size[0] * 0.5), cv.Round(size[1] * 0.5))
# Draw ellipse
cv.Ellipse(orig, center, size, angle, 0, 360, cv.RGB(255,0,0), 2,cv.CV_AA, 0)
# show images
cv.ShowImage("image - press 'q' to quit", orig)
#cv.ShowImage("post-process", processed)
cv.WaitKey(-1)
EDITAR:
Solo una actualización para decir que creo que un tema importante para todas estas respuestas es que hay una serie de suposiciones y restricciones adicionales que se pueden aplicar a lo que busca reconocer como circular . Mi propia respuesta no pretende esto, ni en el preprocesamiento de bajo nivel ni en el ajuste geométrico de alto nivel. El hecho de que muchos de los círculos no sean realmente tan redondos debido a la forma en que están dibujados o a las transformaciones no afines/proyectivas de la imagen, y con las otras propiedades en la forma en que se representan/capturan (color, ruido, iluminación, grosor del borde):todos dan como resultado cualquier número de posibles círculos candidatos dentro de una sola imagen.
Hay técnicas mucho más sofisticadas. Pero te costarán. Personalmente, me gusta la idea de @fraxel de usar el umbral adaptativo. Eso es rápido, confiable y razonablemente robusto. Luego puede probar más los contornos finales (por ejemplo, usar momentos Hu) o accesorios con una prueba de relación simple del eje de la elipse, por ejemplo. si ((mín(tamaño)/máx(tamaño))>0.7).
Como siempre con Computer Vision, existe la tensión entre pragmatismo, principio y parsomonía. Como me gusta decirle a la gente que piensa que CV es fácil, no lo es; de hecho, es un problema completo de IA. Lo mejor que puede esperar a menudo fuera de esto es algo que funciona la mayor parte del tiempo.