Der einfachste Weg, nicht-alphanumerische Zeichen aus einer Zeichenfolge zu entfernen, ist die Verwendung von regex:
if (string.IsNullOrEmpty(s))
return s;
return Regex.Replace(s, "[^a-zA-Z0-9]", "");
Code language: C# (cs)Hinweis:Übergeben Sie keine Null, sonst erhalten Sie eine Ausnahme.
Regex ist der einfachste Ansatz zur Lösung dieses Problems, aber auch der langsamste. Wenn Sie sich Sorgen um die Leistung machen, sehen Sie sich den Leistungsabschnitt unten an.
In diesem Beispiel werden nur alphanumerische ASCII-Zeichen beibehalten. Wenn Sie mit anderen Alphabeten arbeiten, lesen Sie den Abschnitt unten zum Festlegen von Nicht-ASCII-Zeichen.
Verwenden Sie für eine bessere Leistung eine Schleife
Das Durchlaufen des Strings und die Übernahme der gewünschten Zeichen ist 7,5-mal schneller als Regex (und 3-mal schneller als die Verwendung von Linq).
if (string.IsNullOrEmpty(s))
return s;
StringBuilder sb = new StringBuilder();
foreach(var c in s)
{
if ((c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') || (c >= '0' && c <= '9'))
sb.Append(c);
}
return sb.ToString();
Code language: C# (cs)Kümmern Sie sich nicht darum, kompilierte Regex zu verwenden
Die Verwendung von kompiliertem Regex hilft in diesem Szenario nicht viel bei der Leistung. Im besten Fall geht es etwas schneller. Im schlimmsten Fall ist es dasselbe, als würde man keine kompilierte Regex verwenden. Es ist einfacher, die statischen Regex-Methoden (wie Regex.Replace()) zu verwenden, anstatt sicherzustellen, dass das kompilierte Regex-Objekt überall verfügbar ist. Mit anderen Worten, verwenden Sie einfach die statischen Regex-Methoden anstelle der kompilierten Regex.
Hier ist ein Beispiel für die Verwendung von kompiliertem Regex:
private static readonly Regex regex = new Regex("[^a-zA-Z0-9]", RegexOptions.Compiled);
public static string RemoveNonAlphanumericChars(string s)
{
if (string.IsNullOrEmpty(s))
return s;
return regex.Replace(s, "");
}
Code language: C# (cs)Verwenden Sie char.IsLetterOrDigit(), wenn Sie alle alphanumerischen Unicode-Zeichen möchten
Beachten Sie, dass char.IsLetterOrDigit() für alle alphanumerischen Unicode-Zeichen „true“ zurückgibt. Wenn Sie Zeichen entfernen, liegt das normalerweise daran, dass Sie genau wissen, welche Zeichen Sie nehmen möchten. Die Verwendung von char.IsLetterOrDigit() sollte nur verwendet werden, wenn Sie ALLE alphanumerischen Unicode-Zeichen akzeptieren und alles andere entfernen möchten. Das dürfte selten sein.
Es ist besser, genau anzugeben, welche Zeichen Sie behalten möchten (und wenn Sie Regex verwenden, wenden Sie dann den ^-Operator an, um alles außer diesen Zeichen zu entfernen).
Benchmark-Ergebnisse
Ich habe vier Ansätze zum Entfernen nicht-alphanumerischer Zeichen aus einer Zeichenfolge verglichen. Ich habe jeder Methode einen String mit 100 Zeichen übergeben. Das folgende Diagramm zeigt die Ergebnisse:
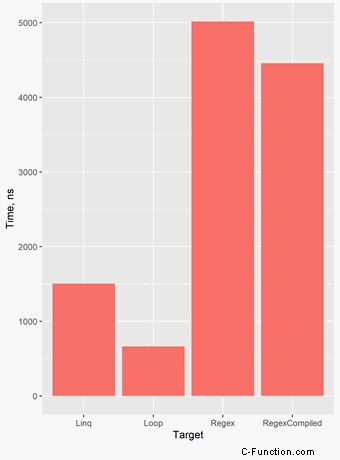
Hier sind alle Benchmark-Statistiken:
| Method | Mean | StdDev | Min | Max |
|-------------- |-----------:|----------:|-----------:|-----------:|
| Regex | 5,016.4 ns | 139.89 ns | 4,749.4 ns | 5,325.5 ns |
| RegexCompiled | 4,457.9 ns | 301.40 ns | 3,930.5 ns | 5,360.4 ns |
| Linq | 1,506.9 ns | 76.75 ns | 1,393.0 ns | 1,722.3 ns |
| Loop | 663.7 ns | 31.15 ns | 599.6 ns | 742.3 ns |Code language: plaintext (plaintext)Nicht-ASCII-Zeichen in Regex angeben
Wie wäre es, wenn Sie mit alphanumerischen Nicht-ASCII-Zeichen umgehen müssen, z. B. mit den folgenden griechischen Zeichen:
ΕλληνικάCode language: plaintext (plaintext)Wenn Sie es mit einem Nicht-ASCII-Alphabet wie Griechisch zu tun haben, können Sie den Unicode-Bereich nachschlagen und die Codepunkte oder Zeichen verwenden.
Hinweis:Denken Sie daran, dass es hier um das Entfernen von Zeichen geht. Bei Regex geben Sie also an, welche Zeichen Sie haben möchten, und verwenden dann den ^-Operator, um alles außer diesen Zeichen abzugleichen.
Unicode-Codepunkte verwenden
Hier ist ein Beispiel für die Angabe des griechischen Unicode-Codepunktbereichs:
Regex.Replace(s, "[^\u0370-\u03FF]", "");
Code language: C# (cs)Unicode benannten Block verwenden
Zur besseren Lesbarkeit können Sie einen Unicode-Namensblock verwenden, z. B. „IsGreek“. Um anzugeben, dass Sie einen benannten Block verwenden möchten, verwenden Sie \p{} wie folgt:
Regex.Replace(s, @"[^\p{IsGreek}]", "");
Code language: C# (cs)Geben Sie genau an, welche Unicode-Zeichen Sie wollen
Sie können genau angeben, welche Unicode-Zeichen Sie möchten (einschließlich einer Reihe davon):
Regex.Replace(s, "[^α-ωάΕ]", "");
Code language: C# (cs)Dies ist einfacher zu lesen als die Verwendung von Codepunkten.