
Wie viel kostet std::string_view schneller als Standard std::string Operationen?
Schauen Sie sich ein paar Beispiele an, in denen ich std::string_view vergleiche gegenstd::string .
Einführung
Ich habe nach einigen Beispielen für string_view gesucht , und nach einer Weile wurde ich neugierig auf den möglichen Leistungsgewinn.
string_view ist konzeptionell nur eine Ansicht des Strings:normalerweise implementiert als [ptr, length] . Wenn ein string_view erstellt ist, müssen die Daten nicht kopiert werden (anders als beim Erstellen einer Kopie von astring). Außerdem string_view kleiner als std::string ist -in Bezug auf die Größe auf dem Stack/Haufen.
Zum Beispiel, wenn wir uns eine mögliche (Pseudo-)Implementierung ansehen:
string_view {
size_t _len;
const CharT* _str;
}
Je nach Architektur beträgt die Gesamtgröße 8 oder 16 Byte.
Aufgrund kleiner String-Optimierungen std::string ist normalerweise 24 oder 32 Bytes, also doppelt oder dreifach so groß wie string_view . In dieser Form kann eine solche Zeichenfolge zwischen 15 (GCC, MSVC) und 22 Zeichen (Clang) enthalten, ohne dass Speicher auf dem Heap zugewiesen werden muss. Natürlich benötigen größere Zeichenfolgen mehr Speicher, aber 24/32 Bytes ist die minimale Größe von std::string .
Weitere Details zu SSO finden Sie in diesem exzellenten Beitrag Exploringstd::string.
Oder hier:SSO-23 (in einem Kommentar vorgeschlagen)
Offensichtlich String-Views zurückgeben, String-Views erstellen, mit substr ist definitiv viel schneller als tiefe Kopien von std::string . Die anfänglichen Leistungstests zeigten jedoch, dass std::string ist normalerweise hochoptimiert und manchmal string_view gewinnt nicht so viel.
Die Serie
Dieser Artikel ist Teil meiner Serie über C++17 Library Utilities. Hier ist die Liste der anderen Themen, die ich behandeln werde:
- Refaktorisierung mit
std::optional - Mit
std::optional - Fehlerbehandlung und
std::optional - Über
std::variant - Über
std::any - Bestandsbau für
std::optional,std::variantundstd::any std::string_viewLeistung (dieser Beitrag )- C++17-Stringsucher und Konvertierungsprogramme
- Arbeiten mit
std::filesystem - Noch etwas?
- Zeigen Sie mir Ihren Code:
std::optional - Ergebnisse:Zeig mir deinen Kern:
std::optional - Menu-Klasse – Beispiel für moderne C++17-STL-Funktionen
- Zeigen Sie mir Ihren Code:

Ressourcen zu C++17 STL:
- C++17 im Detail von Bartek!
- C++17 – Der vollständige Leitfaden von NicolaiJosuttis
- C++-Grundlagen einschließlich C++17 von Kate Gregory
- Praktische C++14- und C++17-Funktionen – von Giovanni Dicanio
- C++17-STL-Kochbuch von Jacek Galowicz
string_view Operationen
string_view ist sehr ähnlich zu std::string modelliert . Die Ansicht ist jedoch nicht besitzend, sodass keine Operation, die die Daten ändert, in die API gelangen kann. Hier ist eine kurze Liste von Methoden, die Sie mit diesem neuen Typ verwenden können:
operator[]atfrontbackdatasize/lengthmax_sizeemptyremove_prefixremove_suffixswapcopy(nichtconstexpr)substr- KomplexitätO(1)und nichtO(n)wie instd::stringcomparefindrfindfind_first_offind_last_offind_first_not_offind_last_not_of- Operatoren für Lexikographie vergleichen:
==, !=, <=, >=, <, > operator <<
Ein wichtiger Hinweis ist, dass alle oben genannten Methoden (mit Ausnahme von copy und operator << ) sind ebenfalls constexpr ! Mit dieser Funktion können Sie jetzt möglicherweise mit Zeichenfolgen in konstanten Ausdrücken arbeiten.
Außerdem werden wir für C++20 mindestens zwei neue Methoden bekommen:
starts_withends_with
Das sind beide für std::string_view implementiert und std::string . Ab sofort (Juli 2018) unterstützt Clang 6.0 diese Funktionen. Sie können also damit experimentieren.
Ein Basistest - substr
substr bietet wahrscheinlich den besten Vorteil gegenüber der Standardzeichenfolge substr . Es hat die Komplexität von O(1) und nicht O(n) wie bei normalen Strings.
Ich habe mit Quick C++Benchmark einen einfachen Test erstellt und die folgenden Ergebnisse erhalten:
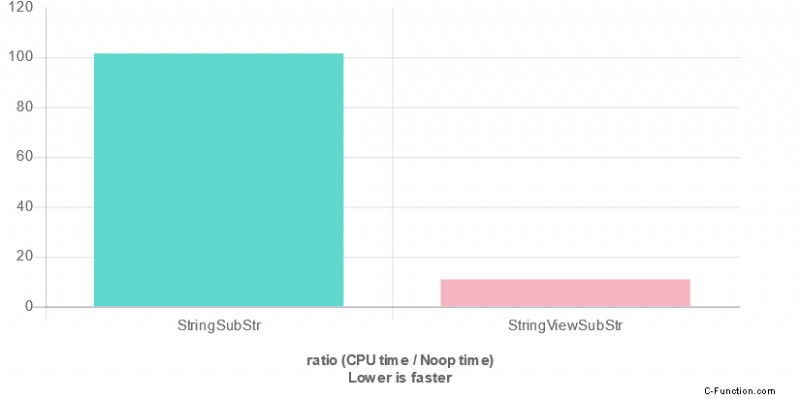
Verwenden von Clang 6.0.0, -O3, libc++
Der Code:
static void StringSubStr(benchmark::State& state) {
std::string s = "Hello Super Extra Programming World";
for (auto _ : state) {
auto oneStr = s.substr(0, 5);
auto twoStr = s.substr(6, 5);
auto threeStr = s.substr(12, 5);
auto fourStr = s.substr(18, 11);
auto fiveStr = s.substr(30, 5);
// Make sure the variable is not optimized away by compiler
benchmark::DoNotOptimize(oneStr);
benchmark::DoNotOptimize(twoStr);
benchmark::DoNotOptimize(threeStr);
benchmark::DoNotOptimize(fourStr);
benchmark::DoNotOptimize(fiveStr);
}
}
Und für string_view :
static void StringViewSubStr(benchmark::State& state) {
// Code before the loop is not measured
std::string s = "Hello Super Extra Programming World";
for (auto _ : state) {
std::string_view sv = s;
auto oneSv = sv.substr(0, 5);
auto twoSv = sv.substr(6, 5);
auto threeSv = sv.substr(12, 5);
auto fourSv = sv.substr(18, 11);
auto fiveSv = sv.substr(30, 5);
benchmark::DoNotOptimize(oneSv);
benchmark::DoNotOptimize(twoSv);
benchmark::DoNotOptimize(threeSv);
benchmark::DoNotOptimize(fourSv);
benchmark::DoNotOptimize(fiveSv);
}
}
Hier ist das vollständige Experiment:@Quick C++Bench
Für diesen Test haben wir eine 10-fache Beschleunigung !
Können wir in anderen Fällen ähnliche Ergebnisse erzielen?
String-Split
Nach den grundlegenden Tests können wir einen weiteren Schritt machen und versuchen, einen komplizierteren Algorithmus zu komponieren:Nehmen wir das String-Splitting.
Für dieses Experiment habe ich Code aus diesen Ressourcen gesammelt:
- string_view odi et amo - MarcoArena
- Eine schnellere Studie zur Tokenisierung - tristanbrindle.com
Hier sind die beiden Versionen, eine für std::string und die zweite fürstd::string_view :
std::vector<std::string>
split(const std::string& str, const std::string& delims = " ")
{
std::vector<std::string> output;
auto first = std::cbegin(str);
while (first != std::cend(str))
{
const auto second = std::find_first_of(first, std::cend(str),
std::cbegin(delims), std::cend(delims));
if (first != second)
output.emplace_back(first, second);
if (second == std::cend(str))
break;
first = std::next(second);
}
return output;
}
Nein, mit string_view Version:
std::vector<std::string_view>
splitSV(std::string_view strv, std::string_view delims = " ")
{
std::vector<std::string_view> output;
size_t first = 0;
while (first < strv.size())
{
const auto second = strv.find_first_of(delims, first);
if (first != second)
output.emplace_back(strv.substr(first, second-first));
if (second == std::string_view::npos)
break;
first = second + 1;
}
return output;
}
Und hier ist der Benchmark:
const std::string_view LoremIpsumStrv{
/*one paragraph of lorem ipsum */
};
static void StringSplit(benchmark::State& state) {
std::string str { LoremIpsumStrv };
for (auto _ : state) {
auto v = split(str);
benchmark::DoNotOptimize(v);
}
}
// Register the function as a benchmark
BENCHMARK(StringSplit);
static void StringViewSplit(benchmark::State& state) {
for (auto _ : state) {
auto v = splitSV(LoremIpsumStrv);
benchmark::DoNotOptimize(v);
}
}
BENCHMARK(StringViewSplit);
Werden wir dieselbe 10-fache Leistungsgeschwindigkeit wie im vorherigen Benchmark erreichen … hmmm:
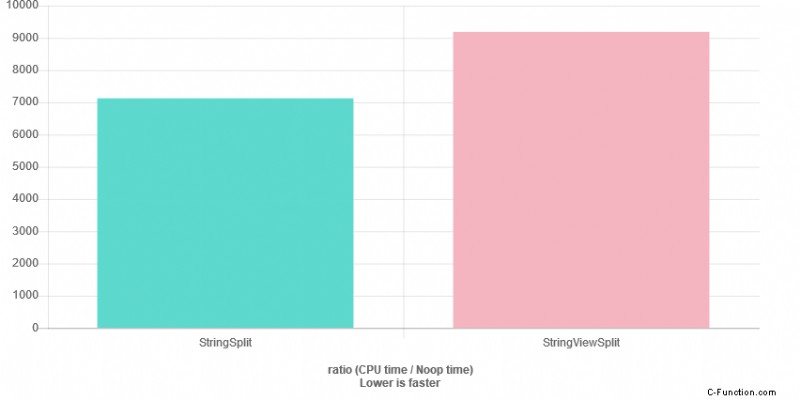
Dies ist GCC 8.1, -O3
Etwas besser mit Clang 6.0.0, -O3:
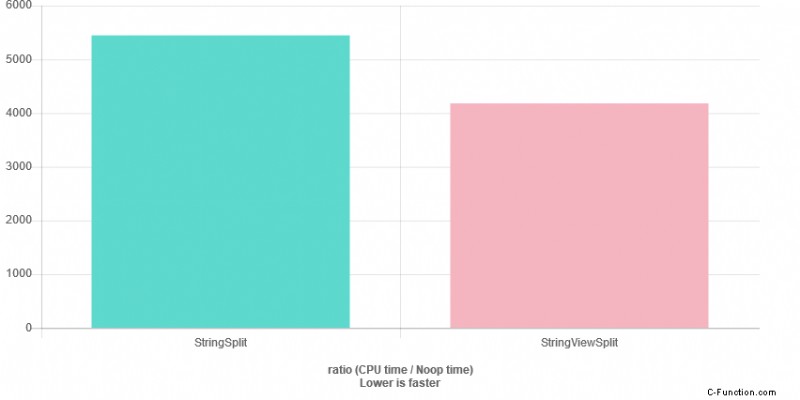
Ein etwas besseres Ergebnis, wenn ich es lokal in MSVC 2017 ausführe:
string length: 486
test iterations: 10000
string split: 36.7115 ms
string_view split: 30.2734 ms
Hier ist der Benchmark @Quick C++Bench
Haben Sie eine Idee, warum wir keine 10-fache Geschwindigkeit wie beim ersten Experiment sehen?
Natürlich können wir in diesem Fall nicht davon ausgehen, dass 10X realistisch ist.
Zunächst einmal haben wir einen Container - std::vector - die der Algorithmus zur Ausgabe der Ergebnisse verwendet. Die Speicherzuweisungen in std::vector wirkt sich auf die Gesamtgeschwindigkeit aus.
Wenn wir die Iteration einmal ausführen und wenn ich operator new überschreibe Ich sehe die folgenden Nummern (MSVC):
string length: 486
test iterations: 1
string split: 0.011448 ms, Allocation count: 15, size 6912
string_view split: 0.006316 ms, Allocation count: 12, size 2272
Wir haben 69 Wörter in dieser Zeichenfolge, die string Version generierte 15 Speicherzuweisungen (sowohl für Strings als auch um den vector zu erhöhen Leerzeichen), und insgesamt belegte es 6912 Bytes.
Der strng_view Version verwendet 12 Speicherzuweisungen (nur für vector da für string_view kein Speicher zugewiesen werden muss ) und insgesamt 2272 Bytes verwendet (3x weniger als diestd::string Version)
Einige Ideen zur Verbesserung
Sehen Sie sich den Kommentar von JFT an, in dem hier die Split-Algorithmen unter Verwendung von rohen Zeigern anstelle von Iteratoren implementiert wurden, und er erhielt viel mehr Leistungsverbesserungen.
Eine andere Möglichkeit besteht darin, im Vektor etwas Platz im Voraus zu reservieren (und später können wir shrink_to_fit verwenden - Auf diese Weise sparen wir eine Menge Speicherplatz.
Vergleich mit boost::split :
Der Vollständigkeit halber lasse ich den Benchmark auch gegen boost::split laufen (1.67), und unsere beiden Versionen sind viel schneller:
Läuft auf WandBox, GCC 8.1
string length: 489
test iterations: 10000
string split: 42.8627 ms, Allocation count: 110000, size 82330000
string_view split: 45.6841 ms, Allocation count: 80000, size 40800000
boost split: 117.521 ms, Allocation count: 160000, size 83930000
Die handgefertigte Version ist also fast 3x schneller als die boost.split Algorithmus!
Spielen Sie mit dem Code@WandBox
Zeichenfolge teilen und aus einer Datei laden
Sie werden vielleicht bemerken, dass meine Testzeichenfolge nur ein Absatz von „loremipsum“ ist. Solch ein einfacher Testfall kann einige zusätzliche Optimierungen im Compiler verursachen und zu unrealistischen Ergebnissen führen.
Ich habe einen netten Beitrag von Rainer Grimm gefunden:C++17 - Avoid Copying withstd::string_view -ModernesCpp.com
In dem Artikel verwendete er TXT-Dateien, um Zeichenfolgen zu verarbeiten. Es ist eine viel bessere Idee, an einigen echten und großen Textdateien zu arbeiten, anstatt an einfachen Zeichenketten.
Anstelle meines Lorem-Ipsum-Absatzes lade ich nur eine Datei, z. B. ~540 KB Text (Gutenberg-Projekt)
Hier ist ein Ergebnis eines Testlaufs über diese Datei:
string length: 547412
test iterations: 100
string split: 564.215 ms, Allocation count: 191800, size 669900000
string_view split: 363.506 ms, Allocation count: 2900, size 221262300
Der Test wird 100 Mal ausgeführt, also haben wir für eine Iteration 191800/100 = 1918 Speicherzuweisungen (insgesamt verwenden wir 669900000/100 = 6699000 bytes pro Iteration) für std::string .
Für string_view wir haben nur 2900/100 = 29 Speicherzuweisungen und221262300/100 = 2212623 bytes pro Iteration verwendet.
Es ist zwar immer noch kein 10-facher Gewinn, aber wir haben 3-mal weniger Speicherverbrauch und eine etwa 1,5-fache Leistungssteigerung.
Entschuldigung für die kleine Unterbrechung im Fluss :)
Ich habe einen kleinen Bonus vorbereitet, falls Sie an C++17 interessiert sind, sehen Sie sich das hier an:
Laden Sie eine kostenlose Kopie der C++17 Language RefCard herunter!
Risiken bei der Verwendung von string_view
Ich denke, dass jeder Artikel über string_view sollten auch die potenziellen Risiken erwähnen, die mit diesem neuen Typ verbunden sind:
- Aufpassen der (nicht)nullterminierten Strings -
string_viewdarf am Ende der Zeichenfolge nicht NULL enthalten. Auf so einen Fall muss man also vorbereitet sein.- Problematisch beim Aufrufen von Funktionen wie
atoi,printfdas akzeptiert nullterminierte Strings - Umwandlung in Strings
- Problematisch beim Aufrufen von Funktionen wie
- Referenzen und temporäre Objekte -
string_viewbesitzt keinen Speicher, daher müssen Sie sehr vorsichtig sein, wenn Sie mit temporären Objekten arbeiten.- Bei Rückgabe von
string_viewaus einer Funktion - Speichere
string_viewin Objekten oder Behältern.
- Bei Rückgabe von
Abschluss
Durch Nutzung von string_view , können Sie in vielen Anwendungsfällen eine Menge Leistungssteigerung erzielen. Es ist jedoch wichtig zu wissen, dass es Einschränkungen gibt und manchmal die Leistung im Vergleich zu std::string sogar noch langsamer sein kann !
Das erste ist das string_view besitzt die Daten nicht - also müssen Sie vorsichtig sein, damit Sie nicht mit Verweisen auf gelöschten Speicher enden!
Die zweite Sache ist, dass Compiler beim Umgang mit Zeichenfolgen sehr schlau sind, insbesondere wenn die Zeichenfolgen kurz sind (daher funktionieren sie gut mit SSO - SmallString Optimization), und in diesem Fall ist die Leistungssteigerung möglicherweise nicht so sichtbar.
Ein paar Fragen an Sie
Wie sind Ihre Erfahrungen mit string_view Leistung?
Können Sie einige Ergebnisse und Beispiele teilen?