Der Zweck von std::string_view besteht darin, das Kopieren von Daten zu vermeiden, die bereits jemand anderem gehören und von denen nur eine nicht mutierende Ansicht benötigt wird. In diesem Beitrag geht es also hauptsächlich um Leistung.
Heute schreibe ich über ein Hauptfeature von C++17.
Ich gehe davon aus, dass Sie ein wenig über std::string_view Bescheid wissen. Wenn nicht, lesen Sie zuerst den vorherigen Beitrag C++17 – Was ist neu in der Bibliothek. Ein C++-String ist wie ein dünner Wrapper, der seine Daten auf dem Heap speichert. Daher kommt es sehr oft vor, dass eine Speicherallokation einsetzt, wenn Sie mit C- und C++-Strings arbeiten. Schauen wir mal.
Kleine String-Optimierung
Sie werden in ein paar Zeilen sehen, warum ich diesen Abschnitt kleine String-Optimierung genannt habe.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | // sso.cpp
#include <iostream>
#include <string>
void* operator new(std::size_t count){
std::cout << " " << count << " bytes" << std::endl;
return malloc(count);
}
void getString(const std::string& str){}
int main() {
std::cout << std::endl;
std::cout << "std::string" << std::endl;
std::string small = "0123456789";
std::string substr = small.substr(5);
std::cout << " " << substr << std::endl;
std::cout << std::endl;
std::cout << "getString" << std::endl;
getString(small);
getString("0123456789");
const char message []= "0123456789";
getString(message);
std::cout << std::endl;
}
|
Ich habe den globalen Operator new in Zeile 6-9 überladen. So können Sie sehen, welche Operation eine Speicherallokation verursacht. Komm schon. Das ist leicht. Die Zeilen 19, 20, 28 und 29 bewirken eine Speicherzuweisung. Hier haben Sie die Nummern:
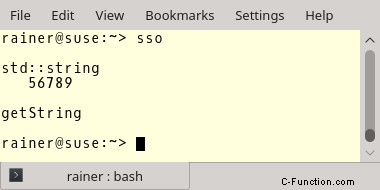
Was zum ...? Ich sagte, der String speichert seine Daten auf dem Heap. Das gilt aber nur, wenn der String eine implementierungsabhängige Größe überschreitet. Diese Größe für std::string ist 15 für MSVC und GCC und 23 für Clang.
Das heißt im Gegenteil, kleine Strings werden direkt im String-Objekt gespeichert. Daher ist keine Speicherzuweisung erforderlich.
Ab jetzt haben meine Strings immer mindestens 30 Zeichen. Ich muss also nicht über die Optimierung kleiner Zeichenfolgen nachdenken. Beginnen wir noch einmal, aber diesmal mit längeren Zeichenfolgen.
Keine Speicherzuweisung erforderlich
Jetzt strahlt std::string_view hell. Im Gegensatz zu std::string weist std::string_view keinen Speicher zu. Hier ist der Beweis.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | // stringView.cpp
#include <cassert>
#include <iostream>
#include <string>
#include <string_view>
void* operator new(std::size_t count){
std::cout << " " << count << " bytes" << std::endl;
return malloc(count);
}
void getString(const std::string& str){}
void getStringView(std::string_view strView){}
int main() {
std::cout << std::endl;
std::cout << "std::string" << std::endl;
std::string large = "0123456789-123456789-123456789-123456789";
std::string substr = large.substr(10);
std::cout << std::endl;
std::cout << "std::string_view" << std::endl;
std::string_view largeStringView{large.c_str(), large.size()};
largeStringView.remove_prefix(10);
assert(substr == largeStringView);
std::cout << std::endl;
std::cout << "getString" << std::endl;
getString(large);
getString("0123456789-123456789-123456789-123456789");
const char message []= "0123456789-123456789-123456789-123456789";
getString(message);
std::cout << std::endl;
std::cout << "getStringView" << std::endl;
getStringView(large);
getStringView("0123456789-123456789-123456789-123456789");
getStringView(message);
std::cout << std::endl;
}
|
Einmal mehr. Speicherallokationen finden in den Zeilen 24, 25, 41 und 43 statt. Aber was passiert bei den entsprechenden Aufrufen in den Zeilen 31, 32, 50 und 51? Keine Speicherzuweisung!
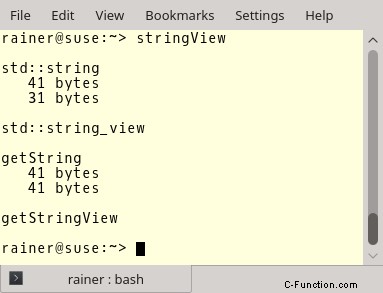
Das ist beeindruckend. Sie können sich vorstellen, dass dies eine Leistungssteigerung ist, da die Speicherzuweisung eine sehr teure Operation ist. Diesen Leistungsschub können Sie sehr gut beobachten, wenn Sie Teilstrings bestehender Strings bauen.
O(n) versus O(1)
std::string und std::string_view haben beide eine Methode substr. Die Methode von std::string gibt einen Teilstring zurück, aber die Methode von std::string_view gibt eine Ansicht eines Teilstrings zurück. Das klingt nicht so spannend. Aber es gibt einen großen Unterschied zwischen beiden Methoden. std::string::substr hat eine lineare Komplexität. std::string_view::substr hat eine konstante Komplexität. Das bedeutet, dass die Leistung der Operation auf std::string direkt von der Größe des Teilstrings abhängt, aber die Leistung der Operation auf std::string_view unabhängig von der Größe des Teilstrings ist.
Jetzt bin ich neugierig. Machen wir einen einfachen Leistungsvergleich.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | // substr.cpp
#include <chrono>
#include <fstream>
#include <iostream>
#include <random>
#include <sstream>
#include <string>
#include <vector>
#include <string_view>
static const int count = 30;
static const int access = 10000000;
int main(){
std::cout << std::endl;
std::ifstream inFile("grimm.txt");
std::stringstream strStream;
strStream << inFile.rdbuf();
std::string grimmsTales = strStream.str();
size_t size = grimmsTales.size();
std::cout << "Grimms' Fairy Tales size: " << size << std::endl;
std::cout << std::endl;
// random values
std::random_device seed;
std::mt19937 engine(seed());
std::uniform_int_distribution<> uniformDist(0, size - count - 2);
std::vector<int> randValues;
for (auto i = 0; i < access; ++i) randValues.push_back(uniformDist(engine));
auto start = std::chrono::steady_clock::now();
for (auto i = 0; i < access; ++i ) {
grimmsTales.substr(randValues[i], count);
}
std::chrono::duration<double> durString= std::chrono::steady_clock::now() - start;
std::cout << "std::string::substr: " << durString.count() << " seconds" << std::endl;
std::string_view grimmsTalesView{grimmsTales.c_str(), size};
start = std::chrono::steady_clock::now();
for (auto i = 0; i < access; ++i ) {
grimmsTalesView.substr(randValues[i], count);
}
std::chrono::duration<double> durStringView= std::chrono::steady_clock::now() - start;
std::cout << "std::string_view::substr: " << durStringView.count() << " seconds" << std::endl;
std::cout << std::endl;
std::cout << "durString.count()/durStringView.count(): " << durString.count()/durStringView.count() << std::endl;
std::cout << std::endl;
}
|
Lassen Sie mich ein paar Worte zu meinem Leistungstest sagen, bevor ich die Zahlen präsentiere. Die Kernidee des Performance-Tests besteht darin, eine große Datei als std::string einzulesen und mit std::string und std::string_view viele Teilstrings zu erzeugen. Mich interessiert genau, wie lange diese Erstellung von Teilstrings dauern wird.
Als lange Datei habe ich "Grimms Märchen" verwendet. Was sollte ich sonst verwenden? Der String grimmTales (Zeile 24) enthält den Inhalt der Datei. Ich fülle den std::vector
Hier sind die Zahlen. Sie sehen die Länge der Datei, die Zahlen für std::string::substr und std::string_view::substr und das Verhältnis zwischen beiden. Als Compiler habe ich GCC 6.3.0 verwendet.
Größe 30
Nur aus Neugier. Die Zahlen ohne Optimierung.
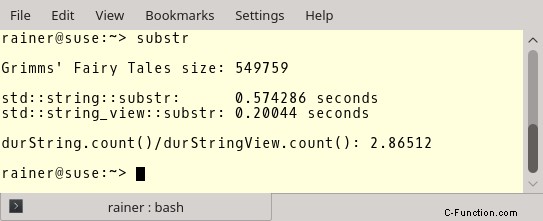
Aber nun zu den wichtigeren Zahlen. GCC mit vollständiger Optimierung.
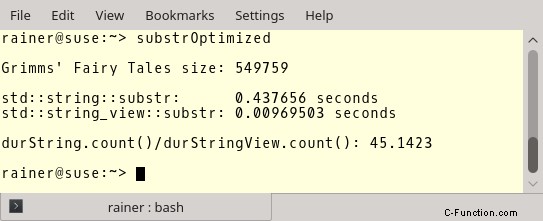
Die Optimierung macht keinen großen Unterschied im Fall von std::string, aber einen großen Unterschied im Fall von std::string_view. Das Erstellen eines Teilstrings mit std::string_view ist etwa 45-mal schneller als mit std::string. Wenn das kein Grund ist, std::string_view zu verwenden?
Verschiedene Größen
Jetzt werde ich neugieriger. Was passiert, wenn ich mit der Größenzählung der Teilzeichenfolge spiele? Natürlich sind alle Zahlen maximal optimiert. Ich habe sie auf die dritte Dezimalstelle gerundet.
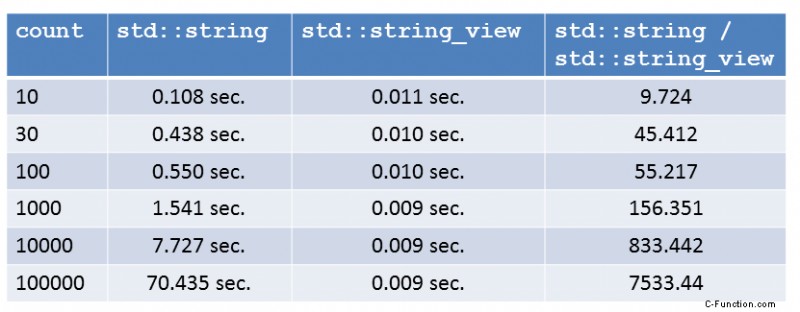
Ich bin nicht erstaunt, die Zahlen spiegeln die Komplexitätsgarantien von std::string::substr versus std::string_view::substr wider. Die Komplexität des ersten hängt linear von der Größe der Teilzeichenkette ab; die zweite ist unabhängig von der Größe des Teilstrings. Am Ende übertrifft std::string_view std::string.
drastischWas kommt als nächstes?
Es gibt noch mehr über std::any, std::optional und std::variant zu schreiben. Warten Sie auf den nächsten Beitrag.