In Regex geben Ihnen Erfassungsgruppen die Möglichkeit, Text zu speichern und später darauf zu verweisen. Erfassungsgruppen können benannt und mit ihrem Namen angesprochen werden. Wenn sie nicht genannt werden, beziehen Sie sich auf sie mit ihrer Indexnummer.
In diesem Artikel zeige ich, wie man benannte Erfassungsgruppen verwendet, indem ich das Problem löse, Daten aus Kindle-Highlights aus einem Buch zu extrahieren, das ich gerade zu Ende gelesen habe.
1 – Holen Sie sich die Rohdaten
Hier zunächst ein kleiner Ausschnitt einiger Highlights. Ich habe das von der Amazon Kindle Highlights-Website.
Your Kindle Notes For:
Fooled by Randomness: The Hidden Role of Chance in Life and in the Markets (Incerto Book 1)
Nassim Nicholas Taleb
Last accessed on Monday March 2, 2020
Note(s)
Yellow highlight | Page: 243
You attribute your successes to skills, but your failures to randomness.
Yellow highlight | Page: 248
A more human version can be read in Seneca’s Letters from a Stoic, a soothing and surprisingly readable book that I distribute to my trader friends (Seneca also took his own life when cornered by destiny).
Yellow highlight | Page: 249
Self-help books (even when they are not written by charlatans) are largely ineffectual.
Yellow highlight | Page: 249
The only article Lady Fortuna has no control over is your behavior. Good luck.Code language: plaintext (plaintext)2 – Bestimmen Sie, welche Daten Sie extrahieren möchten
Ich möchte die Seitenzahl und den hervorgehobenen Text.
Zum Beispiel möchte ich diese Zeile konvertieren:
Yellow highlight | Page: 249
The only article Lady Fortuna has no control over is your behavior. Good luck.Code language: plaintext (plaintext)Hier hinein:
| Seite | Text |
| 249 | Der einzige Artikel, über den Lady Fortuna keine Kontrolle hat, ist Ihr Verhalten. Viel Glück. |
3 – Regex schreiben
Ich verwende immer .NET Regex Tester, um Regex zu schreiben und schnell zu testen.
Hier ist die Regex, um die Seite und den Text aus den Hervorhebungsdaten zu extrahieren.
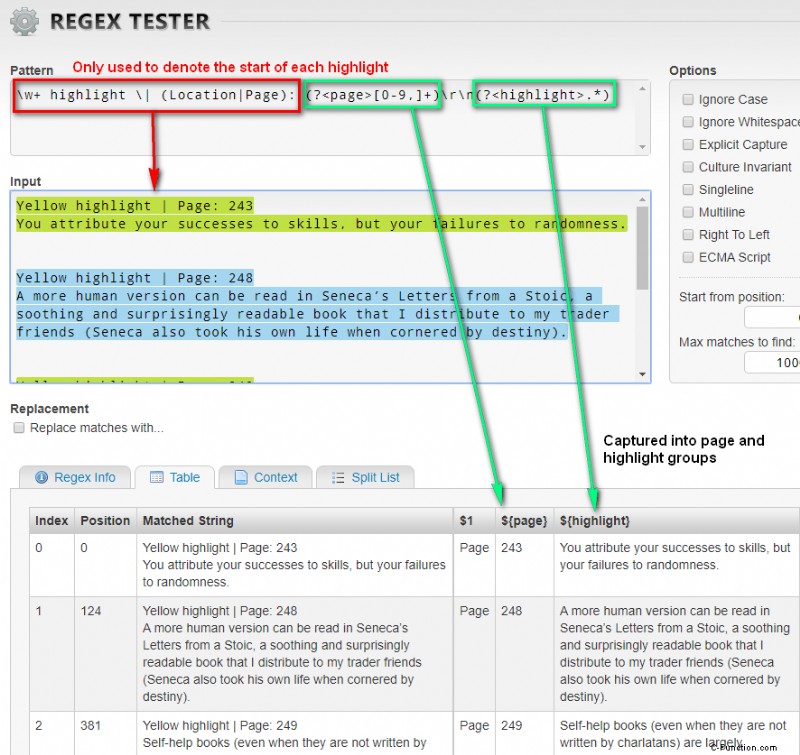
Diese Regex erklären
Ich werde die obige Regex-Anweisung aufschlüsseln und erklären.
\w+ highlight \| (Location|Page): Code language: plaintext (plaintext)Der Zweck davon ist, den Anfang jedes Höhepunkts zu finden.
| Regex | Erklärung |
| \w+ hervorheben | Entspricht einem oder mehreren alphanumerischen Zeichen, gefolgt vom wörtlichen „Highlight“. Ich hätte die Farben angeben können, anstatt irgendwelche Wörter zuzuordnen, wie hier (Blau|Gelb), aber ich habe stattdessen \w+ verwendet, weil ich dies nicht korrigieren möchte, wenn Kindle weitere hinzufügt Farben. |
| \| | Entspricht einem Pipe-Zeichen „|“. Dies muss mit „\“ maskiert werden, da „|“ ist ein Operator in Regex. |
| (Ort|Seite): | Entspricht dem Wort „Standort:“ oder „Seite:“. Ich habe beides in Kindle-Highlights gesehen. |
Da nun der Beginn jedes Highlight-Blocks bekannt ist, wird der zweite Teil der Regex verwendet, um die Daten zu erfassen, die ich aus dem Highlight-Block extrahieren möchte.
(?<page>[0-9,])\r\nCode language: plaintext (plaintext)| Regex | Erklärung |
| () | Einfangende Gruppe. Alles innerhalb der Klammern ist Teil der erfassten Gruppe und kann später referenziert werden. |
| ? | Nennt diese Erfassungsgruppe „Seite“. Diese Gruppe kann später unter dem Namen „Seite“ referenziert werden. |
| [0-9,] | Entspricht Ziffern und Kommas. Beispiel:99, 100, 1.000 |
| \r\n | Entspricht einem Windows-Zeilenumbruch. |
(?<highlight>.*)Code language: plaintext (plaintext)| Regex | Erklärung |
| () | Erfassungsgruppe |
| ? | Nennt die Erfassungsgruppe „Highlight“. |
| .* | Übereinstimmung mit allem |
4 – Regex im Code verwenden
using System;
using System.Collections.Generic;
using System.Text.RegularExpressions;
namespace RegexCapturingGroups
{
public class KindleHighlight
{
public int Page { get; set; }
public string Text { get; set; }
}
public class KindleHighlightParser
{
private static readonly Regex regex = new Regex(@"\w+ highlight \| (Location|Page): (?<page>[0-9,]+)\r\n(?<highlight>.*)", RegexOptions.Compiled);
public List<KindleHighlight> ParseHighlights(string rawHighlightData)
{
var kindleHighlights = new List<KindleHighlight>();
foreach (Match match in regex.Matches(rawHighlightData))
{
kindleHighlights.Add(new KindleHighlight()
{
Page = Convert.ToInt32(match.Groups["page"].Value),
Text = match.Groups["higlight"].Value
});
}
return kindleHighlights;
}
}
}
Code language: C# (cs)