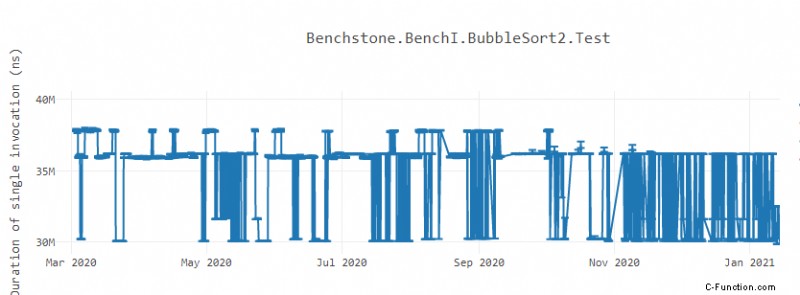
Beim Schreiben einer Software geben Entwickler ihr Bestes, um die Leistung zu maximieren, die sie aus dem Code herausholen können, den sie in das Produkt eingebrannt haben. Oft stehen den Entwicklern verschiedene Tools zur Verfügung, um die letzte Änderung zu finden, die sie in ihren Code quetschen können, um ihre Software schneller laufen zu lassen. Aber manchmal bemerken sie aufgrund einer völlig unabhängigen Änderung eine Langsamkeit im Produkt. Schlimmer noch, wenn die Leistung einer Funktion in einem Lab gemessen wird, zeigt sie möglicherweise instabile Leistungsergebnisse, die wie das folgende BubbleSort aussehen Grafik 1 . Was könnte möglicherweise eine solche Flockigkeit in die Leistung einführen?
Um dieses Verhalten zu verstehen, müssen wir zuerst verstehen, wie der vom Compiler generierte Maschinencode von der CPU ausgeführt wird. CPU abrufen den Maschinencode (auch bekannt als Anweisungsstrom), den er ausführen muss. Der Befehlsstrom wird als Folge von Bytes dargestellt, die als Opcode bekannt sind. Moderne CPUs holen die Opcodes von Befehlen in Blöcken von 16 Bytes (16B), 32 Bytes (32B) oder 64 Bytes (64B). Die CISC-Architektur hat eine Codierung mit variabler Länge, was bedeutet, dass der Opcode, der jede Anweisung in dem Anweisungsstrom darstellt, eine variable Länge hat. Wenn der Fetcher also einen einzelnen Chunk abruft, kennt er zu diesem Zeitpunkt den Anfang und das Ende einer Anweisung nicht. Aus dem Block des Befehlsstroms identifiziert der Pre-Decoder der CPU die Grenze und Länge der Befehle, während der Decoder die Bedeutung der Opcodes dieser einzelnen Befehle decodiert und Mikrooperationen erzeugt (μops ) für jede Anweisung. Diese μops werden in den Decoder Stream Buffer (DSB) eingespeist, der ein Cache ist, der μops indiziert mit der Adresse, von der die eigentliche Anweisung geholt wurde. Vor einem Fetch , prüft die CPU zuerst, ob der DSB den μops enthält der Anweisung, die es abrufen möchte. Wenn es bereits vorhanden ist, besteht keine Notwendigkeit, einen Zyklus von Befehlsabruf, Vordecodierung und Decodierung durchzuführen. Darüber hinaus gibt es auch einen Loop Stream Detector (LSD), der erkennt, ob ein Stream von μops ist stellt eine Schleife dar und wenn ja, überspringt es den Front-End-Abruf- und Dekodierungszyklus und fährt mit der Ausführung von μops fort bis eine Schleifenfehlvorhersage auftritt.
Codeausrichtung
Nehmen wir an, wir führen eine Anwendung auf einer CPU aus, die Anweisungen in 32B-Blöcken abruft. Die Anwendung verfügt über eine Methode mit einer heißen Schleife darin. Jedes Mal, wenn die Anwendung ausgeführt wird, wird der Maschinencode der Schleife an einem anderen Offset platziert. Manchmal könnte es so platziert werden, dass der Schleifenkörper die 32B-Adressgrenze nicht überschreitet. In diesen Fällen könnte der Befehlsabholer den Maschinencode der gesamten Schleife in einer Runde abrufen. Wenn der Maschinencode der Schleife hingegen so platziert wird, dass der Schleifenkörper die 32B-Grenze überschreitet, müsste der Abrufer den Schleifenkörper in mehreren Runden abrufen. Ein Entwickler kann die Variation der Abrufzeit nicht steuern, da diese davon abhängt, wo der Maschinencode der Schleife vorhanden ist. In solchen Fällen können Sie eine Instabilität in der Leistung der Methode feststellen. Manchmal läuft die Methode schneller, weil die Schleife an der für den Abrufer günstigen Adresse ausgerichtet war, während sie in anderen Fällen langsam sein kann, weil die Schleife falsch ausgerichtet war und der Abrufer Zeit mit dem Abrufen des Schleifenkörpers verbrachte. Selbst eine winzige Änderung, die nichts mit dem Methodenkörper zu tun hat (wie das Einführen einer neuen Variablen auf Klassenebene usw.), kann das Code-Layout beeinflussen und den Maschinencode der Schleife falsch ausrichten. Dies ist das Muster, das oben im Bubble-Sort-Benchmark zu sehen ist. Dieses Problem ist hauptsächlich in CISC-Architekturen wegen der Codierung der Befehle mit variabler Länge sichtbar. Die RISC-Architekturen CPUs wie Arm haben eine Codierung mit fester Länge und sehen daher möglicherweise keine so große Varianz in der Leistung.
Um dieses Problem zu lösen, führen Compiler eine Ausrichtung der Hotcode-Region durch, um sicherzustellen, dass die Leistung des Codes stabil bleibt. Codeausrichtung ist eine Technik, bei der ein oder mehrere NOP Anweisungen werden vom Compiler in den generierten Maschinencode unmittelbar vor der Hot-Region des Codes eingefügt, sodass der Hot-Code zu einer Adresse verschoben wird, die mod(16) ist , mod(32) oder mod(64) . Dadurch kann das maximale Abrufen des heißen Codes in weniger Zyklen erfolgen. Eine Studie zeigt, dass der Code durch die Durchführung solcher Ausrichtungen enorm profitieren kann. Außerdem ist die Leistung eines solchen Codes stabil, da sie nicht durch die Platzierung des Codes an einer falsch ausgerichteten Adressstelle beeinflusst wird. Um die Auswirkungen der Codeausrichtung im Detail zu verstehen, empfehle ich Ihnen dringend, sich den Vortrag „Ursachen von Leistungsschwankungen aufgrund der Codeplatzierung in IA“ anzusehen, den Intel-Ingenieurin Zia Ansari auf dem LLVM-Entwicklertreffen 2016 gehalten hat.
In .NET 5 haben wir damit begonnen, Methoden an der 32 B-Grenze auszurichten. In .NET 6 haben wir eine Funktion hinzugefügt, um eine adaptive Schleifenausrichtung durchzuführen, die NOP hinzufügt Füllanweisungen in einer Methode mit Schleifen, sodass der Schleifencode bei mod(16) beginnt oder mod(32) Speicheradresse. In diesem Blog werde ich die von uns getroffenen Designentscheidungen, verschiedene Heuristiken, die wir berücksichtigt haben, und die Analyse und Implikation beschreiben, die wir an über 100 Benchmarks untersucht haben, die uns zu der Annahme veranlasst haben, dass unser aktueller Schleifenausrichtungsalgorithmus bei der Stabilisierung und Verbesserung der Leistung von Vorteil sein wird von .NET-Code.
Heuristik
Als wir mit der Arbeit an dieser Funktion begannen, wollten wir folgende Dinge erreichen:
- Identifizieren Sie heiße innerste Schleifen, die sehr häufig ausgeführt werden.
- Fügen Sie
NOPhinzu Anweisungen vor dem Schleifencode so, dass die erste Anweisung innerhalb der Schleife auf die 32B-Grenze fällt.
Unten sehen Sie ein Beispiel für eine Schleife IG04~IG05 das wird ausgerichtet, indem 6 Byte von align hinzugefügt werden Anweisung. In diesem Beitrag werde ich die Auffüllung jedoch als align [X bytes] darstellen Bei der Disassemblierung geben wir tatsächlich Multi-Byte-NOP für das eigentliche Padding aus.
... 00007ff9a59ecff6 test edx, edx 00007ff9a59ecff8 jle SHORT G_M22313_IG06 00007ff9a59ecffa align [6 bytes] ; ............................... 32B boundary ............................... G_M22313_IG04: 00007ff9a59ed000 movsxd r8, eax 00007ff9a59ed003 mov r8d, dword ptr [rcx+4*r8+16] 00007ff9a59ed008 cmp r8d, esi 00007ff9a59ed00b jge SHORT G_M22313_IG14 G_M22313_IG05: 00007ff9a59ed00d inc eax 00007ff9a59ed00f cmp edx, eax 00007ff9a59ed011 jg SHORT G_M22313_IG04
Ein einfacher Ansatz wäre, allen Hot-Loops Padding hinzuzufügen. Wie ich jedoch im Abschnitt „Speicherkosten“ weiter unten beschreiben werde, ist das Auffüllen aller Methodenschleifen mit Kosten verbunden. Es gibt viele Überlegungen, die wir berücksichtigen müssen, um eine stabile Leistungssteigerung für die Hot Loops zu erzielen und sicherzustellen, dass die Leistung für Loops, die nicht von Padding profitieren, nicht herabgestuft wird.
Ausrichtungsgrenze
Je nach Design der Prozessoren profitiert die darauf laufende Software mehr, wenn der Hotcode auf 16B ausgerichtet ist , 32B oder 64B Ausrichtungsgrenze. Die Ausrichtung sollte ein Vielfaches von 16 sein und die am meisten empfohlene Grenze für große Hardwarehersteller wie Intel, AMD und Arm ist 32 byte , hatten wir 32 als unsere standardmäßige Ausrichtungsgrenze. Mit adaptiver Ausrichtung (gesteuert über COMPlus_JitAlignLoopAdaptive Umgebungsvariable und ist auf 1 gesetzt standardmäßig), versuchen wir, eine Schleife bei 32 byte auszurichten Grenze. Aber wenn wir nicht sehen, dass es rentabel ist, eine Schleife auf 32 byte auszurichten Grenze (aus den unten aufgeführten Gründen), versuchen wir, diese Schleife bei 16 byte auszurichten Grenze. Mit nicht adaptiver Ausrichtung (COMPlus_JitAlignLoopAdaptive=0 ), werden wir immer versuchen, eine Schleife an einem 32 byte auszurichten Ausrichtung standardmäßig. Die Ausrichtungsgrenze kann auch mit COMPlus_JitAlignLoopBoundary geändert werden Umgebungsvariable. Adaptive und nicht-adaptive Ausrichtung unterscheiden sich durch die Menge der hinzugefügten Füllbytes, die ich in Padding amount erläutern werde Abschnitt unten.
Schleifenauswahl
Mit einer Füllanweisung sind Kosten verbunden. Obwohl NOP Die Anweisung ist billig, es dauert einige Zyklen, um sie abzurufen und zu decodieren. Also zu viele NOP oder NOP Anweisungen im Hot-Code-Pfad können die Leistung des Codes beeinträchtigen. Daher ist es nicht angemessen, jede mögliche Schleife in einem Verfahren auszurichten. Aus diesem Grund hat LLVM -align-all-* oder gcc hat -falign-loops Flags, um Entwicklern die Kontrolle zu geben, damit sie entscheiden können, welche Schleifen ausgerichtet werden sollen. Daher wollten wir in erster Linie die Schleifen in der Methode identifizieren, die für die Ausrichtung am vorteilhaftesten sind. Zunächst haben wir uns entschieden, nur die nicht verschachtelten Schleifen auszurichten, deren Blockgewicht einen bestimmten Gewichtsschwellenwert erreicht (gesteuert durch COMPlus_JitAlignLoopMinBlockWeight ). Die Blockgewichtung ist ein Mechanismus, durch den der Compiler weiß, wie häufig ein bestimmter Block ausgeführt wird, und abhängig davon verschiedene Optimierungen an diesem Block durchführt. Im Beispiel unten j-loop und k-loop werden als Schleifenausrichtungskandidaten markiert, vorausgesetzt, sie werden häufiger ausgeführt, um die Blockgewichtungskriterien zu erfüllen. Dies erfolgt in der optIdentifyLoopsForAlignment-Methode des JIT.
Wenn eine Schleife einen Aufruf hat, werden die Anweisungen der aufrufenden Methode geleert und die des aufgerufenen geladen. In einem solchen Fall bringt es keinen Vorteil, die innerhalb des Anrufers vorhandene Schleife auszurichten. Daher haben wir uns entschieden, Schleifen, die einen Methodenaufruf enthalten, nicht auszurichten. Darunter l-loop , obwohl es nicht verschachtelt ist, hat es einen Aufruf und wird daher nicht ausgerichtet. Wir filtern solche Schleifen in AddContainsCallAllContainingLoops.
void SomeMethod(int N, int M) {
for (int i = 0; i < N; i++) {
// j-loop is alignment candidate
for (int j = 0; j < M; j++) {
// body
}
}
if (condition) {
return;
}
// k-loop is alignment candidate
for (int k = 0; k < M + N; k++) {
// body
}
for (int l = 0; l < M; l++) {
// body
OtherMethod();
}
} Sobald Schleifen in der frühen Phase identifiziert wurden, fahren wir mit erweiterten Prüfungen fort, um zu sehen, ob die Auffüllung von Vorteil ist und wenn ja, wie hoch die Auffüllung sein sollte. All diese Berechnungen finden in emitCalculatePaddingForLoopAlignment statt.
Schleifengröße
Das Ausrichten einer Schleife ist vorteilhaft, wenn die Schleife klein ist. Wenn die Schleifengröße zunimmt, verschwindet der Effekt des Auffüllens, da bereits viel Befehlsabruf, Decodierung und Steuerfluss stattfinden, sodass es keine Rolle spielt, an welcher Adresse der erste Befehl einer Schleife vorhanden ist. Wir haben die Schleifengröße auf 96 bytes voreingestellt Das sind 3 x 32-Byte-Blöcke. Mit anderen Worten, jede innere Schleife, die klein genug ist, um in 3 Blöcke von 32B zu passen jeweils für die Ausrichtung berücksichtigt. Zum Experimentieren kann diese Grenze mit COMPlus_JitAlignLoopMaxCodeSize geändert werden Umgebungsvariable.
Ausgerichtete Schleife
Als nächstes prüfen wir, ob die Schleife bereits an der gewünschten Ausrichtungsgrenze ausgerichtet ist (32 byte oder 16 byte für adaptive Ausrichtung und 32 byte für nicht-adaptive Ausrichtung). In solchen Fällen ist keine zusätzliche Polsterung erforderlich. Unten die Schleife bei IG10 beginnt an der Adresse 0x00007ff9a91f5980 == 0 (mod 32) ist bereits am gewünschten Offset und es ist keine zusätzliche Polsterung erforderlich, um es weiter auszurichten.
00007ff9a91f597a cmp dword ptr [rbp+8], r8d 00007ff9a91f597e jl SHORT G_M24050_IG12 ; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ (jl: 0) 32B boundary ............................... 00007ff9a91f5980 align [0 bytes] G_M24050_IG10: 00007ff9a91f5980 movsxd rdx, ecx 00007ff9a91f5983 mov r9, qword ptr [rbp+8*rdx+16] 00007ff9a91f5988 mov qword ptr [rsi+8*rdx+16], r9 00007ff9a91f598d inc ecx 00007ff9a91f598f cmp r8d, ecx 00007ff9a91f5992 jg SHORT G_M24050_IG10
Wir haben auch eine „Fast ausgerichtete Schleife“-Wache hinzugefügt. Es kann Schleifen geben, die nicht genau bei 32B beginnen Grenze, aber sie sind klein genug, um vollständig in einen einzigen 32B zu passen Stück. Der gesamte Code solcher Schleifen kann mit einer einzigen Befehlsholeranforderung abgerufen werden. Im folgenden Beispiel die Anweisungen zwischen den beiden 32B Grenze (gekennzeichnet mit 32B boundary ) passt in einen einzelnen Block von 32 Bytes. Die Schleife IG04 ist Teil dieses Chunks und seine Leistung wird sich nicht verbessern, wenn wir ihm zusätzliche Polsterung hinzufügen, damit die Schleife bei 32B beginnt Grenze. Auch ohne Padding wird die gesamte Schleife trotzdem in einer einzigen Anfrage abgerufen. Daher macht es keinen Sinn, solche Schleifen auszurichten.
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ (mov: 3) 32B boundary ............................... 00007ff9a921a903 call CORINFO_HELP_NEWARR_1_VC 00007ff9a921a908 xor ecx, ecx 00007ff9a921a90a mov edx, dword ptr [rax+8] 00007ff9a921a90d test edx, edx 00007ff9a921a90f jle SHORT G_M24257_IG05 00007ff9a921a911 align [0 bytes] G_M24257_IG04: 00007ff9a921a911 movsxd r8, ecx 00007ff9a921a914 mov qword ptr [rax+8*r8+16], rsi 00007ff9a921a919 inc ecx 00007ff9a921a91b cmp edx, ecx 00007ff9a921a91d jg SHORT G_M24257_IG04 G_M24257_IG05: 00007ff9a921a91f add rsp, 40 ; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ (add: 3) 32B boundary ...............................
Dies war ein wichtiger Schutz, den wir in unsere Schleifenausrichtungslogik eingefügt haben. Stellen Sie sich ohne dies eine Schleife der Größe 20 bytes vor die bei Offset mod(32) + 1 beginnt . Um diese Schleife auszurichten, musste sie mit 31 bytes aufgefüllt werden Dies ist in bestimmten Szenarien möglicherweise nicht von Vorteil, wenn 31 byte NOP Anweisungen befinden sich auf dem Hotcode-Pfad. Die „fast ausgerichtete Schleife“ schützt uns vor solchen Szenarien.
Die Prüfung auf „nahezu ausgerichtete Schleife“ beschränkt sich nicht nur auf eine kleine Schleife, die in eine einzelne 32B passt Stück. Für jede Schleife berechnen wir die minimale Anzahl von Chunks, die erforderlich sind, um in den Schleifencode zu passen. Wenn die Schleife nun bereits so ausgerichtet ist, dass sie diese Mindestanzahl von Chunks einnimmt, können wir das weitere Auffüllen der Schleife getrost ignorieren, da das Auffüllen sie nicht besser macht.
Im Beispiel unten die Schleife IG04 ist 37 bytes lang (00007ff9a921c690 - 00007ff9a921c66b = 37 ). Es sind mindestens 2 Blöcke von 32B erforderlich Stück zu passen. Wenn die Schleife irgendwo zwischen mod(32) beginnt und mod(32) + (64 - 37) , können wir das Auffüllen sicher überspringen, da die Schleife bereits so platziert ist, dass ihr Körper in 2 Anfragen abgerufen wird (32 bytes in der ersten Anfrage und 5 bytes in der nächsten Anfrage).
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ (xor: 2) 32B boundary ............................... 00007ff9a921c662 mov r12d, dword ptr [r14+8] 00007ff9a921c666 test r12d, r12d 00007ff9a921c669 jle SHORT G_M11250_IG07 00007ff9a921c66b align [0 bytes] G_M11250_IG04: 00007ff9a921c66b cmp r15d, ebx 00007ff9a921c66e jae G_M11250_IG19 00007ff9a921c674 movsxd rax, r15d 00007ff9a921c677 shl rax, 5 00007ff9a921c67b vmovupd ymm0, ymmword ptr[rsi+rax+16] ; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ (movupd: 1) 32B boundary ............................... 00007ff9a921c681 vmovupd ymmword ptr[r14+rax+16], ymm0 00007ff9a921c688 inc r15d 00007ff9a921c68b cmp r12d, r15d 00007ff9a921c68e jg SHORT G_M11250_IG04 G_M11250_IG05: 00007ff9a921c690 jmp SHORT G_M11250_IG07 ; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ (xor: 1) 32B boundary ...............................
Um es noch einmal zusammenzufassen:Bisher haben wir die heißen verschachtelten Schleifen in einer Methode identifiziert, die aufgefüllt werden muss, diejenigen herausgefiltert, die Aufrufe haben, und diejenigen herausgefiltert, die größer als unser Schwellenwert sind und überprüft, ob die erste Anweisung der Schleife so platziert ist, dass zusätzliches Auffüllen diese Anweisung an der gewünschten Ausrichtungsgrenze ausrichtet.
Auffüllbetrag
Um eine Schleife auszurichten, NOP Anweisungen müssen eingefügt werden, bevor die Schleife beginnt, sodass die erste Anweisung der Schleife an einer Adresse beginnt, die mod(32) ist oder mod(16) . Es kann eine Designentscheidung sein, wie viel Polsterung wir hinzufügen müssen, um eine Schleife auszurichten. Zum Beispiel können wir zum Ausrichten einer Schleife an der 32B-Grenze wählen, ob wir eine maximale Auffüllung von 31 Bytes hinzufügen oder den Auffüllbetrag einschränken möchten. Seit dem Auffüllen oder NOP Anweisungen sind nicht kostenlos, sie werden ausgeführt (entweder als Teil des Methodenablaufs oder wenn die ausgerichtete Schleife in einer anderen Schleife verschachtelt ist), und daher müssen wir sorgfältig auswählen, wie viel Auffüllung hinzugefügt werden soll. Bei nicht adaptivem Ansatz, wenn eine Ausrichtung bei N erfolgen muss Bytes-Grenze, versuchen wir höchstens N-1 hinzuzufügen Bytes, um die erste Anweisung der Schleife auszurichten. Also mit 32B oder 16B nicht-adaptive Technik, werden wir versuchen, eine Schleife an der 32-Byte- oder 16-Byte-Grenze auszurichten, indem wir höchstens 31 Bytes bzw. 15 Bytes hinzufügen.
Wie oben erwähnt, haben wir jedoch festgestellt, dass das Hinzufügen von viel Padding die Leistung des Codes beeinträchtigt. Beispiel:Eine 15 Byte lange Schleife beginnt bei Offset mod(32) + 2 , mit nicht adaptivem 32B Ansatz würden wir 30 bytes hinzufügen des Auffüllens, um diese Schleife an der nächsten 32B auszurichten Grenzadresse. Um also eine 15 Byte lange Schleife auszurichten, haben wir zusätzliche 30 Byte hinzugefügt, um sie auszurichten. Wenn die von uns ausgerichtete Schleife eine verschachtelte Schleife wäre, würde der Prozessor diese 30 Byte NOP abrufen und decodieren Anweisungen für jede Iteration der äußeren Schleife. Wir haben auch die Größe der Methode um 30 Bytes erhöht. Schließlich würden wir immer versuchen, eine Schleife bei 32B auszurichten Grenze, könnten wir im Vergleich zu der erforderlichen Menge an Polsterung mehr Polsterung hinzufügen, wenn wir die Schleife an 16B ausrichten müssten Grenze. Mit all diesen Mängeln haben wir einen adaptiven Ausrichtungsalgorithmus entwickelt.
Bei der adaptiven Ausrichtung würden wir die Menge der hinzugefügten Polsterung abhängig von der Größe der Schleife begrenzen. Bei dieser Technik beträgt die größtmögliche Auffüllung, die hinzugefügt wird, 15 Bytes für eine Schleife, die in einen 32-B-Block passt. Wenn die Schleife größer ist und in zwei 32-B-Blöcke passt, würden wir die Auffüllmenge auf 7 Bytes reduzieren und so weiter. Der Grund dafür ist, dass je größer die Schleife wird, desto geringer die Auswirkung auf die Ausrichtung ist. Mit diesem Ansatz könnten wir eine Schleife ausrichten, die 4 32-B-Blöcke benötigt, wenn das erforderliche Auffüllen 1 Byte beträgt. Mit dem nicht-adaptiven 32B-Ansatz würden wir solche Schleifen niemals ausrichten (wegen COMPlus_JitAlignLoopMaxCodeSize Grenze).
| Max Pad (Bytes) | Es werden mindestens 32 Blöcke benötigt, um in die Schleife zu passen |
|---|---|
| 15 | 1 |
| 7 | 2 |
| 3 | 3 |
| 1 | 4 |
Als Nächstes versucht der Algorithmus aufgrund der Auffüllbegrenzung, die Schleife an 16B auszurichten, wenn wir die Schleife nicht an der 32B-Grenze ausrichten können Grenze. Wir reduzieren das maximale Polsterungslimit, wenn wir hier ankommen, wie in der Tabelle unten zu sehen.
| Max Pad (Bytes) | Mindestens 32 Blöcke, um in die Schleife zu passen |
|---|---|
| 7 | 1 |
| 3 | 2 |
| 1 | 3 |
Mit dem adaptiven Ausrichtungsmodell, anstatt das Auffüllen einer Schleife vollständig einzuschränken (aufgrund der Auffüllbegrenzung von 32B ), werden wir trotzdem versuchen, die Schleife an der nächst besseren Ausrichtungsgrenze auszurichten.
Polsterplatzierung
Wenn festgestellt wird, dass eine Polsterung erforderlich ist, und wir die Polsterungsmenge berechnen, ist die wichtige Designentscheidung, wo die Polsterungsanweisungen platziert werden sollen. In .NET 6 wird dies naiv gemacht, indem die Auffüllanweisung direkt vor dem Beginn der Schleife platziert wird. Aber wie oben beschrieben, kann dies die Leistung nachteilig beeinflussen, da die Füllanweisungen auf den Ausführungspfad fallen können. Ein klügerer Weg wäre, einige blinde Flecken im Code vor der Schleife zu erkennen und sie so zu platzieren, dass die Auffüllanweisung nicht oder nur selten ausgeführt wird. Wenn wir z. B. irgendwo im Methodencode einen unbedingten Sprung haben, könnten wir nach diesem unbedingten Sprung eine Auffüllanweisung hinzufügen. Auf diese Weise stellen wir sicher, dass die Auffüllanweisung nie ausgeführt wird, aber wir bekommen die Schleife trotzdem an der rechten Grenze ausgerichtet. Ein weiterer Ort, an dem ein solches Padding hinzugefügt werden kann, ist ein Codeblock oder ein Block, der selten ausgeführt wird (basierend auf profilgeführten Optimierungsdaten). Der blinde Fleck, den wir auswählen, sollte lexikalisch vor der Schleife liegen, die wir auszurichten versuchen.
00007ff9a59feb6b jmp SHORT G_M17025_IG30 G_M17025_IG29: 00007ff9a59feb6d mov rax, rcx G_M17025_IG30: 00007ff9a59feb70 mov ecx, eax 00007ff9a59feb72 shr ecx, 3 00007ff9a59feb75 xor r8d, r8d 00007ff9a59feb78 test ecx, ecx 00007ff9a59feb7a jbe SHORT G_M17025_IG32 00007ff9a59feb7c align [4 bytes] ; ............................... 32B boundary ............................... G_M17025_IG31: 00007ff9a59feb80 vmovupd xmm0, xmmword ptr [rdi] 00007ff9a59feb84 vptest xmm0, xmm6 00007ff9a59feb89 jne SHORT G_M17025_IG33 00007ff9a59feb8b vpackuswb xmm0, xmm0, xmm0 00007ff9a59feb8f vmovq xmmword ptr [rsi], xmm0 00007ff9a59feb93 add rdi, 16 00007ff9a59feb97 add rsi, 8 00007ff9a59feb9b inc r8d 00007ff9a59feb9e cmp r8d, ecx ; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ (cmp: 1) 32B boundary ............................... 00007ff9a59feba1 jb SHORT G_M17025_IG31
Im obigen Beispiel haben wir die Schleife IG31 ausgerichtet mit 4 bytes padding, aber wir haben das padding direkt vor der ersten Anweisung der Schleife eingefügt. Stattdessen können wir diese Auffüllung nach jmp hinzufügen Anweisung vorhanden unter 00007ff9a59feb6b . Auf diese Weise wird das Padding nie ausgeführt, sondern IG31 wird dennoch an der gewünschten Grenze ausgerichtet.
Speicherkosten
Zuletzt muss bewertet werden, wie viel zusätzlicher Speicher von der Laufzeit für das Hinzufügen der zusätzlichen Auffüllung vor der Schleife zugewiesen wird. Wenn der Compiler jede heiße Schleife ausrichtet, kann er die Codegröße einer Methode erhöhen. Es muss ein richtiges Gleichgewicht zwischen der Schleifengröße, der Häufigkeit ihrer Ausführung, der erforderlichen Polsterung und der Platzierung der Polsterung bestehen, um sicherzustellen, dass nur die Schleifen gepolstert werden, die wirklich von der Ausrichtung profitieren. Ein weiterer Aspekt ist, dass, wenn das JIT, bevor es Speicher für den generierten Code zuweist, auswerten kann, wie viel Auffüllen zum Ausrichten einer Schleife erforderlich ist, es eine genaue Menge an Speicher anfordert, um die zusätzliche Auffüllanweisung aufzunehmen. Wie in RyuJIT generieren wir jedoch zuerst den Code (unter Verwendung unserer internen Datenstrukturen), summieren die gesamte Befehlsgröße und bestimmen dann die Menge an Speicher, die zum Speichern der Befehle benötigt wird. Als nächstes weist es den Speicher aus der Laufzeit zu und schließlich gibt es die eigentlichen Maschinenanweisungen aus und speichert sie im zugewiesenen Speicherpuffer. Während der Codegenerierung (wenn wir die Schleifenausrichtungsberechnung durchführen) kennen wir den Offset nicht, an dem die Schleife im Speicherpuffer platziert wird. In einem solchen Fall müssen wir pessimistisch von der maximal möglichen Polsterung ausgehen, die benötigt wird. Wenn es viele Schleifen in einer Methode gibt, die von der Ausrichtung profitieren würden, würde die Annahme einer maximal möglichen Auffüllung für alle Schleifen die Zuordnungsgröße dieser Methode erhöhen, obwohl die Codegröße viel kleiner wäre (abhängig von der tatsächlich hinzugefügten Auffüllung).
Die folgende Grafik zeigt die Auswirkungen der Codegröße und der Zuordnungsgröße aufgrund der Schleifenausrichtung. Die Zuordnungsgröße stellt die Speichermenge dar, die zum Speichern des Maschinencodes aller .NET-Bibliotheksmethoden zugewiesen wird, während die Codegröße die tatsächliche Speichermenge darstellt, die zum Speichern des Maschinencodes der Methode benötigt wird. Die Codegröße ist für 32BAdaptive am niedrigsten Technik. Dies liegt daran, dass wir, wie zuvor besprochen, die Füllmenge in Abhängigkeit von der Schleifengröße abgeschnitten haben. Aus der Erinnerungsperspektive also 32BAdaptive Gewinnt. Die Zahlen auf der Y-Achse stellen Code- und Zuordnungsgrößen in Byte dar.
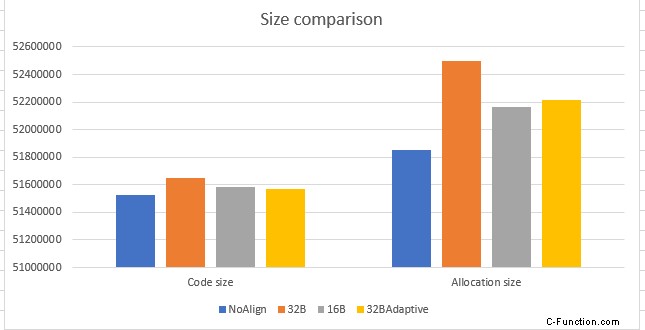
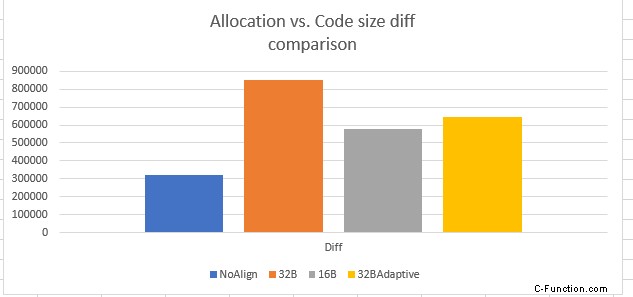
Die Zuweisungsgröße im obigen Diagramm ist höher als die Codegröße für die gesamte Implementierung, da wir bei der Berechnung der Zuweisungsgröße die maximal mögliche Auffüllung für jede Schleife berücksichtigt haben. Idealerweise wollten wir die Zuweisungsgröße gleich der Codegröße haben. Unten ist eine weitere Ansicht, die den Unterschied zwischen der Zuordnungsgröße und der Codegröße zeigt. Der Unterschied ist am größten für die nicht-adaptive 32B-Implementierung und am geringsten für die nicht-adaptive 16B-Implementierung. 32B Adaptiv ist geringfügig höher als 16B Nicht-Adaptiv, aber da die Gesamtcodegröße im Vergleich zu 16B/32B Nicht-Adaptiv minimal ist, 32BAdaptive ist der Gewinner.
Um jedoch sicherzustellen, dass wir die genaue Füllmenge kennen, die wir hinzufügen werden, bevor wir den Speicher zuweisen, haben wir eine Problemumgehung entwickelt. Während der Codegenerierung wissen wir, dass die Methode bei Offset 0(mod 32) beginnt . Wir berechnen die Polsterung, die zum Ausrichten der Schleife erforderlich ist, und aktualisieren den align Anweisung mit diesem Betrag. Somit würden wir den Speicher unter Berücksichtigung der tatsächlichen Auffüllung zuweisen und würden keinen Speicher für Schleifen zuweisen, für die wir keine Auffüllung benötigen. Dies funktioniert, wenn die geschätzte Größe aller Anweisungen während der Codegenerierung einer Methode mit der tatsächlichen Größe während der Ausgabe dieser Anweisungen übereinstimmt. Manchmal stellen wir während des Sendens fest, dass es optimal ist, eine kürzere Codierung für eine Anweisung zu haben, und dass die geschätzte von der tatsächlichen Größe dieser Anweisung abweicht. Wir können es uns nicht leisten, dass diese Fehlvorhersage für Anweisungen auftritt, die vor der auszurichtenden Schleife liegen, da dies die Platzierung der Schleife ändern würde.
Im Beispiel unten beginnt die Schleife bei IG05 und während der Codegenerierung wissen wir, dass wir diese Schleife durch Hinzufügen einer Auffüllung von 1 Byte bei 0080 ausrichten können versetzt. Aber während der Ausgabe der Anweisung, wenn wir uns entscheiden, instruction_1 zu codieren so dass es nur 2 Bytes statt 3 Bytes (die wir geschätzt haben) benötigt, beginnt die Schleife bei der Speicheradresse 00007ff9a59f007E . Durch Hinzufügen von 1 Byte Auffüllung würde es bei 00007ff9a59f007F beginnen was wir nicht wollten.
007A instruction_1 ; size = 3 bytes 007D instruction_2 ; size = 2 bytes IG05: 007F instruction_3 ; start of loop 0083 instruction_4 0087 instruction_5 0089 jmp IG05
Daher kompensieren wir diese Überschätzung bestimmter Anweisungen, indem wir zusätzliche NOP-Anweisungen hinzufügen. Wie unten zu sehen, mit diesem NOP , beginnt unsere Schleife weiterhin bei 00007ff9a59f007F und durch das Auffüllen von 1 Byte wird es bei 00007ff9a59f0080 ausgerichtet Adresse.
00007ff9a59f007A instruction_1 ; size = 2 bytes 00007ff9a59f007C NOP ; size = 1 byte (compensation) 00007ff9a59f007D instruction_2 ; size = 2 bytes IG05: 00007ff9a59f007F instruction_3 ; start of loop 00007ff9a59f0083 instruction_4 00007ff9a59f0087 instruction_5 0089 jmp IG05
Damit können wir Speicher für generierten Code genau so zuweisen, dass die Differenz zwischen zugewiesener und tatsächlicher Codegröße Null ist. Langfristig wollen wir das Problem der Überschätzung angehen, damit die Instruktionsgröße bei der Codegenerierung genau bekannt ist und beim Aussenden der Instruktion übereinstimmt.
Auswirkung
Lassen Sie uns abschließend über die Auswirkungen dieser Arbeit sprechen. Obwohl ich viele und viele Analysen durchgeführt habe, um die Auswirkungen der Schleifenausrichtung auf unsere verschiedenen Benchmarks zu verstehen, möchte ich zwei Diagramme hervorheben, die sowohl die erhöhte Stabilität als auch die verbesserte Leistung aufgrund der Schleifenausrichtung zeigen.
In der unteren Leistungsgrafik von Bubble Sort stellt Datenpunkt 1 den Punkt dar, an dem wir mit der Ausrichtung der Methoden bei 32B begonnen haben Grenze. Datenpunkt 2 stellt den Punkt dar, an dem wir begonnen haben, die inneren Schleifen auszurichten, die ich oben beschrieben habe. Wie Sie sehen können, hat sich die Instabilität stark verringert und wir haben auch an Leistung gewonnen.
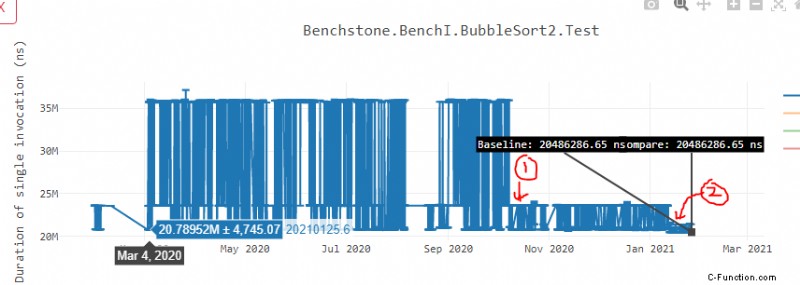
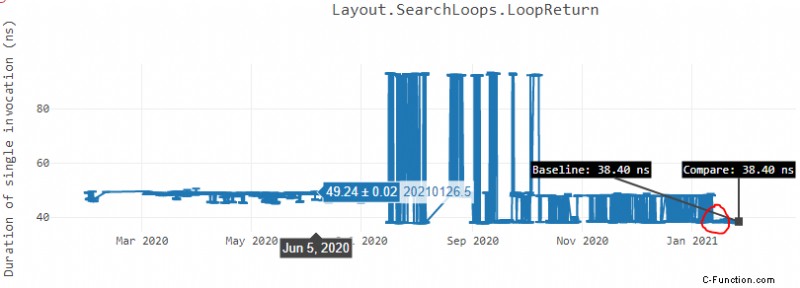
Unten ist eine weitere Grafik des „LoopReturn“-Benchmarks 2 lief auf Ubuntu x64 Box, wo wir einen ähnlichen Trend sehen.
Unten ist die Grafik, die den Vergleich verschiedener Algorithmen zeigt, die wir versucht haben, um die Auswirkungen der Schleifenausrichtung über Benchmarks hinweg zu verstehen. In diesem Diagramm stellt die X-Achse alle Mikrobenchmarks dar, sortiert nach der Auswirkung, die sie aufgrund der Schleifenausrichtung haben. Die Y-Achse repräsentiert die log10-Skala von before / after Verhältnis, bevor es ohne Schleifenausrichtung ist und nachdem es mit der Schleifenausrichtung ist. Da die Benchmark-Messungen in nanoseconds sind Je höher das Verhältnis, desto performanter wurden die Benchmarks mit dem Loop-Alignment. 32B und 16B stellt eine nicht-adaptive Technik dar, während 32BAdaptive steht für 32B adaptive Technik.
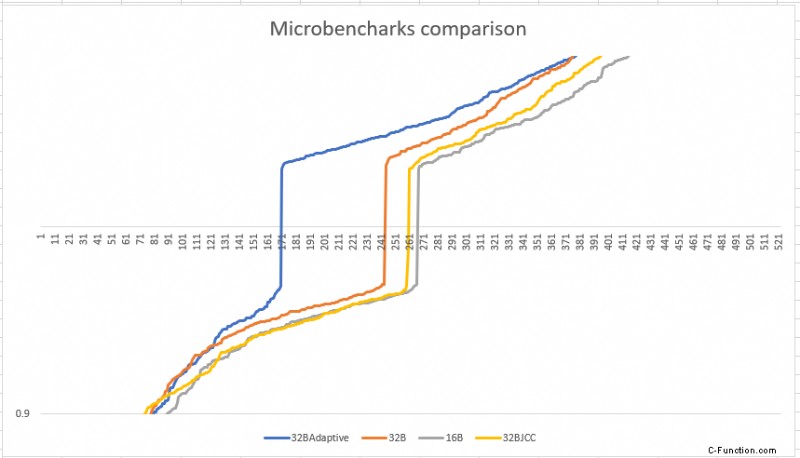
32B Adaptive verbessert sich früher nach 171 Benchmarks im Vergleich zum nächstbesseren Ansatz, nämlich 32B Non-Adaptive, das nach 241 Benchmarks an Leistung gewinnt. Mit dem adaptiven 32B-Ansatz erzielen wir schneller maximale Leistungsvorteile.
Randfälle
Während der Implementierung der Loop-Alignment-Funktion bin ich auf einige Randfälle gestoßen, die es wert sind, erwähnt zu werden. Wir erkennen, dass eine Schleife ausgerichtet werden muss, indem wir ein Flag auf den ersten Basisblock setzen, der Teil der Schleife ist. Wenn die Schleife in späteren Phasen ausgerollt wird, müssen wir sicherstellen, dass wir das Ausrichtungsflag aus dieser Schleife entfernen, da es die Schleife nicht mehr darstellt. Ebenso mussten wir für andere Szenarien wie das Klonen von Schleifen oder das Eliminieren falscher Schleifen sicherstellen, dass wir das Ausrichtungs-Flag entsprechend aktualisiert haben.
Zukunftsarbeit
Eine unserer geplanten zukünftigen Arbeiten ist, die „Padding-Platzierung“ in blinden Flecken hinzuzufügen, wie ich es oben beschrieben habe. Darüber hinaus müssen wir nicht nur das Ausrichten der inneren Schleifen einschränken, sondern auch der äußeren Schleifen, deren relatives Gewicht höher ist als das der inneren Schleife. Im Beispiel unten i-loop 1000 Mal ausgeführt, während die j-loop wird in jeder Iteration nur zweimal ausgeführt. Wenn wir die j-loop auffüllen Wir werden die aufgefüllte Anweisung am Ende 1000 Mal ausführen lassen, was teuer werden kann. Ein besserer Ansatz wäre, stattdessen den i-loop aufzufüllen und auszurichten .
for (int i = 0; i < 1000; i++) {
for (int j = 0; j < 2; j++) {
// body
}
}
Schließlich ist die Schleifenausrichtung nur für x86 aktiviert und x64 Architektur, aber wir würden sie gerne weiterentwickeln und Arm32 unterstützen und Arm64 auch Architekturen.
Schleifenausrichtung in anderen Compilern
Für native oder vorzeitige Compiler ist es schwer vorherzusagen, welche Schleife ausgerichtet werden muss, da die Zieladresse, an der die Schleife platziert wird, nur während der Laufzeit und nicht während bekannt sein kann Zusammenstellung im Voraus. Bestimmte native Laufzeitumgebungen geben dem Benutzer jedoch zumindest eine Option, um ihn die Ausrichtung angeben zu lassen.
GCC
GCC stellt -falign-functions bereit Attribut, das der Benutzer einer Funktion hinzufügen kann. Weitere Dokumentation finden Sie auf der GCC-Dokumentationsseite im Abschnitt „Ausgerichtet“. Dadurch wird die erste Anweisung jeder Funktion an der angegebenen Grenze ausgerichtet. Es bietet auch Optionen für -falign-loops , -falign-labels und -falign-jumps Dadurch werden alle Schleifen, Beschriftungen oder Sprünge im gesamten Code ausgerichtet, der kompiliert wird. Ich habe den GCC-Code nicht untersucht, aber wenn ich mir diese Optionen ansehe, hat er mehrere Einschränkungen. Erstens ist der Füllbetrag fest und kann zwischen 0 und (N – 1) Bytes liegen. Zweitens erfolgt die Ausrichtung für die gesamte Codebasis und kann nicht auf einen Teil von Dateien, Methoden, Schleifen oder heißen Regionen beschränkt werden.
LLVM
Wie bei GCC ist eine dynamische Ausrichtung während der Laufzeit nicht möglich, sodass auch LLVM dem Benutzer eine Option zur Auswahl der Ausrichtung bietet. Dieser Blog gibt einen guten Überblick über die verschiedenen verfügbaren Optionen. Eine der angebotenen Optionen ist align-all-nofallthru-blocks Dadurch werden keine Füllanweisungen hinzugefügt, wenn der vorherige Block den aktuellen Block erreichen kann, indem er durchfällt, da dies bedeuten würde, dass wir NOPs im Ausführungspfad hinzufügen. Stattdessen versucht es, die Auffüllung an Blöcken hinzuzufügen, die mit unbedingten Sprüngen enden. Das ist wie das, was ich oben unter „Polsterplatzierung“ erwähnt habe.
Schlussfolgerung
Codeausrichtung ist ein komplizierter Mechanismus, der in einem Compiler implementiert werden muss, und es ist sogar noch schwieriger sicherzustellen, dass er die Leistung eines Benutzercodes optimiert. Wir begannen mit einer einfachen Problemstellung und Erwartung, mussten aber während der Implementierung verschiedene Experimente durchführen, um sicherzustellen, dass wir die maximal möglichen Fälle abdecken, in denen die Ausrichtung von Vorteil wäre. Wir mussten auch berücksichtigen, dass die Ausrichtung die Leistung nicht negativ beeinflusst, und einen Mechanismus entwickeln, um solche Oberflächenbereiche zu minimieren. Ich bin Andy Ayers zu großem Dank verpflichtet, der mich anleitete und einige großartige Ideen bei der Implementierung der Schleifenausrichtung vorschlug.
Referenzen
- BubbleSort2-Benchmark ist Teil der Micro-Benchmarks-Suite von .NET und der Quellcode befindet sich im dotnet/performance-Repository. Die im .NET-Leistungslabor erzielten Ergebnisse können auf der BubbleSort2-Ergebnisseite eingesehen werden.
- Der LoopReturn-Benchmark ist Teil der Micro-Benchmarks-Suite von .NET und der Quellcode befindet sich im dotnet/performance-Repository. Ergebnisse aus dem .NET-Leistungslabor können auf der LoopReturn-Ergebnisseite eingesehen werden.