Der Gastbeitrag dieser Woche stammt von Matthew Butler, der uns einige Einblicke darüber gibt, wie die Beziehung zwischen Komplexität und Leistung in mehrfacher Hinsicht weniger als offensichtlich sein kann. Matthew ist Systemarchitekt und Softwareingenieur und entwickelt Systeme für Physikforschung, Netzwerksicherheit, Strafverfolgung und das Verteidigungsministerium. Er arbeitet hauptsächlich in C/C++ und Modern C++ und ist auf Twitter zu finden.
Es gibt eine Geschichte, die seit Jahren über Jon Bentley erzählt wird (Programming Pearls, Addison-Wesley, 1986 ) kam eines Tages aufgeregt in Bjarne Stroustrups Büro und stellte ihm ein Problem:
„Fügen Sie eine Folge zufälliger Ganzzahlen in eine sortierte Folge ein und entfernen Sie dann diese Elemente nacheinander, wie durch eine zufällige Folge von Positionen bestimmt. Verwenden Sie einen Vektor oder eine verkettete Liste?“
Ich bin mir nicht sicher, ob dies eine wahre Geschichte ist oder ob es überhaupt so passiert ist, aber es bringt einen interessanten Punkt über die Komplexität von Algorithmen und Datenstrukturen auf.
Wenn wir das Problem streng unter dem Gesichtspunkt der Komplexität analysieren, sollten verkettete Listen Arrays problemlos schlagen. Zufälliges Einfügen in eine verkettete Liste ist O(1) für das Einfügen und O(n) für das Finden der richtigen Stelle. Zufälliges Einfügen in ein Array ist O(n) für das Einfügen und O(n) für das Finden der richtigen Stelle. Das Entfernen ist ähnlich.
Dies liegt hauptsächlich daran, dass Arrays beim Einfügen oder Löschen große Speicherblöcke verschieben müssen, während verknüpfte Listen nur ein paar Zeiger verschieben. Bei einer strengen Komplexitätsanalyse sollte also eine Listenimplementierung leicht gewinnen.
Aber tut es das?
Ich habe diese Hypothese mit std::list, einer doppelt verknüpften Liste, und std::vector getestet. Ich habe dies für einen Datensatz mit einer kleinen Anzahl von Elementen getan:100, 1.000, 2.000, 3.000, 4.000, 5.000, 6.000, 7.000, 8.000, 9.000 und 10.000. Jeder Lauf wurde mit einem hochauflösenden Zeitmesser gemessen.
Codesegment für std::list:
while (count < n)
{
rand_num = rand();
for (it = ll.begin(); it != ll.end(); ++it)
if (rand_num < *it)
break;
ll.insert(it, rand_num);
++count;
}
while (count > 0)
{
rand_num = rand() % count;
it = ll.begin();
advance(it, rand_num);
ll.erase(it);
--count;
}
Code für std::vector:
while (count < n)
{
rand_num = rand();
for (i = 0; i < count; ++i)
if (rand_num < vec[i])
break;
vec.insert(vec.begin() + i, rand_num);
++count;
}
while (count > 0)
{
rand_num = rand() % count;
vec.erase(vec.begin() + rand_num);
--count;
}
Code für einen optimierten std::vector, der eine binäre Suche verwendet, um den Einfügepunkt zu finden, und reserve(), um zu verhindern, dass der Vektor verschoben wird, wenn er wächst.
vec.reserve(n);
while (count < n)
{
rand_num = rand();
it = std::lower_bound(vec.begin(), vec.end(), rand_num);
vec.insert(it, rand_num);
++count;
}
while (count > 0)
{
rand_num = rand() % count;
vec.erase(vec.begin() + rand_num);
--count;
}
Die Ergebnisse
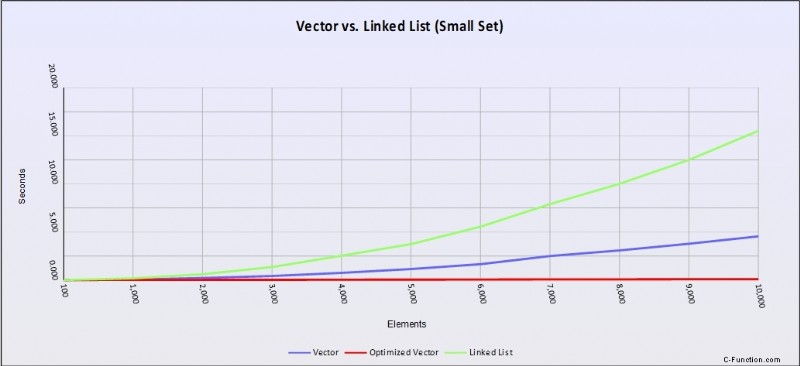
Abbildung 1 – Leistungskurven ( load vs time) für std::list (grün), std::vector (blau) und einen optimierten std::vector (rot) unter Verwendung von Ganzzahlen. Eine niedrigere Linie bedeutet eine bessere Leistung.
Offensichtlich verliert std::list stark. Aber das überraschende Ergebnis ist die nahezu flache Performance der optimierten Version von std::vector. Wie haben wir also Diagramme erhalten, die dem widersprechen, was die Komplexitätsanalyse uns gesagt hat?
Dies ist einer der zentralen Fehler der Komplexitätsanalyse. Die Komplexitätsanalyse betrachtet nur die Datenstruktur und den Algorithmus, als ob sie im Äther laufen würden. Es berücksichtigt nicht die relativistischen Effekte der Hardware, auf der wir laufen. In diesem Fall arbeiten der CPU-Cache und der Prefetcher im Hintergrund, um sicherzustellen, dass die benötigten Daten für einen schnelleren Zugriff vorab in die Cache-Zeilen geladen werden.
std::vector, das nur ein Speicherblock ist, ist für den Prefetcher angesichts unserer linearen Zugriffsmuster leicht zu verstehen. Es antizipiert die nächsten Speicherblöcke, auf die wir zugreifen möchten, und hält sie geladen und bereit, wenn wir versuchen, darauf zuzugreifen.
Verknüpfte Listen hingegen können nicht vorab abgerufen werden, da jeder neue Link auf eine andere Stelle im Speicher verweist und der Vorabrufer darüber keine Vernunft anstellen kann. Jede Bewegung nach unten in der Liste wird zu einem Cache-Mißerfolg, der dazu führt, dass die CPU die Cache-Zeile übergibt und sie mit einem anderen Speicherblock auffüllt.
Das bedeutet, dass der Zugriff auf das nächste Element von 0,9 ns (wenn es sich bereits im Cache befindet) bis 120 ns dauert, um es aus dem Hauptspeicher zu laden. In diesem Fall ist die beste Qualität von std::list – die Fähigkeit, einige Zeiger zum Einfügen oder Löschen zu verschieben – auch die Achilles-Heilung auf Cache-basierten Architekturen.
Wenn Sie sich den obigen Code angesehen haben, ist Ihnen auch aufgefallen, dass ich den wahlfreien Zugriff zum Löschen aus dem Vektor verwendet habe. Auch wenn dies ein Vorteil zu sein scheint, ist es wirklich nicht. Es gibt keine Garantie dafür, dass der nächste zu entfernende Wert in der Nähe des letzten liegt, und der Prefetcher hat kein Verständnis dafür, wie Sie Ihre Daten im Speicher strukturiert haben. Es sieht die Erinnerung einfach als einen langen, formlosen Strom. Das bedeutet, dass Sie möglicherweise Cache-Fehlschläge erleiden, je nachdem, wie groß das Array ist und wo Sie suchen.
Aber was ist mit der Verwendung der binären Suche?
Das ist ein pseudozufälliges Zugriffsmuster, das eine ganze Menge Cache-Fehler verursachen sollte. Und doch war der „auf Leistung getrimmte“ std::vector selbst mit seinen Cache-Fehlern blitzschnell.
Es gibt ein paar Dinge zu beachten:
- Wir haben O(log n) Zugriffe für eine binäre Suche durchgeführt, was weitaus weniger ist als eine lineare Traversierung, die O(n) ist.
-
Der Verzweigungsprädiktor arbeitet, um das einzelne if() zu erstellen Anweisung innerhalb der binären Suche effizienter, indem vorhergesagt wird, welches Ergebnis bei jeder Schleife wahrscheinlicher ist.
-
Wir haben das gesamte Array vorab zugewiesen, was bedeutet, dass es nicht verschoben werden musste, wenn es wuchs und möglicherweise keinen Platz mehr hatte.
Größere Daten
Aber was passiert, wenn die von uns verarbeiteten Daten keine Ganzzahl sind? Was ist, wenn es etwas Größeres ist, wie ein 4K-Puffer?
Hier sind die Ergebnisse mit demselben Code, aber mit einem 4K-Puffer.
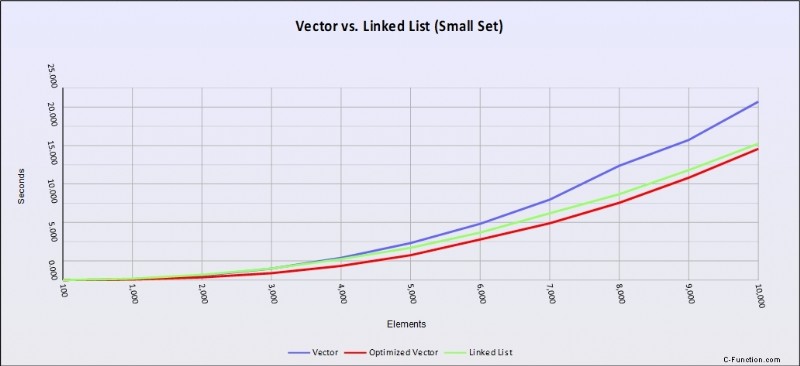
Abbildung 2 – Leistungskurven ( load vs time) für std::list (grün), std::vector (blau) und einen optimierten std::vector (rot) mit 4K-Puffern. Eine niedrigere Linie bedeutet eine bessere Leistung.
Derselbe Code mit einer größeren Datengröße verhält sich jetzt ganz anders. Verlinkte Listen kommen voll zur Geltung und machen nicht nur den Geschwindigkeitsvorteil eines Arrays zunichte, sie machen auch fast den Vorteil der optimierten Version zunichte.
Das liegt daran, dass Blöcke unseres Arrays nicht mehr sauber in eine Cache-Zeile passen und der Pre-Fetcher immer wieder zum Hauptspeicher zurückkehren muss, was die gleiche Art von Cache-Fehlern verursacht, die wir in verknüpften Listen sehen. Außerdem haben Sie den Overhead des Einfügens in ein Array, was zu Speicherbewegungen großer Speichersegmente führt.
Die Imbissbuden:
-
Testen Sie Ihre Lösungen immer, da dies das einzig wahre Maß für die Leistung ist. Unsere Intuition liegt fast immer falsch. In diesem Fall lag die Komplexitätsanalyse im Ergebnis falsch, weil die Komplexitätsanalyse die Betriebsumgebung nicht berücksichtigt. Insbesondere die Auswirkungen von Caching, Prefetcher, Verzweigungsvorhersage und Zugriffsmustern im Speicher.
-
Behandeln Sie Vorgänge mit -> als sehr teure Vorgänge, da sie Cache-Fehler beinhalten. Das ist der Hauptgrund, warum std::list so schlecht versagt hat. std::vector verwendete dieselbe lineare Suche wie std::list, aber da der Prefetcher und der Verzweigungsprädiktor den Cache für uns voll hielten, war die Leistung viel besser.
-
Kennen Sie die Standardalgorithmen. Zu wissen, dass lower_bound() eine binäre Suche ist, gibt uns einen massiven Leistungsschub. Es vereinfachte auch den Algorithmus und fügte etwas Sicherheitsspielraum hinzu, da das Schleifen durch einen Vektor mit operator[] etwas gefährlich ist, da es uns möglicherweise ermöglicht, über das Ende des Vektors hinauszulaufen, ohne es zu wissen. Bereichsbasierte for-Schleifen sind eine bessere Wahl.
-
Verstehen Sie die Leistungsmerkmale der Container, die Sie verwenden, und wissen Sie, welche spezifischen Implementierungen sie verwenden. std::multimap basiert typischerweise auf einem rot-schwarzen Baum, während std::unordered_map auf einer Hash-Tabelle mit geschlossener Adressierung und Buckets basiert. Beide sind assoziative Container, aber beide haben sehr unterschiedliche Zugriffsmuster und Leistungsmerkmale.
-
Gehen Sie nicht automatisch davon aus, dass std::vector immer die schnellste Lösung ist. Das ist heute Ketzerei, wenn man bedenkt, wie gut es auf Cache-basierter Hardware funktioniert. Bei größeren Elementen verliert es jedoch viele seiner Vorteile. Und obwohl es nicht schwer ist, einen Vektor in einen assoziativen Container zu rollen, gibt es Probleme, die er nicht gut handhabt, wie z. B. Parsing (Versuche sind dafür besser) oder Netzwerke (gerichtete Graphen sind besser). Zu sagen, dass alles, was wir brauchen, ein Vektor und eine flache Hash-Map mit offener Adressierung und lokaler Sondierung ist, ist etwas kurzsichtig.
-
Gehen Sie nicht davon aus, dass die Verzweigungsvorhersage, der Prefetcher oder der Cache dazu führen, dass ineffizienter Code schneller ausgeführt wird. In der Vektorimplementierung wäre es verlockend anzunehmen, dass das Lesen von vec.size() bei jeder Iteration statt der Verwendung von count genauso schnell wäre. In diesem Fall stimmt das nicht, also testen Sie es, um sicherzugehen.
-
Elementgröße zählt. Ganzzahlen sind klein, aber wenn die Elemente, auf die zugegriffen wird, groß sind (z. B. strukturierte Daten), machen verknüpfte Listen einen Großteil des Geschwindigkeitsvorteils von Arrays zunichte.
-
Denken Sie daran, dass die Komplexitätsanalyse ein Maß für Effizienz ist – nicht für Leistung.