 Gastautor Vincent Zalzal spricht mit uns über leichte, starke Typen. Vincent ist ein Softwareentwickler, der seit 12 Jahren in der Computer-Vision-Branche tätig ist. Er schätzt alle Komplexitätsebenen der Softwareentwicklung, von der Optimierung von Speicher-Cache-Zugriffen über die Entwicklung von Algorithmen und Heuristiken zur Lösung komplexer Anwendungen bis hin zur Entwicklung stabiler und benutzerfreundlicher Frameworks. Sie finden ihn online auf Twitter oder LinkedIn.
Gastautor Vincent Zalzal spricht mit uns über leichte, starke Typen. Vincent ist ein Softwareentwickler, der seit 12 Jahren in der Computer-Vision-Branche tätig ist. Er schätzt alle Komplexitätsebenen der Softwareentwicklung, von der Optimierung von Speicher-Cache-Zugriffen über die Entwicklung von Algorithmen und Heuristiken zur Lösung komplexer Anwendungen bis hin zur Entwicklung stabiler und benutzerfreundlicher Frameworks. Sie finden ihn online auf Twitter oder LinkedIn.
Starke Typen fördern einen sichereren und ausdrucksstärkeren Code. Ich werde nicht wiederholen, was Jonathan bereits in seiner Serie über starke Typen vorgestellt hat.
Ich vermute, dass einige Leute finden, dass NamedType Das Klassen-Template hat eine schöne Oberfläche, verwendet aber eine etwas schwere Maschinerie, um das bescheidene Ziel einer starken Typisierung zu erreichen. Für diese Leute habe ich gute Neuigkeiten:Sie können viele der Funktionalitäten von NamedType nutzen , mit einem sehr einfachen Werkzeug. Dieses Werkzeug ist die bescheidene Struktur.
Struktur als starker Typ
Sehen wir uns eine vereinfachte Version von NamedType an , ohne Skills:
template <typename T, typename Parameter>
class NamedType
{
public:
explicit NamedType(T const& value) : value_(value) {}
template<typename T_ = T, typename = IsNotReference<T_>>
explicit NamedType(T&& value) : value_(std::move(value)) {}
T& get() { return value_; }
T const& get() const {return value_; }
private:
T value_;
};
Diese Klasse verbirgt den zugrunde liegenden Wert und gibt mit get() Zugriff darauf . Es scheint kein set() zu geben Methode, aber es ist immer noch da, versteckt in get() Funktion. In der Tat seit dem get() Funktion gibt eine nicht konstante Referenz zurück, wir können Folgendes tun:
using Width = NamedType<double, struct WidthTag>; Width width(42); width.get() = 1337;
Seit get() Methode keine Invariante erzwingt und der zugrunde liegende Wert zugänglich ist, ist er im Wesentlichen öffentlich. Dann machen wir es öffentlich! Dadurch werden wir die get() los Funktionen. Da außerdem alles in der Klasse öffentlich ist und semantisch keine Invariante erzwingt, verwenden wir stattdessen eine Struktur:
template <typename T, typename Parameter>
struct NamedType
{
explicit NamedType(T const& value) : value_(value) {}
template<typename T_ = T, typename = IsNotReference<T_>>
explicit NamedType(T&& value) : value_(std::move(value)) {}
T value_;
}; Aber Moment mal:Brauchen wir diese expliziten Konstruktoren wirklich? Wenn wir sie entfernen, können wir die Aggregatinitialisierung verwenden, die genau das Gleiche bewirkt. Wir enden mit:
template <typename T, typename Parameter>
struct NamedType
{
T value_;
}; Diese Struktur verwendet keinen Code mehr wieder. Die letzte Vereinfachung besteht also darin, eine Nicht-Template-Struktur direkt zu verwenden, um den starken Typ zu definieren.
struct Width { double v; }; Da haben Sie es:ein starker Typ, ohne schwere Maschinen. Möchten Sie es in Aktion sehen?
struct Width { double v; };
struct Height { double v; };
class Rectangle { /* ... */ };
Rectangle make_rect(Width width, Height height) { return Rectangle(/* ... */); }
Rectangle make_square(Width width) { return Rectangle(/* ... */); }
void foo()
{
// Aggregate initialization copies lvalues and moves rvalues.
Width width {42.0};
// constexpr also works.
constexpr Width piWidth {3.1416};
// get() and set() are free.
// set() copies lvalues and moves rvalues.
double d = width.v;
width.v = 1337.0;
// Copy and move constructors are free.
Width w1 {width};
Width w2 {std::move(w1)};
// Copy and move assignment operators are free.
w1 = width;
w2 = std::move(w1);
// Call site is expressive and type-safe.
auto rect = make_rect(Width{1.618}, Height{1.0});
// make_rect(Height{1.0}, Width{1.618}); does not compile
// Implicit conversions are disabled by default.
// make_rect(1.618, 1.0); does not compile
// double d1 = w1; does not compile
// Call site can also be terse, if desired (not as type-safe though).
auto square = make_square( {2.718} );
}
Dieser Code sieht dem Code sehr ähnlich, den Sie mit NamedType erhalten würden (mit Ausnahme der letzten Zeile, die durch den expliziten Konstruktor verhindert würde). Hier sind einige zusätzliche Vorteile der Verwendung von Strukturen als starke Typen:
- besser lesbare Stacktraces (
NamedTypekann ziemlich ausführliche Namen erzeugen) - Code für unerfahrene C++-Entwickler leichter verständlich und somit einfacher in Unternehmen zu übernehmen
- eine externe Abhängigkeit weniger
Ich mag die Konvention, v zu verwenden für den zugrunde liegenden Wert, da er nachahmt, was der Standard für Variablenvorlagen verwendet, wie std::is_arithmetic_v oder std::is_const_v . Natürlich können Sie das verwenden, was Sie am besten finden, wie val oder value . Eine weitere nette Konvention besteht darin, den zugrunde liegenden Typ als Namen zu verwenden:
struct Width { double asDouble; };
void foo()
{
Width width {42};
auto d = width.asDouble;
}
Fähigkeiten
Die Verwendung der oben dargestellten Struktur erfordert den direkten Zugriff auf das zugrunde liegende Element. Oft sind nur wenige Operationen an der Struktur erforderlich, und der direkte Zugriff auf das zugrunde liegende Element kann in Elementfunktionen der Klasse mithilfe des starken Typs verborgen werden. In anderen Fällen, in denen Rechenoperationen erforderlich sind, beispielsweise bei einer Breite, sind jedoch Fähigkeiten erforderlich, um nicht immer wieder Operatoren implementieren zu müssen.
Der von NamedType verwendete Vererbungsansatz oder boost::operators funktioniert gut. Ich behaupte nicht, dass die Methode, die ich hier vorstelle, elegant ist, aber sie ist eine Alternative zur Verwendung von Vererbung, die Vorteile hat, insbesondere Einfachheit.
Operator-Überladung
Beachten Sie zunächst, dass fast alle Operatoren in C++ als Nicht-Member-Funktionen implementiert werden können. Hier sind die Operatoren, die nicht als Nicht-Member-Funktionen implementiert werden können:
- Zuweisung, also
operator=(in unserem Fall ist die implizit generierte Version in Ordnung) - Funktionsaufruf, also
operator() - subskriptieren, also
operator[] - Klassenmitgliedszugriff, d. h.
operator-> - Konvertierungsfunktionen, z.B.
operator int() - Zuweisungs- und Freigabefunktionen (
new,new[],delete,delete[])
Alle anderen überladbaren Operatoren können als Nicht-Member-Funktionen implementiert werden. Zur Auffrischung, hier sind sie:
– unär:+ - * & ~ ! ++ (vor und nach) -- (pre und post)
– binär:+ - * / % ^ & | < > += -= *= /= %= ^= &= |= << >> >>= <<= == != <= >= && || , ->*
Als Beispiel für den Width oben eingeben, würde der Kleiner-als-Operator so aussehen:
inline bool operator<(Width lhs, Width rhs)
{
return lhs.v < rhs.v;
} Als Randnotiz habe ich mich aus Leistungsgründen dafür entschieden, die Breiten als Wert im obigen Code zu übergeben. Aufgrund ihrer geringen Größe werden diese Strukturen normalerweise direkt in Registern übergeben, wie arithmetische Typen. Der Optimierer optimiert auch die Kopie weg, da er hier hauptsächlich mit arithmetischen Typen arbeitet. Schließlich sind bei binären Operationen manchmal weitere Optimierungen möglich, weil der Compiler sicher weiß, dass kein Aliasing stattfindet, d. h. die beiden Operanden nicht denselben Speicher teilen. Für größere Strukturen (mein persönlicher Schwellenwert ist mehr als 8 Bytes) oder Strukturen mit nicht-trivialen Konstruktoren würde ich die Parameter per konstanter Lvalue-Referenz übergeben.
Alle anderen Vergleichsoperatoren müssten ähnlich definiert werden. Um zu vermeiden, dass dieser Code immer wieder für jeden starken Typ wiederholt wird, müssen wir einen Weg finden, ihn zu generieren diesen Code.
Der Vererbungsansatz
NamedType verwendet Vererbung und CRTP als Codegenerator. Es hat den Vorteil, Teil der Sprache zu sein. Es verunreinigt jedoch den Typnamen, insbesondere beim Betrachten einer Aufrufliste. Zum Beispiel die Funktion:
using NT_Int32 = fluent::NamedType<int32_t, struct Int32, fluent::Addable>; void vectorAddNT(NT_Int32* dst, const NT_Int32* src1, const NT_Int32* src2, int N);
ergibt folgende Zeile im Aufrufstack:
vectorAddNT(fluent::NamedType<int,Int32,fluent::Addable> * dst, const fluent::NamedType<int,Int32,fluent::Addable> * src1, const fluent::NamedType<int,Int32,fluent::Addable> * src2, int N)
Dies gilt für eine Fertigkeit; das Problem wird schlimmer, je mehr Skills hinzugefügt werden.
Der Präprozessor-Ansatz
Der älteste Codegenerator wäre der Präprozessor. Makros könnten verwendet werden, um den Bedienercode zu generieren. Code in Makros ist jedoch selten eine gute Option, da während des Debuggens nicht auf Makros zugegriffen werden kann.
Eine andere Möglichkeit, den Präprozessor als Codegenerator zu verwenden, ist die Verwendung von include files . Breakpoints können problemlos in inkludierten Dateien gesetzt und betreten werden. Leider müssen wir, um Parameter an den Codegenerator zu übergeben, auf die Verwendung von define-Direktiven zurückgreifen, aber es ist ein geringer Preis zu zahlen.
struct Width { double v; };
#define UTIL_OP_TYPE_T_ Width
#include <util/operators/less_than_comparable.hxx>
#undef UTIL_OP_TYPE_T_
Die Datei less_than_comparable.hxx würde so aussehen:
inline bool operator<(UTIL_OP_TYPE_T_ lhs, UTIL_OP_TYPE_T_ rhs)
{
return lhs.v < rhs.v;
}
inline bool operator>(UTIL_OP_TYPE_T_ lhs, UTIL_OP_TYPE_T_ rhs)
{
return lhs.v > rhs.v;
}
// ...
Es empfiehlt sich, für Dateien, die auf diese Weise eingebunden werden, eine andere Endung als üblich zu verwenden. Dies sind keine normalen Header; beispielsweise dürfen Header Guards auf keinen Fall in ihnen verwendet werden. Die Erweiterung .hxx wird seltener verwendet, wird aber von den meisten Editoren als C++-Code erkannt und kann daher eine gute Wahl sein.
Um andere Operatoren zu unterstützen, binden Sie einfach mehrere Dateien ein. Es ist möglich (und wünschenswert), eine Hierarchie von Operatoren zu erstellen, wie es in boost::operators getan wird (wobei der Name less_than_comparable kommt von). Beispielsweise könnten die Fähigkeiten addierbar und subtrahierbar unter dem Namen additive gruppiert werden .
struct Width { double v; };
#define UTIL_OP_TYPE_T_ Width
#include <util/operators/additive.hxx>
#include <util/operators/less_than_comparable.hxx>
// ...
#undef UTIL_OP_TYPE_T_
// util/operators/additive.hxx
#include <util/operators/addable.hxx>
#include <util/operators/subtractable.hxx>
// util/operators/addable.hxx
inline UTIL_OP_TYPE_T_ operator+(UTIL_OP_TYPE_T_ lhs, UTIL_OP_TYPE_T_ rhs)
{
return {lhs.v + rhs.v};
}
inline UTIL_OP_TYPE_T_& operator+=(UTIL_OP_TYPE_T_& lhs, UTIL_OP_TYPE_T_ rhs)
{
lhs.v += rhs.v;
return lhs;
}
// etc
Es mag überraschen, dass operator+= kann als Nicht-Member-Funktion implementiert werden. Ich denke, es unterstreicht die Tatsache, dass die Struktur als Daten und nicht als Objekt angesehen wird. Es hat selbst keine Mitgliedsfunktion. Wie oben erwähnt, gibt es jedoch einige Operatoren, die nicht als Nicht-Member-Funktionen implementiert werden können, insbesondere operator-> .
Ich würde argumentieren, dass, wenn Sie diese Operatoren überladen müssen, der starke Typ semantisch keine Struktur mehr ist und Sie besser NamedType verwenden würden .
Nichts hindert Sie jedoch daran, Dateien in die Struct-Definition aufzunehmen, auch wenn einige Leute bei diesem Anblick zusammenzucken mögen:
#define UTIL_OP_TYPE_T_ WidgetPtr
struct WidgetPtr
{
std::unique_ptr<Widget> v;
#include <util/operators/dereferenceable.hxx>
};
#undef UTIL_OP_TYPE_T_ Der Code-Generator-Ansatz
Große Unternehmen wie Google verlassen sich immer mehr auf Bots, um Code (siehe protobuf) und Commits (siehe diese Präsentation) zu generieren. Der offensichtliche Nachteil der Methode besteht darin, dass Sie ein externes Tool (wie zum Beispiel Cog) benötigen, das in das Build-System integriert ist, um den Code zu generieren. Sobald der Code jedoch generiert ist, ist er sehr einfach zu lesen und zu verwenden (und auch zu analysieren und zu kompilieren). Da jeder starke Typ seine eigene generierte Kopie hat, ist es auch einfacher, einen Haltepunkt in einer Funktion für einen bestimmten Typ zu setzen.
Die Verwendung eines Tools zum Generieren von Code kann zu einer eleganten Pseudosprache von Schlüsselwörtern führen, die der Sprache hinzugefügt werden. Dies ist der Ansatz von Qt, und sie verteidigen ihn gut (siehe Warum verwendet Qt Moc für Signale und Slots?)
Fertigkeiten für Aufzählungen
Fähigkeiten können auch bei Aufzählungen nützlich sein, um Bit-Flags zu implementieren. Nebenbei bemerkt, der Vererbungsansatz kann nicht auf Aufzählungen angewendet werden, da sie keine Funktionalität erben können. In diesem Fall können jedoch Strategien verwendet werden, die auf Nicht-Member-Funktionen basieren. Bit-Flags sind ein interessanter Anwendungsfall, der einen eigenen Artikel verdient.
Leistung
Wie Jonathan bereits sagte, NamedType ist eine Zero-Cost-Abstraktion:Bei einem ausreichenden Optimierungsgrad (typischerweise O1 oder O2) geben Compiler denselben Code aus, als ob arithmetische Typen direkt verwendet würden. Dies gilt auch für die Verwendung einer Struktur als starken Typ. Allerdings wollte ich testen, ob Compiler den Code auch bei Verwendung von NamedType korrekt vektorisieren können oder eine Struktur anstelle von arithmetischen Typen.
Ich habe den folgenden Code in Visual Studio 2017 (Version 15.5.7) mit Standardversionsoptionen in 32-Bit- und 64-Bit-Konfigurationen kompiliert. Ich habe Godbolt verwendet, um GCC 7.3 und Clang 5.0 in 64-Bit mit dem Optimierungs-Flag -O3 zu testen.
using NT_Int32 = fluent::NamedType<int32_t, struct Int32, fluent::Addable>;
struct S_Int32 { int32_t v; };
S_Int32 operator+(S_Int32 lhs, S_Int32 rhs)
{
return { lhs.v + rhs.v };
}
void vectorAddNT(NT_Int32* dst, const NT_Int32* src1, const NT_Int32* src2, int N)
{
for (int i = 0; i < N; ++i)
dst[i] = src1[i] + src2[i];
}
void vectorAddS(S_Int32* dst, const S_Int32* src1, const S_Int32* src2, int N)
{
for (int i = 0; i < N; ++i)
dst[i] = src1[i] + src2[i];
}
void vectorAddi32(int32_t* dst, const int32_t* src1, const int32_t* src2, int N)
{
for (int i = 0; i < N; ++i)
dst[i] = src1[i] + src2[i];
} Unter Clang und GCC ist alles in Ordnung:Der generierte Code ist für alle drei Funktionen gleich, und SSE2-Anweisungen werden verwendet, um die Ganzzahlen zu laden, hinzuzufügen und zu speichern.
Leider sind die Ergebnisse unter VS2017 alles andere als herausragend. Während der generierte Code für arithmetische Typen und Strukturen beide SSE2-Anweisungen verwendet, NamedType scheint die Vektorisierung zu hemmen. Das gleiche Verhalten kann beobachtet werden, wenn get() wird direkt anstelle von Addable verwendet Können. Dies ist bei der Verwendung von NamedType zu beachten mit großen Datenfeldern.
Auch VS2017 enttäuscht auf unerwartete Weise. Die Größe von NT_Int32 ist 4 Bytes auf allen Plattformen, mit allen Compilern, wie es sein sollte. Sobald jedoch ein zweiter Skill zum NamedType hinzugefügt wird , zum Beispiel Subtractable , wird die Größe des Typs 8 Bytes! Dies gilt auch für andere Rechenarten. Ersetzen von int32_t im NamedType alias mit double ergibt eine Größe von 8 Bytes für einen Skill, aber 16 Bytes sobald ein zweiter Skill hinzugefügt wird.
Ist es eine fehlende leere Basisklassenoptimierung in VS2017? Eine solche Pessimierung ergibt einen speicherineffizienten, Cache-unfreundlichen Code. Hoffen wir, dass zukünftige Versionen von VS2017 besser abschneiden.
BEARBEITEN:Wie redditer fernzeit betonte, ist die Optimierung der leeren Basisklasse standardmäßig deaktiviert, wenn Mehrfachvererbung in Visual Studio verwendet wird. Bei Verwendung des __declspec(empty_bases)-Attributs generiert Visual Studio dasselbe Klassenlayout wie Clang und GCC. Das Attribut wurde dem NamedType hinzugefügt Implementierung, um das Problem zu beheben.
Kompilierungszeit
Gegen Templates wird oft kritisiert, dass sie die Kompilierung verlangsamen. Könnte es Auswirkungen auf NamedType haben ? Andererseits ist da der gesamte Code für NamedType als projektextern angesehen wird, kann es zu einem vorkompilierten Header hinzugefügt werden, was bedeutet, dass es nur einmal von der Festplatte gelesen und geparst wird.
Die Verwendung einer Struktur als starker Typ mit Include-Dateien für Skills führt nicht zu der Vorlagenstrafe, erfordert jedoch das Lesen von der Festplatte und das erneute Analysieren der Skill-Dateien. Vorkompilierte Header können nicht für die Skill-Dateien verwendet werden, da sie sich jedes Mal ändern, wenn sie eingefügt werden. Die Struktur kann jedoch vorwärts deklariert werden, eine nette Compilation-Firewall, die NamedType kann nicht verwendet werden, da Typaliase nicht vorwärts deklariert werden können.
Um die Kompilierungszeit zu testen, habe ich ein Projekt mit 8 starken Typen erstellt, die jeweils in einer eigenen Header-Datei enthalten sind, und 8 einfachen Algorithmen, die jeweils einen starken Typ verwenden und sowohl eine Header-Datei als auch eine Implementierungsdatei haben. Eine Hauptdatei enthält dann alle Algorithmus-Header, instanziiert die starken Typen und ruft die Funktionen einzeln auf.
Die Kompilierungszeit wurde in Visual Studio 2017 (Version 15.5.7) mit der sehr nützlichen VSColorOutput-Erweiterung gemessen (probieren Sie es aus!). Standardkompilierungsoptionen für eine Windows-Konsolenanwendung wurden verwendet. Für jede Konfiguration wurden 5 aufeinanderfolgende Kompilierungen durchgeführt und die mittlere Zeit berechnet. Folglich sind dies keine „kalten“ Zeiten, Caching beeinflusst die Ergebnisse.
Zwei Szenarien wurden in Betracht gezogen:die vollständige Neuerstellung, typisch für Baumaschinen, und die inkrementelle Einzeldatei-Erstellung, typisch für die innere Entwicklungsschleife.
32-Bit- und 64-Bit-Konfigurationen ergaben keinen signifikanten Unterschied in der Kompilierungszeit, daher wird unten der Durchschnitt der beiden angegeben. Dies gilt auch für Debug- und Release-Konfigurationen (sofern nicht anders angegeben). Alle Zeiten sind in Sekunden angegeben, mit einer Schwankungsbreite von etwa ± 0,1 s.
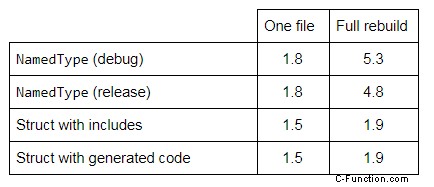
Tabelle 1:Kompilierungszeit in Sekunden verschiedener starker Typisierungsstrategien ohne vorkompilierte Header.
Ein erster Blick auf die Ergebnisse in Tabelle 1 könnte zu voreiligen Schlussfolgerungen führen. NamedType erscheint langsamer, aber seine Kompilierungszeit kann durch die Verwendung von vorkompilierten Headern stark reduziert werden. Außerdem haben die anderen Strategien einen unfairen Vorteil:Sie enthalten keine Standard-Header. NamedType enthält vier davon:type_traits , functional , memory und iostream (meistens um die verschiedenen Skills umzusetzen). In den meisten realen Projekten würden diese Header ebenfalls enthalten sein, wahrscheinlich in vorkompilierten Headern, um eine Verlangsamung der Kompilierungszeit zu vermeiden.
Es ist auch erwähnenswert, dass NamedType bringt derzeit alle Skills in den gleichen Header. Vermutlich könnte das Einfügen von Skill-Headern bei Bedarf die Kompilierungszeit in einigen Anwendungen verkürzen.
Um ein besseres Bild zu erhalten, wurden vorkompilierte Header verwendet, um die Ergebnisse in Tabelle 2 unten zu generieren:
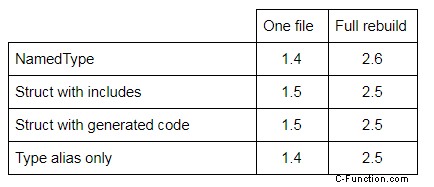
Tabelle 2:Kompilierungszeit in Sekunden verschiedener starker Typisierungsstrategien mit vorkompilierten Headern.
Ach, viel schöner! Es ist riskant, diese Ergebnisse auf größere reale Projekte zu extrapolieren, aber sie sind ermutigend und unterstützen die Idee, dass starke Typisierung eine Nullkosten-Abstraktion ist, mit vernachlässigbarer Auswirkung auf die Kompilierungszeit.
Schlussfolgerung
Mein Ziel ist nicht um Sie davon zu überzeugen, dass die Verwendung von Strukturen als starke Typen besser ist als die Verwendung von NamedType . Vielmehr ist starke Typisierung so nützlich, dass Sie Alternativen haben sollten wenn NamedType aus irgendeinem Grund nicht zu Ihnen passt, während wir darauf warten, dass eine undurchsichtige Typdefinition Teil des C++-Standards wird.
Eine einfach anzuwendende Alternative besteht darin, Strukturen als starke Typen zu verwenden . Es bietet die meisten von NamedType Funktionalität und Typsicherheit, während es für unerfahrene C++-Programmierer – und einige Compiler – einfacher zu verstehen ist.
Wenn Sie Fragen oder Kommentare haben, würde ich mich freuen, sie zu lesen! Posten Sie sie unten oder kontaktieren Sie mich auf Twitter.
Verwandte Artikel:
- Starke Typen für starke Schnittstellen
- Gute Nachrichten:Starke Typen sind (meistens) kostenlos in C++