Dieser Artikel konzentriert sich hauptsächlich auf die am häufigsten gestellten und die neuesten aktualisierten C#-Interviewfragen, die in den meisten aktuellen C#-Interviews vorkommen.
Wenn Sie nach „C#-Interviewfragen“ oder „erweiterten C#-Interviewfragen“ suchen, dann sind Sie hier genau richtig. Zuvor habe ich eine Liste mit C-Interviewfragen, C++-Interviewfragen und vielem mehr erstellt, die vielen Leuten gefallen. Ich habe die Antwort erhalten, eine Liste mit C#-Interviewfragen für erfahrene und unerfahrene Entwickler zu erstellen. Hier habe ich also versucht, eine Sammlung von „C#-scharfen Interviewfragen mit Antwort“ zu erstellen, die Ihr Interviewer stellen könnte. Ich hoffe, diese Cis-Interviewfragen mit Antwort sind hilfreich.
F) Was ist C#?
C# ist eine objektorientierte, typsichere Computerprogrammiersprache. Es wurde von Microsoft unter der Leitung von Anders Hejlsberg und seinem Team im Rahmen der .Net-Initiative entwickelt und von der European Computer Manufacturers Association (ECMA) und der International Standards Organization (ISO) genehmigt.
C# ausgesprochen als „Cis “ und vom .Net-Framework kompiliert, um Microsoft Intermediate Language zu generieren. C# ist Java syntaktisch sehr ähnlich und ist einfach für Benutzer, die Kenntnisse in C, C++ oder Java haben.
Es kann verwendet werden, um mit nur einer Programmiersprache alle Arten von Software zu entwickeln, die auf verschiedene Plattformen abzielen, einschließlich Windows, Web und Mobile. Wir können sagen, dass C# eine der beliebtesten Programmiersprachen der Welt ist und von vielen Softwareentwicklern verwendet wird, um alle Arten von Software zu erstellen.
F) Was ist ein Objekt?
Ein Objekt ist das Grundkonzept der objektorientierten Programmiersprache. Es ist eine Instanz einer Klasse, über die wir auf die Methoden und Attribute dieser Klasse zugreifen. Das Schlüsselwort „Neu“ wird verwendet, um ein Objekt zu erstellen. Eine Klasse, die ein Objekt im Speicher erstellt, enthält die Informationen über die Methoden, Variablen und das Verhalten dieser Klasse.
F) Was sind C#-Attribute und ihre Bedeutung?
C# bietet Entwicklern eine Möglichkeit, deklarative Tags für bestimmte Entitäten zu definieren, z. Klasse, Methode usw. werden als Attribute bezeichnet. Die Informationen des Attributs können zur Laufzeit mit Reflection abgerufen werden.
F) Was bedeutet Instantiierung?
Der Vorgang des Erstellens eines Objekts wird als Instanziierung bezeichnet. Unter Verwendung der Blueprint-Analogie ist eine Klasse ein Blueprint und ein Objekt ein Gebäude, das aus diesem Blueprint erstellt wurde.
F) Wie werden Sie zwischen einer Klasse und einer Struktur unterscheiden?
In .NET gibt es zwei Kategorien von Typen, Referenztypen und Werttypen. Obwohl sowohl Klasse als auch Struktur benutzerdefinierte Datentypen sind, unterscheiden sie sich in mehreren grundlegenden Punkten. Eine Klasse ist ein Referenztyp und Struct ist ein Werttyp.
Der allgemeine Unterschied besteht darin, dass ein Referenztyp auf dem Heap lebt und ein Werttyp inline lebt, das heißt, wo auch immer Ihre Variable oder Ihr Feld definiert ist.
Während die Struktur Vererbung und Polymorphie nicht unterstützt, bietet die Klasse Unterstützung für beides. Eine Klasse kann von einem abstrakten Typ sein, eine Struktur jedoch nicht.
Alle Mitglieder einer Klasse sind standardmäßig privat, während Mitglieder einer Struktur standardmäßig öffentlich sind. Eine weitere Unterscheidung zwischen Klasse und Struktur basiert auf der Speicherverwaltung. Ersteres unterstützt die Garbage-Collection, letzteres nicht.
F) Was ist der Unterschied zwischen public, static und void?
öffentlich: Auf öffentlich deklarierte Variablen oder Methoden kann überall in der Anwendung zugegriffen werden.
statisch: Auf statisch deklarierte Variablen oder Methoden kann global zugegriffen werden, ohne dass eine Instanz der Klasse erstellt wird. Ein statisches Mitglied ist standardmäßig nicht global zugänglich, es hängt von der Art des verwendeten geänderten Zugriffs ab. Der Compiler speichert die Adresse der Methode als Einstiegspunkt und verwendet diese Informationen, um mit der Ausführung zu beginnen, bevor Objekte erstellt werden.
nichtig: Ein void ist eine Art Modifikator, der besagt, dass die Methode oder Variable keinen Wert zurückgibt.
F) Was ist ein Multicast-Delegierter?
Ein Delegat, dem mehrere Handler zugewiesen sind, wird als Multicast-Delegat bezeichnet. Jeder Handler ist einer Methode zugeordnet.
F) Wie berechne ich das Alter einer Person in C#?
Sie können Ihr Alter mit dem folgenden C#-Programm berechnen.
// C# program for age calculator
using System;
class CALAGE
{
public static void CalculateAge(DateTime DayOfBirth)
{
var dt = DateTime.Now;
var years = new DateTime(DateTime.Now.Subtract(DayOfBirth).Ticks).Year - 1;
var pastYear = DayOfBirth.AddYears(years);
var months = 0;
for ( int i = 1; i <= 12; i++)
{
if (pastYear.AddMonths(i) == dt)
{
months = i;
}
else if (pastYear.AddMonths(i) >= dt)
{
months = i - 1;
break;
}
}
var days = dt.Subtract(pastYear.AddMonths(months)).Days;
Console.WriteLine(string.Format("It's been {0} years, {1} months, and {2} days since your birthday", years,months, days));
}
// driver code to check the above function
public static void Main()
{
DateTime dob = Convert.ToDateTime("1989/04/27");
CalculateAge(dob);
}
}
F) Was ist der Unterschied zwischen öffentlichen statischen, öffentlichen und statischen Methoden?
öffentlich: public an sich bedeutet, dass dies ein instanzbasiertes Element ist, auf das externe Aufrufer zugreifen können (diejenigen, die Zugriff auf den Typ selbst haben).
statisch: static an sich bedeutet, dass der Member nicht instanzbasiert ist. Sie können es aufrufen, ohne eine bestimmte Instanz (oder sogar überhaupt eine Instanz) zu benötigen. Ohne Barrierefreiheitsqualifizierer wird angenommen, dass es sich nicht um ein öffentliches Element handelt, sodass das Mitglied für externe Anrufer nicht zugänglich ist.
öffentliche Statik: public static ist eine statische Methode, auf die externe Aufrufer zugreifen können.
F) Was ist eine virtuelle Methode in C#?
Eine virtuelle Methode ist eine Methode, die in abgeleiteten Klassen neu definiert werden kann. Eine virtuelle Methode hat eine Implementierung in einer Basisklasse sowie eine abgeleitete Klasse. Es wird verwendet, wenn die grundlegende Funktionalität einer Methode dieselbe ist, aber manchmal mehr Funktionalität in der abgeleiteten Klasse benötigt wird. In der Basisklasse wird eine virtuelle Methode erstellt, die in der abgeleiteten Klasse überschrieben werden kann. Wir erstellen eine virtuelle Methode in der Basisklasse mit dem Schlüsselwort virtual und diese Methode wird in der abgeleiteten Klasse mit dem Schlüsselwort override überschrieben.
Wenn eine Methode als virtuelle Methode in einer Basisklasse deklariert wird, kann diese Methode in einer Basisklasse definiert werden, und es ist optional, dass die abgeleitete Klasse diese Methode überschreibt. Die überschreibende Methode stellt auch mehr als eine Form für eine Methode bereit. Daher ist es auch ein Beispiel für Polymorphismus.
Wenn eine Methode als virtuelle Methode in einer Basisklasse deklariert wird und diese Methode dieselbe Definition in einer abgeleiteten Klasse hat, muss sie in der abgeleiteten Klasse nicht überschrieben werden. Aber wenn eine virtuelle Methode eine andere Definition in der Basisklasse und der abgeleiteten Klasse hat, muss sie in der abgeleiteten Klasse überschrieben werden.
Wenn eine virtuelle Methode aufgerufen wird, wird der Laufzeittyp des Objekts auf einen überschreibenden Member überprüft. Das überschreibende Mitglied in der am meisten abgeleiteten Klasse wird aufgerufen, was das ursprüngliche Mitglied sein könnte, wenn keine abgeleitete Klasse das Mitglied überschrieben hat.
Virtuelle Methode:
- Standardmäßig sind Methoden nicht virtuell. Wir können keine nicht-virtuelle Methode überschreiben.
- Wir können den virtuellen Modifikator nicht mit statischen, abstrakten, privaten oder außer Kraft setzenden Modifikatoren verwenden.
F) Nennen Sie die grundlegenden OOP-Konzepte?
Es gibt vier grundlegende OOP-Konzepte (Object Oriented Programming), die wie folgt aufgelistet sind:
- Vererbung- Schon mal von diesem Dialog von Verwandten gehört „Du siehst genauso aus wie dein Vater/deine Mutter“, der Grund dafür heißt „Erbe“. Aus dem Aspekt der Programmierung bedeutet dies im Allgemeinen „Vererbung oder Übertragung von Merkmalen von der Eltern- auf die Kindklasse ohne Änderung“. Die neue Klasse heißt derived/child Klasse und diejenige, von der sie abgeleitet ist, wird als Elternteil/Basis bezeichnet Klasse.
- Polymorphismus- Sie alle müssen GPS zum Navigieren der Route verwendet haben. Ist es nicht erstaunlich, wie viele verschiedene Routen Sie je nach Verkehr für dasselbe Ziel finden, aus Programmiersicht wird dies als „Polymorphismus“ bezeichnet. Es ist eine solche OOP-Methodik, bei der eine Aufgabe auf verschiedene Arten ausgeführt werden kann. Einfach ausgedrückt ist es eine Eigenschaft eines Objekts, die es ihm ermöglicht, mehrere Formen anzunehmen.
- Kapselung- In einer rohen Form bedeutet Kapselung im Grunde das Zusammenbinden von Daten in einer einzigen Klasse. Auf eine Klasse sollte nicht direkt zugegriffen werden, sondern ein Unterstrich vorangestellt werden.
- Abstraktion- Angenommen, Sie haben eine Kinokarte bei bookmyshow über Net Banking oder einen anderen Vorgang gebucht. Sie wissen nicht, wie der Pin generiert wird oder wie die Verifizierung durchgeführt wird. Dies wird vom Programmieraspekt aus als „Abstraktion“ bezeichnet. Es bedeutet im Grunde, dass Sie nur die Implementierungsdetails eines bestimmten Prozesses anzeigen und die Details vor dem Benutzer verbergen. Es wird verwendet, um komplexe Probleme zu vereinfachen, indem für das Problem geeignete Klassen modelliert werden. Eine abstrakte Klasse kann nicht instanziiert werden, was einfach bedeutet, dass Sie keine Objekte für diesen Klassentyp erstellen können. Es kann nur zum Vererben der Funktionalitäten verwendet werden.
F) Vergleichen Sie virtuelle Methoden und abstrakte Methoden.
Jede virtuelle Methode muss über eine Standardimplementierung verfügen und kann in der abgeleiteten Klasse mit dem Schlüsselwort override überschrieben werden. Im Gegensatz dazu hat eine abstrakte Methode keine Implementierung und befindet sich in der abstrakten Klasse. Die abgeleitete Klasse muss die abstrakte Methode implementieren. Obwohl es nicht notwendig ist, können wir hier ein Überschreibungsschlüsselwort verwenden.
public abstract class E
{
public abstract void AbstractMethod(int i);
public virtual void VirtualMethod(int i)
{
// Default implementation which can be overridden by subclasses.
}
}
public class D : E
{
public override void AbstractMethod(int i)
{
// You HAVE to override this method
}
public override void VirtualMethod(int i)
{
// You are allowed to override this method.
}
}
F) Was sind Namespaces in C#?
Die Verwendung von Namespaces dient der Organisation großer Codeprojekte. Der am häufigsten verwendete Namespace in C# ist System. Namensräume werden mit dem Schlüsselwort namespace erstellt. Es ist möglich, einen Namensraum in einem anderen zu verwenden, bekannt als verschachtelte Namensräume.
F) Ist jede abstrakte Funktion in C# im Allgemeinen virtuell?
Ja, wenn eine Instanzmethodendeklaration einen abstrakten Modifikator enthält, wird diese Methode als abstrakte Methode bezeichnet. Obwohl eine abstrakte Methode implizit auch eine virtuelle Methode ist, kann sie den Modifikator virtual.
nicht haben
F) Was sind E/A-Klassen in C#? Definieren Sie einige der am häufigsten verwendeten.
Der System.IO-Namespace in C# besteht aus mehreren Klassen, die zum Ausführen verschiedener Dateioperationen verwendet werden, z. B. Erstellen, Löschen, Schließen und Öffnen. Einige der am häufigsten verwendeten I/O-Klassen in C# sind:
File – Manipulates a file Path – Performs operations related to some path information StreamReader – Reads characters from a stream StreamWriter – Writes characters to a stream StringReader – Reads a string buffer StringWriter – Writes a string buffer
F) Was ist der Unterschied zwischen SessionState und ViewState?
Es gibt die folgenden Unterschiede zwischen dem Sitzungsstatus und dem ViewState.
- Sitzungsstatus wird auf dem Server gespeichert, ViewState wird auf der Seite gespeichert.
- Ein wichtiger Punkt ist, dass der ViewState zwischen Client und Server auf und ab wandert, aber der SessionState auf dem Server bleibt.
- Der Sitzungsstatus wird normalerweise nach einer gewissen Zeit der Inaktivität des Benutzers gelöscht (keine Anfrage mit der Sitzungs-ID in den Anfrage-Cookies).
- Der Ansichtsstatus wird bei nachfolgenden Beiträgen in einem verborgenen Feld zurückgepostet.
F) Was ist der Unterschied zwischen einer Methode und einer Funktion?
Hier gebe ich eine vereinfachte Erklärung, ignoriere Probleme des Geltungsbereichs usw.
Eine Funktion ist ein Stück Code, das mit Namen aufgerufen wird. Es können Daten übergeben werden, mit denen gearbeitet werden soll (d. h. die Parameter) und optional Daten zurückgeben (der Rückgabewert). Alle Daten, die an eine Funktion übergeben werden, werden explizit übergeben.
Eine Methode ist ein Stück Code, das mit einem Namen aufgerufen wird, der einem Objekt zugeordnet ist. In den meisten Punkten ist es mit einer Funktion identisch, abgesehen von zwei wesentlichen Unterschieden:
Einer Methode wird implizit das Objekt übergeben, für das sie aufgerufen wurde.
Eine Methode kann mit Daten arbeiten, die in der Klasse enthalten sind (denken Sie daran, dass ein Objekt eine Instanz einer Klasse ist – die Klasse ist die Definition, die Objekt ist eine Instanz dieser Daten).
F) Was ist der Unterschied zwischen einer abstrakten Funktion und einer virtuellen Funktion?
Abstrakte Funktion:
Eine abstrakte Funktion kann keine Funktionalität haben. Sie sagen im Grunde, dass jede untergeordnete Klasse ihre eigene Version dieser Methode bereitstellen MUSS, aber sie ist zu allgemein, um auch nur zu versuchen, sie in der übergeordneten Klasse zu implementieren.
Virtuelle Funktion:
Eine virtuelle Funktion sagt im Grunde:Schauen Sie, hier ist die Funktionalität, die für die untergeordnete Klasse gut genug sein kann oder nicht. Wenn es also gut genug ist, verwenden Sie diese Methode, wenn nicht, überschreiben Sie mich und stellen Sie Ihre eigene Funktionalität bereit.
F)Was ist eine Schnittstellenklasse? Geben Sie ein Beispiel dafür
Eine Schnittstelle ist eine abstrakte Klasse, die nur öffentliche abstrakte Methoden hat, und die Methoden haben nur die Deklaration und nicht die Definition. Diese abstrakten Methoden müssen in den geerbten Klassen implementiert werden.
Es gibt nur wenige Eigenschaften der Schnittstellenklasse,
- Schnittstellen geben an, was eine Klasse tun muss und nicht wie.
- Schnittstellen können keine privaten Mitglieder haben.
- Standardmäßig sind alle Mitglieder von Interface öffentlich und abstrakt.
- Die Schnittstelle wird immer mit Hilfe des Schlüsselworts ‚interface‘ definiert.
- Eine Schnittstelle kann keine Felder enthalten, da sie eine bestimmte Implementierung von Daten darstellen.
- Mehrfachvererbungen sind mit Hilfe von Interfaces möglich, aber nicht mit Klassen.
Syntax für Schnittstellendeklaration:
interface <interface_name >
{
// declare Events
// declare indexers
// declare methods
// declare properties
}
Syntax für die Implementierung der Schnittstelle:
class class_name : interface_name
Beispiel-Beispielcode,
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace DemoApplication
{
interface ISampleInterface
{
void SetTutorial(int pID, string pName);
String GetTutorial();
}
class ImplementationClass : ISampleInterface
{
protected int TutorialID;
protected string TutorialName;
public void SetTutorial(int pID, string pName)
{
TutorialID = pID;
TutorialName = pName;
}
public String GetTutorial()
{
return TutorialName;
}
static void Main(string[] args)
{
ImplementationClass pTutor = new ImplementationClass ();
pTutor.SetTutorial(1,"C# interview Questions by Aticleworld.com");
Console.WriteLine(pTutor.GetTutorial());
Console.ReadKey();
}
}
}
F) Was ist der Vorteil der Interface-Klasse?
Es gibt die folgenden Vorteile der Schnittstelle.
- Es wird verwendet, um eine lose Kopplung zu erreichen.
- Es wird verwendet, um eine vollständige Abstraktion zu erreichen.
- Um eine komponentenbasierte Programmierung zu erreichen
- Um Mehrfachvererbung und Abstraktion zu erreichen.
- Schnittstellen fügen Anwendungen eine Plug-and-Play-ähnliche Architektur hinzu.
F) Erklären Sie den Prozess der Vererbung einer Klasse in eine andere Klasse?
Doppelpunkt wird als Vererbungsoperator in C# verwendet. Platzieren Sie den Doppelpunkt und den Klassennamen.
public class Derivedclass: childclass
F) Was ist der Unterschied zwischen einer Schnittstelle und einer abstrakten Klasse?
Schnittstellen haben alle Methoden, die nur eine Deklaration, aber keine Definition haben. In einer abstrakten Klasse können wir einige konkrete Methoden haben. In einer Schnittstellenklasse sind alle Methoden öffentlich. Eine abstrakte Klasse kann private Methoden haben.
Es gibt einige Unterschiede zwischen einer Schnittstelle und einer abstrakten Klasse, die ich zum leichteren Vergleich in einer Tabelle zusammengestellt habe:
| ABSTRAKT-KLASSE | SCHNITTSTELLE |
|---|---|
| Es enthält sowohl einen Deklarations- als auch einen Definitionsteil. | Es enthält nur einen Deklarationsteil. |
| Mehrere Vererbungen werden von einer abstrakten Klasse nicht erreicht. | Mehrere Vererbungen werden durch eine Schnittstelle erreicht. |
| Es enthält einen Konstruktor. | Es enthält keinen Konstruktor. |
| Es kann statische Elemente enthalten. | Es enthält keine statischen Mitglieder. |
| Es kann verschiedene Arten von Zugriffsmodifikatoren wie öffentlich, privat, geschützt usw. enthalten. | Es enthält nur den öffentlichen Zugriffsmodifikator, weil alles in der Schnittstelle öffentlich ist. |
| Die Leistung einer abstrakten Klasse ist schnell. | Die Leistung der Schnittstelle ist langsam, weil es Zeit braucht, um die eigentliche Methode in der entsprechenden Klasse zu suchen. |
| Es wird verwendet, um die Kernidentität der Klasse zu implementieren. | Es wird verwendet, um die peripheren Fähigkeiten der Klasse zu implementieren. |
| Eine Klasse kann nur eine abstrakte Klasse verwenden. | Eine Klasse kann mehrere Schnittstellen verwenden. |
| Wenn viele Implementierungen von der gleichen Art sind und ein gemeinsames Verhalten verwenden, dann ist es besser, eine abstrakte Klasse zu verwenden. | Wenn viele Implementierungen nur Methoden teilen, dann ist es besser, Interface zu verwenden. |
| Eine abstrakte Klasse kann Methoden, Felder, Konstanten usw. enthalten | Eine Schnittstelle kann nur Methoden enthalten. |
| Es kann vollständig, teilweise oder nicht implementiert sein. | Es sollte vollständig implementiert werden. |
F) Was sind Zirkelverweise?
Ein Zirkelverweis ist eine Situation, in der zwei oder mehr Ressourcen voneinander abhängig sind, die Sperrbedingung verursacht und die Ressourcen unbrauchbar macht.
F) Was ist der Vorteil der abstrakten Klasse?
Die Vorteile einer abstrakten Klasse sind:
- Fähigkeit, Standardimplementierungen von Methoden anzugeben.
- Invariante Prüfung zu Funktionen hinzugefügt.
- Haben Sie etwas mehr Kontrolle darüber, wie die „Schnittstellen“-Methoden aufgerufen werden.
- Fähigkeit, verhaltensbezogene oder nicht-bezogene Schnittstellen „kostenlos“ bereitzustellen
F)Was passiert, wenn die geerbten Schnittstellen widersprüchliche Methodennamen haben?
Wenn wir mehrere Schnittstellen in derselben Klasse mit widersprüchlichen Methodennamen implementieren, müssen wir nicht alle definieren. Mit anderen Worten, wir können sagen, wenn wir Konfliktmethoden in derselben Klasse haben, können wir ihren Körper aufgrund des gleichen Namens und der gleichen Signatur nicht unabhängig in derselben Klasse implementieren. Daher müssen wir den Schnittstellennamen vor dem Methodennamen verwenden, um diese Methodenbeschlagnahme zu entfernen. Sehen wir uns ein Beispiel an:
interface testInterface1
{
void Show();
}
interface testInterface2
{
void Show();
}
class Abc: testInterface1,
testInterface2
{
void testInterface1.Show()
{
Console.WriteLine("For testInterface1 !!");
}
void testInterface2.Show()
{
Console.WriteLine("For testInterface2 !!");
}
} Sehen Sie sich nun an, wie Sie diese in einer Klasse verwenden:class Program
{
static void Main(string[] args)
{
testInterface1 obj1 = new Abc();
testInterface1 obj2 = new Abc();
obj1.Show();
obj2.Show();
Console.ReadLine();
}
} Ausgabe:
For testInterface1 !! For testInterface1 !!
F) Was ist Constructor in C#?
In C# ist ein Konstruktor eine spezielle Methode, wenn eine Klasse oder Struktur erstellt wird, wird ihr Konstruktor aufgerufen. Eine Klasse oder Struktur kann mehrere Konstruktoren haben, die unterschiedliche Argumente annehmen. Konstruktoren ermöglichen es dem Programmierer, Standardwerte festzulegen, die Instanziierung einzuschränken und Code zu schreiben, der flexibel und leicht lesbar ist.
Hinweis: Wenn Sie keinen Konstruktor für Ihre Klasse bereitstellen, erstellt C# standardmäßig einen, der das Objekt instanziiert und Mitgliedsvariablen auf die Standardwerte setzt.
Der Konstruktor in C# hat denselben Namen wie class oder struct. Unten erwähne ich einige Typenkonstruktoren, die von C# unterstützt werden.
- Standardkonstruktor.
- Parametrisierter Konstruktor.
- Konstruktor kopieren.
- Privater Konstruktor.
- Statischer Konstruktor.
Ein Beispiel für einen Konstruktor
public class PersonInfoInfo
{
private string last;
private string first;
//constructor
public PersonInfo(string lastName, string firstName)
{
last = lastName;
first = firstName;
}
// Remaining implementation of PersonInfo class.
}
F) Erklären Sie einige Punkte im Zusammenhang mit dem Konstruktor?
Es gibt einige wichtige Punkte im Zusammenhang mit dem Konstruktor, die unten erwähnt werden,
- Eine Klasse kann beliebig viele Konstruktoren haben.
- Ein Konstruktor hat keinen Rückgabetyp, nicht einmal void.
- Ein statischer Konstruktor kann kein parametrisierter Konstruktor sein.
- Der Konstruktor einer Klasse muss denselben Namen haben wie der Klassenname, in dem er sich befindet.
- Ein Konstruktor kann nicht abstrakt, final, statisch und synchronisiert sein.
- Innerhalb einer Klasse können Sie nur einen statischen Konstruktor erstellen.
- Zugriffsmodifikatoren können in der Konstruktordeklaration verwendet werden, um den Zugriff zu steuern, d. h. welche andere Klasse den Konstruktor aufrufen kann.
F) Was ist der Unterschied zwischen „is“- und „as“-Operatoren in c#?
Der Operator „is“ wird verwendet, um die Kompatibilität eines Objekts mit einem bestimmten Typ zu prüfen, und er gibt das Ergebnis als Boolean zurück.
Der „as“-Operator wird zum Umwandeln eines Objekts in einen Typ oder eine Klasse verwendet.
F) Warum können Sie den Zugänglichkeitsmodifikator für Methoden innerhalb der Schnittstelle nicht angeben?
In einer Schnittstelle haben wir virtuelle Methoden, die keine Methodendefinitionen haben. Alle Methoden sind dazu da, in der abgeleiteten Klasse überschrieben zu werden. Deshalb sind sie alle öffentlich.
F) Was sind Werttypen und Referenztypen in C#?
In C# gibt es zwei Arten von Datentypen:Werttypen und Referenztypen. Werttypvariablen enthalten ihr Objekt (oder ihre Daten) direkt. Wenn wir eine Werttypvariable in eine andere kopieren, erstellen wir tatsächlich eine Kopie des Objekts für die zweite Variable. Beide arbeiten unabhängig voneinander mit ihren Werten, Werttyp-Datentypen werden auf einem Stack gespeichert und Referenzdatentypen werden auf einem Heap gespeichert.
Zu den grundlegenden Datentypen in C# gehören int, char, bool und long, die Werttypen sind. Klassen und Sammlungen sind Referenztypen.
F) Was sind gezackte Arrays?
Ein gezacktes Array ist ein Array von Arrays, bei dem Mitglieds-Arrays unterschiedliche Größen haben können. Die Elemente des Jagged-Arrays sind Referenztypen und standardmäßig auf null initialisiert. Ein gezacktes Array kann auch mit mehrdimensionalen Arrays gemischt werden.
Syntax der gezackten Arrays:
data_type[][] Array_Name = new data_type[rows][]
In gezackten Arrays muss der Benutzer nur die Anzahl der Zeilen angeben.
F) Is-Elemente eines gezackten Arrays müssen vor ihrer Verwendung initialisiert werden.
Ja, die Elemente eines Jagged Arrays müssen vor der Verwendung initialisiert werden.
F) Warum erlaubt C# keine statischen Methoden, um eine Schnittstelle zu implementieren?
Sie können keine statischen Member für eine Schnittstelle in C# definieren. Eine Schnittstelle ist ein Vertrag für Instanzen.
F) Was verstehen Sie unter regulären Ausdrücken in C#? Schreiben Sie ein Programm, das eine Zeichenfolge mit regulären Ausdrücken durchsucht.
Ein regulärer Ausdruck ist eine Vorlage zum Abgleichen einer Reihe von Eingaben. Es kann aus Konstrukten, Zeichenliteralen und Operatoren bestehen. Regex wird zum Analysieren von Zeichenfolgen sowie zum Ersetzen der Zeichenfolge verwendet. Der folgende Code durchsucht eine Zeichenfolge „C#“ anhand des Satzes von Eingaben aus dem Spracharray mithilfe von Regex:
static void Main(strong[] args)
{
string[] languages = {“C#”, “Python”, “Java”};
foreach(string s in languages)
{
if(System.Text.RegularExpressions.Regex.IsMatch(s,“C#”))
{
Console.WriteLine(“Match found”);
}
}
}
F) Was ist der Unterschied zwischen ref- und out-Parametern?
Sowohl ref als auch out werden verwendet, um die Argumente in der Funktion zu übergeben. Der Hauptunterschied zwischen ref und out besteht darin, dass eine Variable, die Sie als out-Parameter übergeben, nicht initialisiert werden muss, aber wenn Sie sie als ref-Parameter übergeben, muss sie auf etwas gesetzt werden.
Beispiel ,
int a; Test(out a); // OK int b; Test(ref b); // Error: b should be initialized before calling the method
Es gibt einige Unterschiede zwischen einem Ref und einem Out, die ich zum leichteren Vergleich in einer Tabelle zusammengestellt habe:
| REFERENZSCHLÜSSELWORT | SCHLÜSSELWORT AUS |
|---|---|
| Die Parameter müssen initialisiert werden, bevor sie an ref übergeben werden. | Es ist nicht erforderlich, Parameter zu initialisieren, bevor sie an out übergeben werden. |
| Es ist nicht erforderlich, den Wert eines Parameters zu initialisieren, bevor zur aufrufenden Methode zurückgekehrt wird. | Es ist notwendig, den Wert eines Parameters zu initialisieren, bevor zur aufrufenden Methode zurückgekehrt wird. |
| Die Wertübergabe durch den ref-Parameter ist nützlich, wenn die aufgerufene Methode auch den Wert des übergebenen Parameters ändern muss. | Das Deklarieren von Parametern durch Parameter ist nützlich, wenn eine Methode mehrere Werte zurückgibt. |
| Wenn das Schlüsselwort ref verwendet wird, können die Daten bidirektional übertragen werden. | Wenn das Schlüsselwort out verwendet wird, werden die Daten nur unidirektional weitergegeben. |
F)Was ist der Unterschied zwischen var und dynamic in C#
var-Schlüsselwort:
Das Schlüsselwort var wurde in C# 3.0 eingeführt, und mit var deklarierte Variablen werden statisch typisiert. Hier wird der deklarierte Variablentyp zur Kompilierzeit festgelegt. Als var deklarierte Variablen sollten zum Zeitpunkt der Deklaration initialisiert werden. Anhand des zugewiesenen Werts entscheidet der Compiler über den Variablentyp. Da der Compiler den Datentyp der Variablen zur Kompilierzeit kennt, werden Fehler nur zu diesem Zeitpunkt abgefangen. Und Visual Studio 2008 und höhere Versionen zeigen IntelliSense für den Typ var.
Beispiel,
var obj "aticleworld.com";
Im obigen Satz wird obj als String behandelt
obj = 20;
In der obigen Zeile gibt der Compiler einen Fehler aus, da der Compiler bereits den Typ von obj als String festgelegt und der String-Variablen einen ganzzahligen Wert zugewiesen hat, der den Sicherheitsregeltyp verletzt.
dynamisches Schlüsselwort:
Das Schlüsselwort dynamic wurde in C# 4.0 eingeführt und mit dynamic deklarierte Variablen wurden dynamisch typisiert. Hier wird der deklarierte Variablentyp zur Laufzeit entschieden. Variablen, die als dynamisch deklariert sind, müssen den Zeitpunkt der Deklaration nicht initialisieren. Der Compiler kennt die Variable time zum Zeitpunkt des Kompilierens nicht, daher können Fehler vom Compiler während des Kompilierens nicht abgefangen werden. IntelliSense ist nicht verfügbar, da der Variablentyp zur Laufzeit entschieden wird.
Beispiel
dynamic obj = "aticleworld";
Im obigen Code wird obj als String behandelt.
obj = 20;
Der Compiler gibt keinen Fehler aus, obwohl obj dem ganzzahligen Wert zugewiesen ist. Der Compiler erstellt den Typ von obj als String und erstellt dann den Typ von obj als Ganzzahl neu, wenn wir obj einen ganzzahligen Wert zuweisen.
Wenn Sie Online-Kurse mögen, haben wir einige gute C#-Kurse von der besten Lernplattform für Sie ausgewählt.
- Erweiterte C#-Sammlungen (PluralSight, kostenlose Testversion verfügbar) .
- Sammlung von C#-Kursen (TreeHouse kostenlose Testversion verfügbar) .
F) Wozu dient die „using“-Anweisung in C#?
Der „using“-Block wird verwendet, um eine Ressource zu erhalten und zu verarbeiten und dann automatisch zu entsorgen, wenn die Ausführung des Blocks abgeschlossen ist.
In einfachen Worten:Der Grund für die using-Anweisung besteht darin, sicherzustellen, dass das Objekt gelöscht wird, sobald es den Gültigkeitsbereich verlässt, und es ist kein expliziter Code erforderlich, um dies sicherzustellen.
Beispiel ,
using (MyResource myRes = new MyResource())
{
myRes.DoSomething();
}
F) Was ist die Hauptanwendung des Keywords „using“?
Das Schlüsselwort using hat drei Hauptverwendungen:
- Die using-Anweisung definiert einen Gültigkeitsbereich, an dessen Ende ein Objekt verworfen wird.
- Die using-Direktive erstellt einen Alias für einen Namespace oder importiert Typen, die in anderen Namespaces definiert sind.
- Die Direktive using static importiert die Mitglieder einer einzelnen Klasse.
F) Was ist der Unterschied zwischen String und String in C#?
Viele C#-Programmierer fragen sich:„Was ist der Unterschied zwischen String und String?“ Grundsätzlich ist string ein Alias in C# für System.String. Technisch gesehen gibt es also keinen Unterschied.
Einfach ausgedrückt ist „String“ ein Datentyp, während „String“ eine Klasse darstellt. Was die Richtlinien betrifft, wird allgemein empfohlen, immer dann eine Zeichenfolge zu verwenden, wenn Sie auf ein Objekt verweisen.
Ein weiterer kleiner Unterschied besteht darin, dass Sie bei Verwendung der String-Klasse den System-Namespace über Ihre Datei importieren müssen, während Sie dies nicht tun müssen, wenn Sie das String-Schlüsselwort verwenden.
Beispiel
string name= "aticleworld";
F)Was ist Funktionsüberladung?
Das Überladen einer Funktion ist eine gängige Methode zur Implementierung von Polymorphismus. Es ist die Fähigkeit, eine Funktion in mehr als einer Form neu zu definieren. Ein Benutzer kann das Überladen von Funktionen implementieren, indem er zwei oder mehr Funktionen in einer Klasse mit demselben Namen definiert. C# kann die Methoden mit unterschiedlichen Methodensignaturen (Typen und Anzahl der Argumente in der Argumentliste) unterscheiden.
Hinweis: Sie können keine Funktionsdeklarationen überladen, die sich nur durch den Rückgabetyp unterscheiden.
F) Erläutern Sie einige Methoden zum Überladen von Funktionen in C#
Das Überladen von Funktionen kann durch Ändern von:
erfolgen- Die Anzahl der Parameter in zwei Funktionen.
- Die Datentypen der Parameter von Funktionen.
- Die Reihenfolge der Parameter von Funktionen.
F) Erklären Sie die Vererbung in C# anhand eines Beispiels?
Vererbung ermöglicht es uns, eine Klasse zu definieren, die alle Methoden und Attribute von einer anderen Klasse erbt. Die Klasse, die von einer anderen Klasse erbt, wird als abgeleitete Klasse oder untergeordnete Klasse bezeichnet. Die Klasse, von der wir erben, wird Elternklasse oder Basisklasse genannt.
Es gibt viele Vorteile der Vererbung in C#, also lassen Sie uns sie sehen:
- Die Vererbung ermöglicht die Wiederverwendbarkeit von Code und erleichtert das Erstellen und Verwalten einer Anwendung. So müssen wir nicht immer wieder den gleichen Code schreiben.
- Es ermöglicht uns, einer Klasse weitere Funktionen hinzuzufügen, ohne sie zu ändern.
- Es ist von Natur aus transitiv, was bedeutet, dass wenn Klasse B von einer anderen Klasse A erbt, alle Unterklassen von B automatisch von Klasse A erben würden.
- Vererbung stellt reale Beziehungen gut dar.
F) Was ist Serialisierung?
Wenn wir ein Objekt durch ein Netzwerk transportieren wollen, müssen wir das Objekt in einen Bytestrom umwandeln. Der Prozess der Umwandlung eines Objekts in einen Bytestrom wird als Serialisierung bezeichnet. Damit ein Objekt serialisierbar ist, sollte es ISerialize Interface implementieren. Deserialisierung ist der umgekehrte Prozess der Erstellung eines Objekts aus einem Bytestrom.
F) Wie kann man einer automatischen C#-Eigenschaft am besten einen Anfangswert zuweisen?
In C# 5 und früher müssen Sie dies in einem Konstruktor tun, um automatisch implementierten Eigenschaften einen Anfangswert zuzuweisen. Sehen Sie sich ein Beispiel an,
using System;
class Person
{
public Person()
{
//do anything before variable assignment
//assign initial values
Name = "Aticleworld.com";
//do anything after variable assignment
}
public string Name { get; set; }
}
class Program
{
static void Main()
{
var Person = new Person();
Console.WriteLine(Person.Name);
}
} Ausgabe:
Aticleworld.com
Seit C# 6.0 können Sie den Anfangswert inline angeben. Siehe den folgenden Code,
using System;
class Person
{
public string Name { get; set; } = "Aticleworld.com";
}
class Program
{
static void Main()
{
var Person = new Person();
Console.WriteLine(Person.Name);
}
}
Ausgabe:
Aticleworld.com
F) Listen Sie den Grund für die Verwendung der C#-Sprache auf.
Es gibt mehrere Gründe für die Verwendung von C# als Programmierplattform. Einige davon sind unten aufgeführt.
- C# ist beliebt, weil es leicht zu erlernen ist und jeder C# schnell lernen kann.
- Reichhaltige Bibliothek, Sie können fast alles bekommen.
- Es wird großartig unterstützt und es gibt viele unterstützende Plattformen.
- Komponentenorientierte Sprache.
- Verfolgt einen strukturierten Ansatz.
- Erzeugt lesbare und effiziente Programme.
- Einmal geschrieben kann auf verschiedenen Plattformen kompiliert werden.
F) Was sind benutzerdefinierte Ausnahmen?
Manchmal gibt es einige Fehler, die gemäß den Benutzeranforderungen behandelt werden müssen. Benutzerdefinierte Ausnahmen werden für sie verwendet und werden als definierte Ausnahmen verwendet.
F) Was ist verwalteter oder nicht verwalteter Code?
Verwalteter Code:
Der Code, der im .NET-Framework entwickelt wird, wird als verwalteter Code bezeichnet. Dieser Code wird direkt von CLR mit Hilfe von Managed Code Execution ausgeführt. Jede in .NET Framework geschriebene Sprache ist verwalteter Code.
Nicht verwalteter Code:
Der Code, der außerhalb des .NET-Frameworks entwickelt wird, wird als nicht verwalteter Code bezeichnet. Anwendungen, die nicht unter der Kontrolle der CLR laufen, werden als nicht verwaltet bezeichnet, und bestimmte Sprachen wie C++ können verwendet werden, um solche Anwendungen zu schreiben, die beispielsweise auf Low-Level-Funktionen des Betriebssystems zugreifen. Hintergrundkompatibilität mit dem Code von VB, ASP und COM sind Beispiele für nicht verwalteten Code.
F) Erklären Sie die Funktionen von C#?
In C# werden mehrere Features unterstützt. Einige davon sind unten aufgeführt.
- Verwendung von Konstruktoren und Destruktoren.
- Leicht zu erlernen.
- Allgemein und objektorientiert.
- Strukturierte Sprache.
- Plattformunabhängig für die Kompilierung.
- Teil des .NET-Frameworks.
- XML-Dokumentation und Indexer.
F)Was ist der Unterschied zwischen konstant und schreibgeschützt in C#?
Const ist nichts anderes als „Konstante“, eine Variable, deren Wert konstant ist, aber zur Kompilierzeit. Es ist zwingend erforderlich, ihm einen Wert zuzuweisen. Standardmäßig ist eine Konstante statisch und wir können den Wert einer konstanten Variablen nicht im gesamten Programm ändern. Readonly ist das Schlüsselwort, dessen Wert wir während der Laufzeit ändern oder zur Laufzeit zuweisen können, aber nur über den nicht statischen Konstruktor. Kurz gesagt, konstante Variablen werden zur Kompilierzeit deklariert und initialisiert. Der Wert kann nachträglich nicht mehr geändert werden. Schreibgeschützt wird nur verwendet, wenn wir den Wert zur Laufzeit zuweisen möchten.Beispiel
Wir haben eine Testklasse, in der wir zwei Variablen haben, eine ist schreibgeschützt und die andere ist eine Konstante.class Test
{
readonly int read = 10;
const int cons = 10;
public Test()
{
read = 100;
cons = 100;
}
public void Check()
{
Console.WriteLine("Read only : {0}", read);
Console.WriteLine("const : {0}", cons);
}
}
Hier habe ich versucht, den Wert beider Variablen im Konstruktor zu ändern, aber wenn ich versuche, die Konstante zu ändern, gibt es einen Fehler, ihren Wert in dem Block zu ändern, den ich zur Laufzeit aufrufen muss.
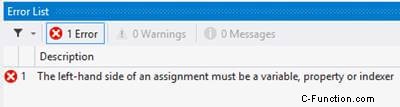
class Program
{
static void Main(string[] args)
{
Test obj = new Test();
obj.Check();
Console.ReadLine();
}
}
class Test
{
readonly int read = 10;
const int cons = 10;
public Test()
{
read = 100;
}
public void Check()
{
Console.WriteLine("Read only : {0}", read);
Console.WriteLine("const : {0}", cons);
}
} Ausgabe:
Read only : 100 const : 10
F) Können wir „diesen“ Befehl innerhalb einer statischen Methode verwenden?
Wir können „this“ nicht in einer statischen Methode verwenden, da das Schlüsselwort „this“ eine Referenz auf die aktuelle Instanz der Klasse zurückgibt, die es enthält. Statische Methoden (oder statische Member) gehören nicht zu einer bestimmten Instanz. Sie existieren, ohne eine Instanz der Klasse zu erstellen, und werden mit dem Namen einer Klasse aufgerufen, nicht per Instanz, daher können wir dieses Schlüsselwort nicht im Hauptteil statischer Methoden verwenden.
Q) Write name of the most common places to look for a Deadlock in C#.
For recognizing deadlocks, one should look for threads that get stuck on one of the following:
- .Result, .GetAwaiter().GetResult(), WaitAll(), and WaitAny() (When working with Tasks).
- Dispatcher.Invoke() (When working in WPF).
- Join() (When working with Threads).
- lock statements (In all cases).
- WaitOne() methods (When working with.
- AutoResetEvent/EventWaitHandle/Mutex/Semaphore)
Q) Explain Deadlock?
A deadlock is a situation that arises when a process isn’t able to complete it’s execution because two or more than two processes are waiting for each other to finish. This usually occurs in multi-threading. In this, a shared resource is being held up by a process and another process is waiting for the first process to get over or release it, and the thread holding the locked item is waiting for another process to complete.
Q) illustrate Race Condition?
A Race Condition occurs in a situation when two threads access the same resource and try to change it at the same time. The thread which accesses the resource first cannot be predicted. Let me take a small example where two threads X1 and X2 are trying to access the same shared resource called T. And if both threads try to write the value to T, then the last value written to T will be saved.
Q) What is Thread Pooling?
A Thread pool is a collection of threads that perform tasks without disturbing the primary thread. Once the task is completed by a thread it returns to the primary thread.
Q) Distinguish between finally and finalize blocks?
finally block is called after the execution of try and catch blocks, It is used for exception handling whether or not the exception has been caught this block of code gets executed. Generally, this block of code has a cleaner code.
The finalize method is called just before the garbage collection. Main priorities are to perform clean up operation for unmanaged code, it is automatically invoked when an instance is not subsequently called.
Q) What is Boxing and Unboxing in C#?
Boxing and unboxing are an important concept in C#. C# Type System contains three data types:Value Types (int, char, etc), Reference Types (object) and Pointer Types. Boxing and Unboxing both are used for type conversions.
Boxing:
The process of converting from a value type to a reference type is called boxing. Boxing is an implicit conversion. Here is an example of boxing in C#.
Consider the following declaration of a value-type variable:
int i= 123; // Boxing copies the value of i into object o. Object obj = i;
The result of this statement is creating an object reference o, on the stack, that references a value of the type int, on the heap. This value is a copy of the value-type value assigned to the variable i. The difference between the two variables, i and o, is illustrated in the following image of boxing conversion:
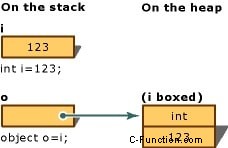
unboxing:
The process of converting from a reference type to a value type is called unboxing. Here is an example of unboxing in C#.
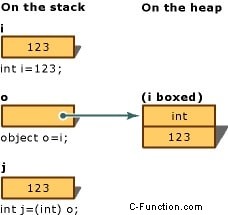
The following statements demonstrate both boxing and unboxing operations:
int i = 123; // a value type object o = i; // boxing int j = (int)o; // unboxing
Below image demonstrates the result of the above-mentioned statements:
Q) What is enum in C#?
An enum is a value type with a set of related named constants often referred to as an enumerator list. The enum keyword is used to declare an enumeration. It is a primitive data type that is user-defined.An enum type can be an integer (float, int, byte, double, etc.). But if you use it beside int it has to be cast.
An enum is used to create numeric constants in the .NET framework. All the members of the enum are enum type. There must be a numeric value for each enum type.
The default underlying type of the enumeration element is int. By default, the first enumerator has the value 0, and the value of each successive enumerator is increased by 1.
enum Dow {Sat, Sun, Mon, Tue, Wed, Thu, Fri}; Some points about enum,- Enums are enumerated data types in c#.
- Enums are not for the end-user, they are meant for developers.
- Enums are strongly typed constant. They are strongly typed, i.e. an enum of one type may not be implicitly assigned to an enum of another type even though the underlying value of their members is the same.
- Enumerations (enums) make your code much more readable and understandable.
- Enum values are fixed. Enum can be displayed as a string and processed as an integer.
- The default type is int, and the approved types are byte, sbyte, short, ushort, uint, long, and ulong.
- Every enum type automatically derives from System. Enum and thus we can use System.Enum methods on enums.
- Enums are value types and are created on the stack and not on the heap.
Q) Describe Accessibility Modifiers in C#
Access modifiers are keywords used to specify the scope of accessibility of a member of a type or the type itself. For example, a public class is accessible to the entire world, while an internal class may be accessible to the assembly only.
Q) What is the difference between ‘protected’ and ‘protected internal’?
There are the following difference between “protected” and “protected internal”.
Protected Member:
Protected members can be accessed only by code in the same class, or in a class that is derived from that class.
Hinweis: Protected members are not accessible using the object in the derived class.
Protected Internal:
Protected Internal member can be accessed by any code in the assembly in which it’s declared, or from within a derived class in another assembly.
Hinweis: Protected Internal member works as Internal within the same assembly and works as Protected for outside the assembly.
Q) How do short-circuited operators work?
In C# a short-circuit operator can be used in a bool expression only. it will return true and depending on the condition in the control statement.
If the short-circuit finds an operand that can reflect the result of the expression then it will stop checking the remaining operands and execute the condition true or false that is being reflected by the operand.
Q) What is the “volatile” keyword used for?
A volatile keyword tells the compiler that the value of a variable must never be cached as its value may change outside of the scope of the program itself. The compiler will then avoid any optimizations that may result in problems if the variable changes “outside of its control”.
Q) Why use access modifiers?
Access modifiers are an integral part of object-oriented programming. Access modifiers are used to implement the encapsulation of OOP. Access modifiers allow you to define who does or who doesn’t have access to certain features.There are 6 different types of Access Modifiers in C#:| Modifier | Description |
| öffentlich | There are no restrictions on accessing public members. |
| privat | Access is limited to within the class definition. This is the default access modifier type if none is formally specified |
| geschützt | Access is limited to within the class definition and any class that inherits from the class |
| intern | Access is limited exclusively to classes defined within the current project assembly |
| protected internal | Access is limited to the current assembly and types derived from the containing class. All members in the current project and all members in derived class can access the variables. |
| private protected | Access is limited to the containing class or types derived from the containing class within the current assembly. |
Q) Why do we use Async and Await in C#?
Processes belonging to asynchronous programming run independently of the main or other processes. In C#, using Async and Await keywords for creating asynchronous methods.
Q) Explain different states of a thread in C#?
A thread in C# can have any of the following states:
Aborted – The thread is dead but not stopped.
Running – The thread is executing.
Stopped – The thread has stopped the execution.
Suspended – The thread has been suspended.
Unstarted – The thread is created but has not started execution yet.
WaitSleepJoin – The thread calls sleep, calls wait on another object, and calls join on some other thread.
Q) What are delegates?
Delegates are the same are function pointers in C++, but the only difference is that they are type-safe, unlike function pointers. Delegates are required because they can be used to write much more generic type-safe functions.
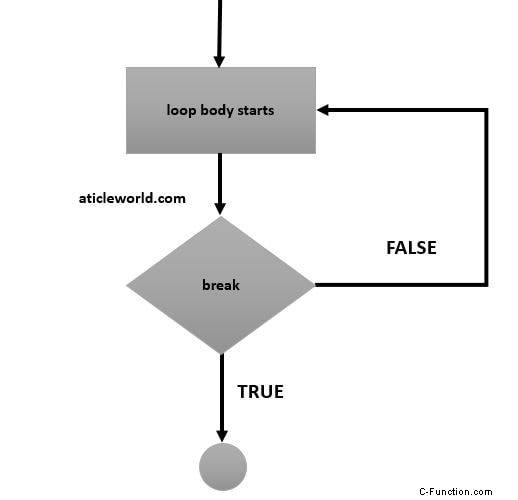
Q) What is the difference between “continue” and “break” statements in C#?
break statement:
The break statement terminates the execution of the nearest enclosing loop. After termination of the loop or switch body, control passes to the statement that follows the terminated statement.
Flowchart of break:
using System;
using System.Collections;
using System.Linq;
using System.Text;
namespace break_example
{
Class brk_stmt
{
public static void main(String[] args)
{
for (int i = 0; i <= 5; i++)
{
if (i == 4)
{
break;
}
Console.WriteLine("The number is " + i);
Console.ReadLine();
}
}
}
}
Ausgabe:
The number is 0;
The number is 1;
The number is 2;
The number is 3;
continue statement:
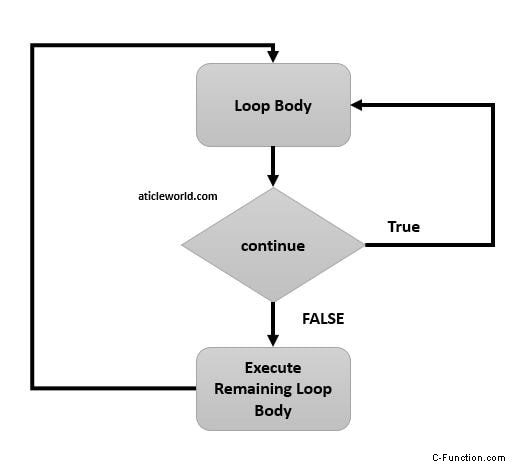
We can terminate an iteration without exiting the loop body using the continue keyword. When continue (jump statement) execute within the body of the loop, all the statements after the continue will be skipped and a new iteration will start. In other words, we can understand that continue causes a jump to the end of the loop body.
Flowchart of continue:
using System;
using System.Collections;
using System.Linq;
using System.Text;
namespace continue_example
{
Class cntnu_stmt
{
public static void main(String[] {
for (int i = 0; i <= 5; i++)
{
if (i == 4)
{
continue;
}
Console.WriteLine(“The number is "+ i);
Console.ReadLine();
}
}
}
}
Ausgabe:
The number is 1;
The number is 2;
The number is 3;
The number is 5;
Q) What can you tell us about the XSD file in C#?
XSD denotes XML Schema Definition. The XML file can have any attributes, elements, and tags if there is no XSD file associated with it. The XSD file gives a structure for the XML file, meaning that it determines what, and also the order of, the elements and properties that should be there in the XML file. Note:– During serialization of C# code, the classes are converted to XSD compliant format by the Xsd.exe tool.
Q) What are Custom Control and User Control?
Custom Controls are controls generated as compiled code (Dlls), those are easier to use and can be added to the toolbox. Developers can drag and drop controls to their web forms. Attributes can, at design time. We can easily add custom controls to Multiple Applications (If Shared Dlls). So, If they are private, then we can copy to dll to bin directory of web application and then add reference and can use them.
User Controls are very much similar to ASP include files, and are easy to create. User controls can’t be placed in the toolbox and dragged – dropped from it. They have their design and code-behind. The file extension for user controls is ascx.
Q) What are sealed classes in C#?
We create sealed classes when we want to restrict the class to be inherited. The sealed modifier used to prevent derivation from a class. If we forcefully specify a sealed class as the base class, then a compile-time error occurs.
Q) What is the difference between Array and Arraylist?
There are some differences between a ref and an out that I have arranged in a table for easier comparison:
| Array | ArrayList |
| An Array is strongly-typed. We can store only the same type of data. | ArrayList is a non-generic collection type. ArrayList’s internal Array is of the object type. So, we can store multiple types of data in ArrayList. |
| Array stores a fixed number of elements. | ArrayList is dynamic in terms of capacity. If the number of elements exceeds, ArrayList will increase to double its current size. |
| Array provides better performance than ArrayList. | If we are using a large number of ArrayList then it degrades performance because of boxing and unboxing. |
| Array uses static helper class Array which belongs to system namespace | ArrayList implements an IList interface so, it provides a method that we can use for easy implementation. |
| Array belongs to namespace System | ArrayList belongs to the namespace System.Collection |
| The Array cannot accept null. | An Array can accept null. |
Example:string[] array1=new string[5];array1[0]=”Hello”;array1[1]=”Bye”; | Example:ArrayList a1=new ArryList();a1.add(null);a1.insert(1,”hi”);a1.add(3);a1.add(8.23); |
Q) Can a private virtual method can be overridden?
No, because they are not accessible outside the class.
Q) What are Properties in C#?
C# properties are members of a C# class that provide a flexible mechanism to read, write or compute the values of private fields, in other words, by using properties, we can access private fields and set their values. Properties in C# are always public data members. C# properties use to get and set methods, also known as accessors, to access and assign values to private fields.Q) What are accessors?
The get and set portions or blocks of a property are called accessors. These are useful to restrict the accessibility of a property. The set accessor specifies that we can assign a value to a private field in a property. Without the set accessor property, it is like a read-only field. With the ‘get’ accessor we can access the value of the private field. In other words, it returns a single value. A Get accessor specifies that we can access the value of a field publically.We have three types of properties:Read/Write, ReadOnly, and write-only.Q) What are the differences between System.String and System.Text.StringBuilder classes?
System.String is immutable. When we modify the value of a string variable, then a new memory is allocated to the new value and the previous memory allocation released. System.StringBuilder was designed to have a concept of a mutable string where a variety of operations can be performed without allocating separate memory locations for the modified string.
Q) Why Properties are introduced in C#?
Properties are introduced in C# due to the below-mentioned reasons.
- If the members of a class are private then how another class in C# will be able to read, write, or compute the value that field.
- If the members of the class are public then another class may misuse that member.
Q) What is the difference between the dispose and finalize methods in C#?
The finalize and dispose methods are used to free unmanaged resources. There are some differences between a finalize and dispose that I have mentioned below.
Finalize:
- Finalize is used to free unmanaged resources that are not in use, like files, database connections in the application domain and more. These are resources held by an object before that object is destroyed.
- In the Internal process, it is called by Garbage Collector and can’t be called manual by user code or any service.
- Finalize belongs to System.Object class.
- Implement it when you have unmanaged resources in your code, and make sure that these resources are freed when the Garbage collection happens.
Dispose:
- Dispose is also used to free unmanaged resources that are not in use like files, database connections in the Application domain at any time.
- Dispose is explicitly called by manual user code.
- If we need to use the dispose method, we must implement that class via IDisposable interface.
- It belongs to IDisposable interface.
- Implement this when you are writing a custom class that will be used by other users.
Q) What are partial classes?
A partial class is only used to split the definition of a class in two or more classes in the same source code file or more than one source file. You can create a class definition in multiple files, but it will be compiled as one class at run time. Also, when you create an instance of this class, you can access all the methods from all source files with the same object.Partial Classes can be created in the same namespace. It isn’t possible to create a partial class in a different namespace. So use the “partial” keyword with all the class names that you want to bind together with the same name of a class in the same namespace.
Syntax:public partial Clas_name
{
// code
} Let’s see an example: // C# program to illustrate the problems
// with public and private members
using System;
public partial class Coords
{
private int x;
private int y;
public Coords(int x, int y)
{
this.x = x;
this.y = y;
}
}
public partial class Coords
{
public void PrintCoords()
{
Console.WriteLine("Coords: {0},{1}", x, y);
}
}
class TestCoords
{
static void Main()
{
Coords myCoords = new Coords(6, 27);
myCoords.PrintCoords();
// Keep the console window open in debug mode.
Console.WriteLine("Press any key to exit.");
Console.ReadKey();
}
}
Ausgabe:
Coords: 10,15 Press any key to exit.
Q) What’s the difference between the System.Array.CopyTo() and System.Array.Clone() ?
Using Clone() method, we create a new array object containing all the elements in the original Array and using CopyTo() method. All the elements of existing array copies into another existing array. Both methods perform a shallow copy.
Q) What are the advantages of partial classes?
Below we are mentioning a few advantages of the partial class.
- With the help of the partial class, multiple developers can work simultaneously in the same class in different files.
- With the help of a partial class concept, you can separate UI design code and business logic code so that it is easy to read and understand.
- When you were working with automatically generated code, the code can be added to the class without having to recreate the source file like in Visual studio.
- You can also maintain your application in an efficient manner by compressing large classes into small ones.
Q) What is the difference between late binding and early binding in C#?
Early Binding and Late Binding concepts belong to polymorphism in C#. Polymorphism is the feature of object-oriented programming that allows a language to use the same name in different forms. For example, a method named Add can add integers, doubles, and decimals.Polymorphism we have 2 different types to achieve that:- Compile Time also known as Early Binding or Overloading.
- Run Time is also known as Late Binding or Overriding.
Compile Time Polymorphism or Early Binding
In Compile time polymorphism or Early Binding, we will use multiple methods with the same name but different types of parameters, or maybe the number of parameters. Because of this, we can perform different-different tasks with the same method name in the same class which is also known as Method overloading. Sehen Sie sich einen Beispielcode an,
using System;
public class Addition
{
public int Add(int a, int b, int c)
{
return a + b + c;
}
public int Add(int a, int b)
{
return a + b;
}
}
class Program
{
static void Main(string[] args)
{
Addition dataClass = new Addition();
int add2 = dataClass.Add(45, 34, 67);
int add1 = dataClass.Add(23, 34);
Console.WriteLine("Add Results: {0},{1}",add1,add2);
}
}
Ausgabe:
Add Results:57,146
Run Time Polymorphism or Late Binding
Run time polymorphism is also known as late binding. In Run Time Polymorphism or Late Binding, we can use the same method names with the same signatures, which means the same type or the same number of parameters, but not in the same class because the compiler doesn’t allow for that at compile time.
Therefore, we can use that bind at run time in the derived class when a child class or derived class object will be instantiated. That’s why we call it Late Binding. Sehen Sie sich einen Beispielcode an,
using System;
class UnknownAnimal // Base class (parent)
{
public virtual void animalSound()
{
Console.WriteLine("Unknown Animal sound");
}
}
class Dog : UnknownAnimal // Derived class (child)
{
public override void animalSound()
{
Console.WriteLine("The dog says: bow wow");
}
}
class Program
{
static void Main(string[] args)
{
// Create a UnknownAnimal object
UnknownAnimal someAnimal = new UnknownAnimal();
// Create a Dog object
UnknownAnimal myDog = new Dog();
someAnimal.animalSound();
myDog.animalSound();
}
}
Ausgabe:
Unknown Animal sound
The dog says:bow wow
Q) What are the differences between IEnumerable and IQueryable?
There are some differences between an IEnumerable and an IQueryable that I have arranged in a table for easier comparison:
IEnumerable | IQueryable |
| IEnumerable belongs to System.Collections Namespace. | IQueryable belongs to System.Linq Namespace |
| It has no base interface | It derives from IEnumerable |
| does not support Lazy Loading. | Support Lazy Loading. |
| While querying data from the database, IEnumerable executes a select query on the server-side, load data in-memory on client-side and then filter data. Hence does more work and becomes slow. | While querying data from the database, IQueryable executes select queries on the server-side with all filters. Hence does less work and becomes fast. |
| It suitable for LINQ to Object and LINQ to XML queries | It is suitable for LINQ to SQL queries. |
| Doesn’t support Custom Query | Supports Custom Query using CreateQuery and Execute methods |
| Extension methods supported in IEnumerable takes functional objects. | Extension methods supported in IEnumerable takes expression objects, i.e., expression tree. |
| IEnumerable is used when querying data from in-memory collections like List, Array, etc. | IQueryable is used When querying data from out-memory (like remote database, service) collections. |
| Its best use in-memory traversal | Its best use in Paging. |
Q) What is Reflection in C#?
Reflection is the process of runtime type discovery to inspect metadata, CIL code, late binding, and self-generating code. At the run time by using reflection, we can access the same “type” information as displayed by the ildasm utility at design time. The reflection is analogous to reverse engineering in which we can break an existing *.exe or *.dll assembly to explore defined significant contents information, including methods, fields, events, and properties.You can dynamically discover the set of interfaces supported by a given type using the System.Reflection namespace.
Reflection typically is used to dump out the loaded assemblies list, their reference to inspect methods, properties etcetera. Reflection is also used in the external disassembling tools such as Reflector, Fxcop, and NUnit because .NET tools don’t need to parse the source code similar to C++.
Metadata Investigation
The following program depicts the process of reflection by creating a console-based application. This program will display the details of the fields, methods, properties, and interfaces for any type within the mscorlib.dll assembly. Before proceeding, it is mandatory to import “System.Reflection”.
Here, we are defining a number of static methods in the program class to enumerate fields, methods, and interfaces in the specified type. The static method takes a single “System.Type” parameter and returns void.
static void FieldInvestigation(Type t)
{
Console.WriteLine("*********Fields*********");
FieldInfo[] fld = t.GetFields();
foreach(FieldInfo f in fld)
{
Console.WriteLine("-->{0}", f.Name);
}
}
static void MethodInvestigation(Type t)
{
Console.WriteLine("*********Methods*********");
MethodInfo[] mth = t.GetMethods();
foreach(MethodInfo m in mth)
{
Console.WriteLine("-->{0}", m.Name);
}
}
Q) Give an example of removing an element from the queue?
The dequeue method is used to remove an element from the queue.
using System;
using System.Collections;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace TestApplication
{
class Program
{
static void Main(string[] args)
{
Queue qt = new Queue();
qt.Enqueue(1);
qt.Enqueue(2);
qt.Enqueue(3);
foreach (Object obj in qt)
{
Console.WriteLine(obj);
}
Console.WriteLine();
Console.WriteLine();
Console.WriteLine("The number of elements in the Queue " + qt.Count);
Console.WriteLine("Does the Queue contain " + qt.Contains(3));
Console.ReadKey();
}
}
}
Q) What is the difference between directcast and ctype?
DirectCast is used to convert the type of object that requires the run-time type to be the same as the specified type in DirectCast.
Ctype is used for conversion where the conversion is defined between the expression and the type.
Q) How to implement a singleton design pattern in C#?
In a singleton pattern, a class can only have one instance and provides an access point to it globally.
Beispiel
Public sealed class Singleton
{
Private static readonly Singleton _instance = new Singleton();
}
Q) What is the difference between the “throw” and “throw ex” in .NET?
“Throw” statement preserves original error stack whereas “throw ex” has the stack trace from their throw point. It is always advised to use “throw” because it provides more accurate error information.
Q) List down the commonly used types of exceptions in .net?
ArgumentNullException , ArgumentOutOfRangeException, ArithmeticException, DivideByZeroException , ArgumentException, IndexOutOfRangeException ,InvalidCastException ,InvalidOperationException , IOEndOfStreamException , NullReferenceException , OutOfMemoryException , StackOverflowException,OverflowException , etc.
Q) How can we sort the elements of the Array in descending order?
Using Sort() methods followed by Reverse() method.
Q) What is a Hashtable in C#?
A Hashtable is a collection that stores (Keys, Values) pairs. Here, the Keys are used to find the storage location and is immutable and cannot have duplicate entries in a Hashtable. The .Net Framework has provided a Hash Table class that contains all the functionality required to implement a hash table without any additional development. The hash table is a general-purpose dictionary collection. Each item within the collection is a DictionaryEntry object with two properties:a key object and a value object. These are known as Key/Value. When items are added to a hash table, a hash code is generated automatically. This code is hidden from the developer. Access to the table’s values is achieved using the key object for identification. As the items in the collection are sorted according to the hidden hash code, the items should be considered to be randomly ordered.
The Hashtable Collection:
The Base Class libraries offer a Hashtable Class that is defined in the System.Collections namespace, so you don’t have to code your own hash tables. It processes each key of the hash that you add every time and then uses the hash code to look up the element very quickly. The capacity of a hash table is the number of elements the hash table can hold. As elements are added to a hash table, the capacity is automatically increased as required through reallocation. It is an older .Net Framework type.
Declaring a Hashtable:
The Hashtable class is generally found in the namespace called System.Collections. So to execute any of the examples, we have to add using System.Collections; to the source code. The declaration for the Hashtable is:
Hashtable HT = new Hashtable ();
Q) What is Multithreading with .NET?
Multithreading allows a program to run multiple threads concurrently. This article explains how multithreading works in .NET. This article covers the entire range of threading areas from thread creation, race conditions, deadlocks, monitors, mutexes, synchronization and semaphores and so on.
The real usage of a thread is not about a single sequential thread, but rather using multiple threads in a single program. Multiple threads running at the same time and performing various tasks are referred to as Multithreading. A thread is considered to be a lightweight process because it runs within the context of a program and takes advantage of the resources allocated for that program.
A single-threaded process contains only one thread while a multithreaded process contains more than one thread for execution.
I hope above mentioned C# Interview Questions was helpful for you. If you want to add any other important C# Interview Questions, please write in the comment box or directly send an email. I will add your C# Interview Questions.
Empfohlener Beitrag:
- 100 C Interviewfragen.
- Interviewfragen zu bitweisen Operatoren in C.
- C++-Interviewfragen.
- 10 Fragen zur dynamischen Speicherzuweisung.
- Dateiverwaltung in C.
- Python-Interviewfragen.
- Linux-Interviewfragen.
- 100 eingebettete C-Interviewfragen.
References:
-
MSDN C# tutorial.
- C Sharp corner.