Das beste Tutorial, das ich für LSH gesehen habe, ist in dem Buch:Mining of Massive Datasets. Check Chapter 3 – Finding Similar Itemshttp://infolab.stanford.edu/~ullman/mmds/ch3a.pdf
Außerdem empfehle ich die folgende Folie:http://www.cs.jhu.edu/%7Evandurme/papers/VanDurmeLallACL10-slides.pdf . Das Beispiel auf der Folie hilft mir sehr beim Verständnis des Hashings für Kosinusähnlichkeit.
Ich leihe mir zwei Folien von Benjamin Van Durme &Ashwin Lall, ACL2010 und versuche, die Intuitionen der LSH-Familien für die Cosinus-Distanz ein wenig zu erklären. 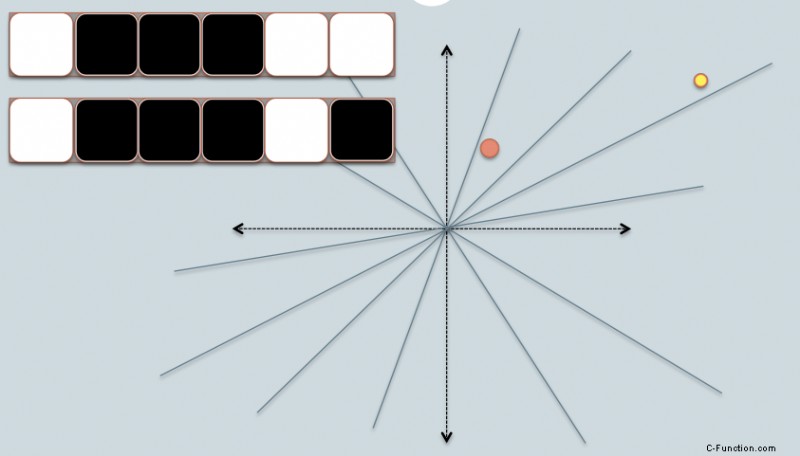
- In der Abbildung gibt es zwei Kreise mit Rot und gelb farbig, die zwei zweidimensionale Datenpunkte darstellen. Wir versuchen, ihre Kosinus-Ähnlichkeit mit LSH zu finden.
- Die grauen Linien sind einige gleichmäßig zufällig ausgewählte Ebenen.
- Je nachdem, ob sich der Datenpunkt über oder unter einer grauen Linie befindet, markieren wir dieses Verhältnis als 0/1.
- In der oberen linken Ecke befinden sich zwei Reihen mit weißen/schwarzen Quadraten, die jeweils die Signatur der beiden Datenpunkte darstellen. Jedes Quadrat entspricht einem Bit 0 (weiß) oder 1 (schwarz).
- Sobald Sie also einen Pool von Flugzeugen haben, können Sie die Datenpunkte mit ihrer jeweiligen Position zu den Flugzeugen codieren. Stellen Sie sich vor, dass, wenn wir mehr Flugzeuge im Pool haben, die in der Signatur codierte Winkeldifferenz näher an der tatsächlichen Differenz liegt. Denn nur Ebenen, die sich zwischen den beiden Punkten befinden, geben den beiden Daten unterschiedliche Bitwerte.
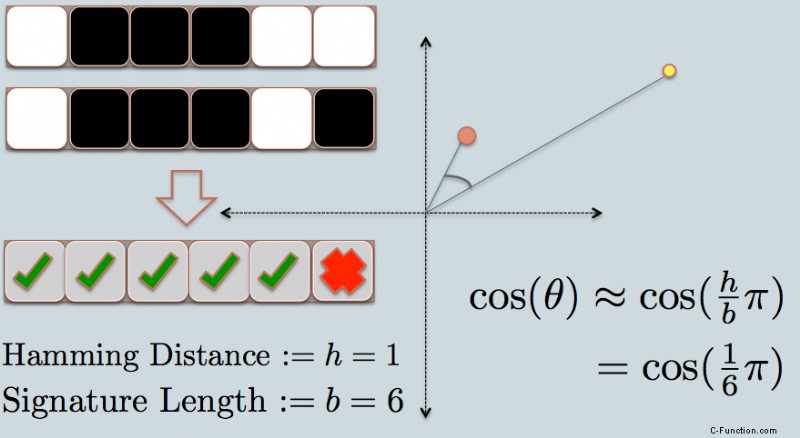
- Jetzt schauen wir uns die Signatur der beiden Datenpunkte an. Wie im Beispiel verwenden wir nur 6 Bits (Quadrate), um alle Daten darzustellen. Dies ist der LSH-Hash für die Originaldaten, die wir haben.
- Die Hamming-Distanz zwischen den beiden Hash-Werten beträgt 1, da sich ihre Signaturen nur um 1 Bit unterscheiden.
- Unter Berücksichtigung der Länge der Unterschrift können wir ihre Winkelähnlichkeit berechnen, wie in der Grafik dargestellt.
Ich habe hier einen Beispielcode (nur 50 Zeilen) in Python, der Kosinusähnlichkeit verwendet.https://gist.github.com/94a3d425009be0f94751
Tweets im Vektorraum können ein großartiges Beispiel für hochdimensionale Daten sein.
Sehen Sie sich meinen Blog-Beitrag zur Anwendung von Locality Sensitive Hashing auf Tweets an, um ähnliche Tweets zu finden.
http://micvog.com/2013/09/08/storm-first-story-detection/
Und weil ein Bild mehr als tausend Worte sagt, sehen Sie sich das Bild unten an:
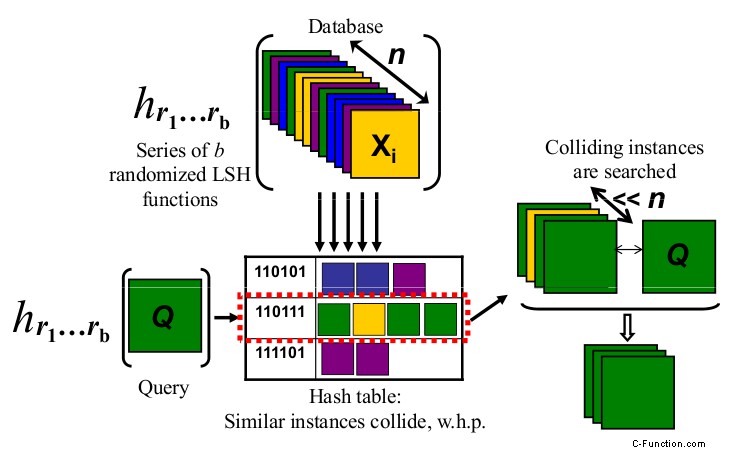 http://micvog.files.wordpress.com/2013/08/lsh1.png
http://micvog.files.wordpress.com/2013/08/lsh1.png
Hoffe es hilft.@mvogiatzis
Hier ist eine Präsentation von Stanford, die es erklärt. Es machte einen großen Unterschied für mich. In Teil zwei geht es mehr um LSH, aber in Teil eins geht es auch darum.
Ein Bild der Übersicht (Es gibt viel mehr in den Folien):
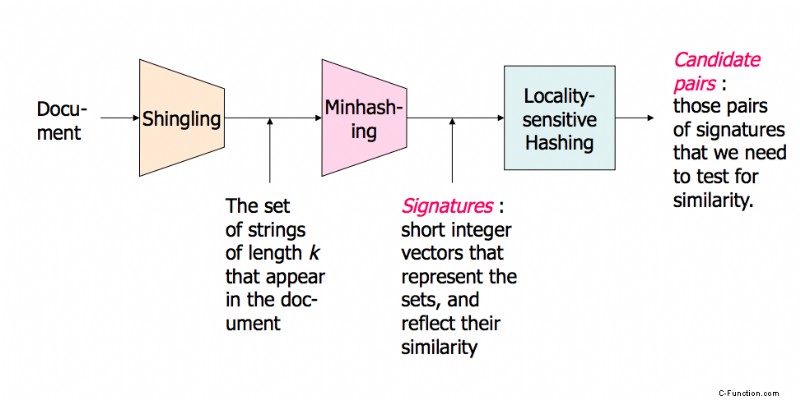
Nahe-Nachbar-Suche in hochdimensionalen Daten – Teil 1:http://www.stanford.edu/class/cs345a/slides/04-highdim.pdf
Near Neighbour Search in High Dimensional Data – Part2:http://www.stanford.edu/class/cs345a/slides/05-LSH.pdf